
Remember me
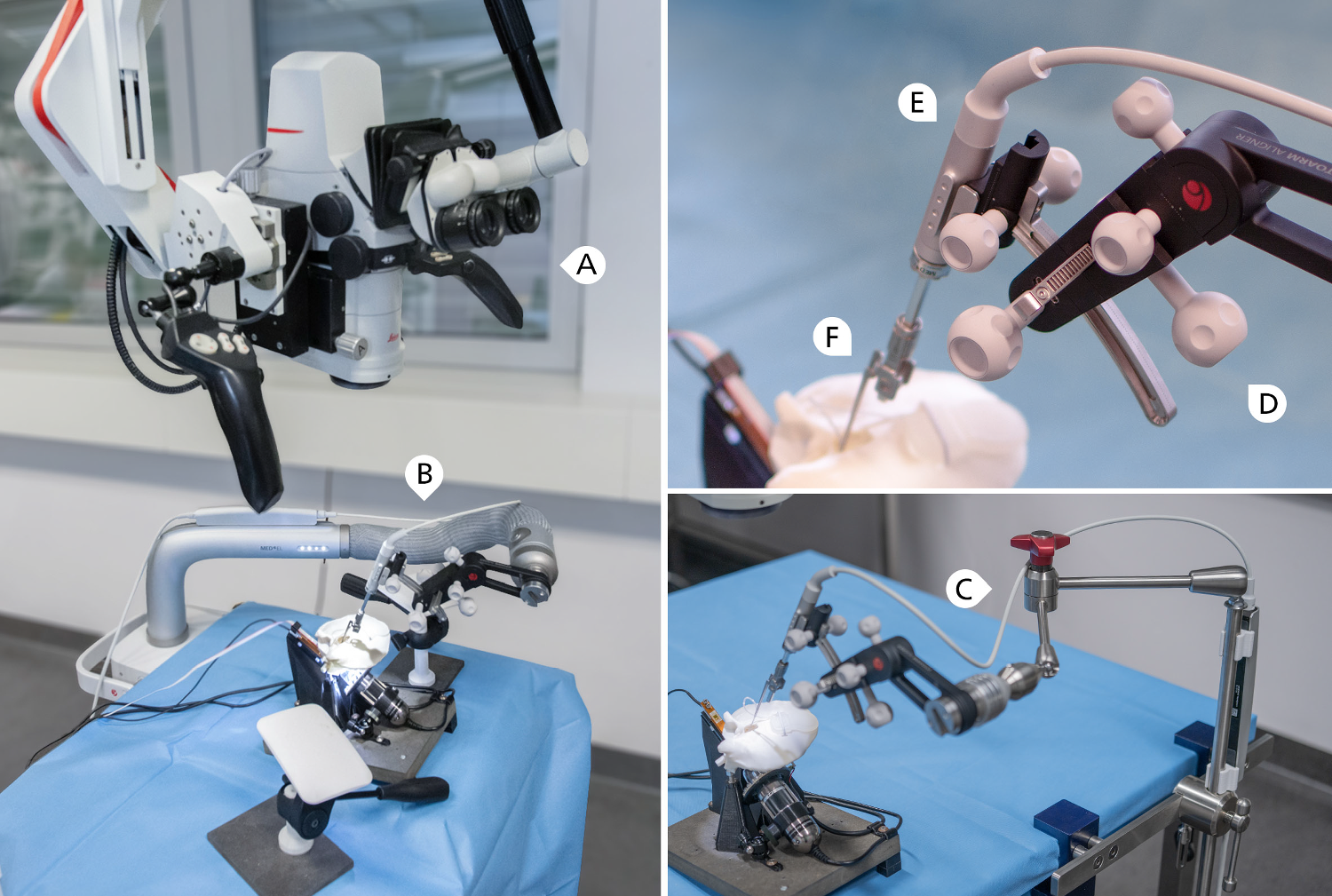


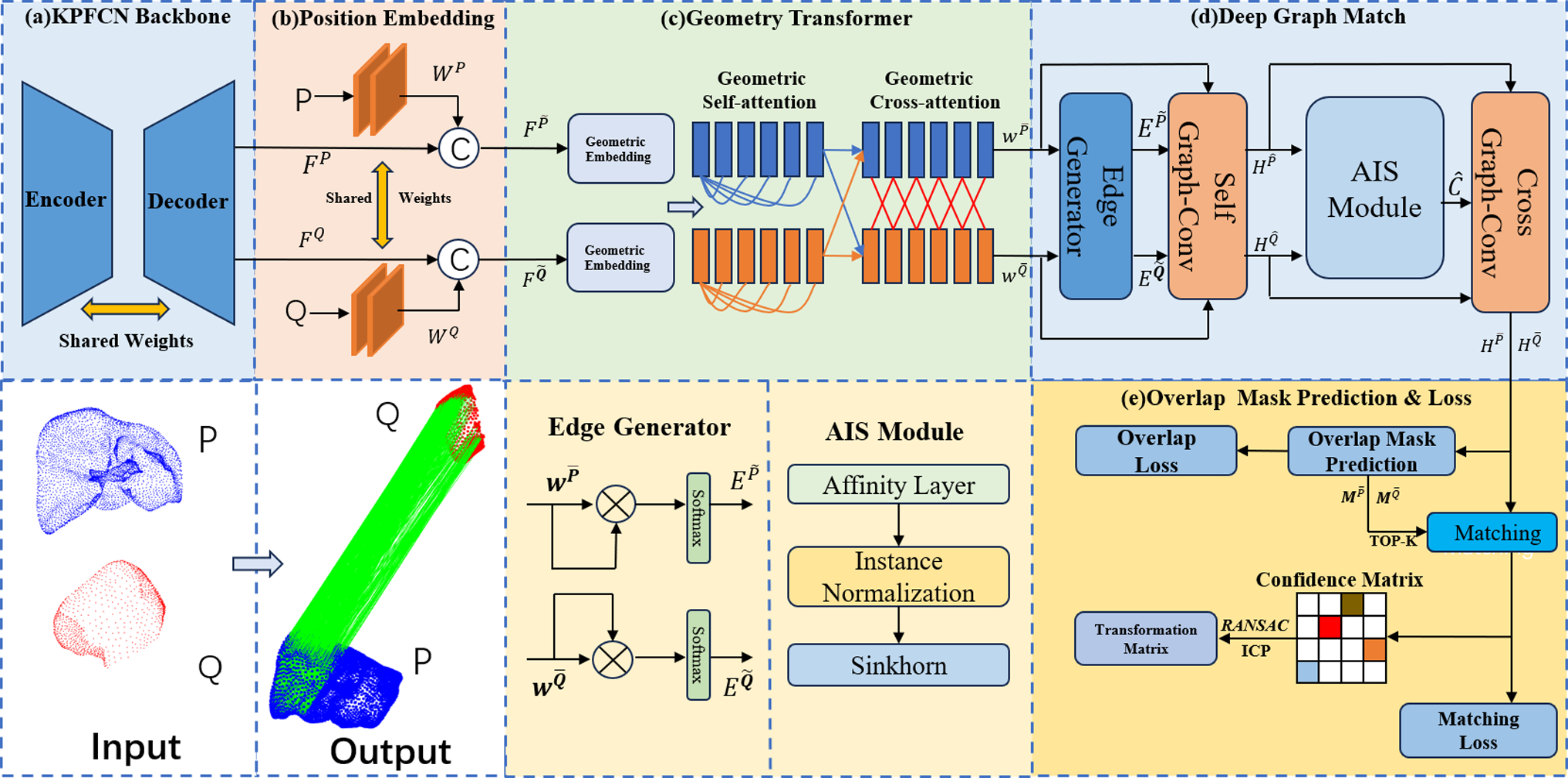

A 6G network is envisioned to consist of new concepts and technologies, such as the native integration of machine learning (ML) and artificial intelligence (AI) [6, 14]. However, it also aims to merge and integrate existing networks and architectures [14]. In contrast to previous networking generations, the interaction between application computing and networking will be much closer in 6G, leveraging not only placement algorithms in the network using ML/AI or numerical approaches, but also computational capabilities of general-purpose processors and programmable network elements via concepts such as software-defined networking (SDN) [20]. In the following, we describe such a 6G network using wireless access technology. It consists of a RAN and a core network. While the former connects the user equipment (UE) to the network, the latter is responsible for forwarding information within the Internet. In this concept, the RAN consists of several components, as shown in Fig. 1. UEs such as smartphones, robots or medical devices can physically communicate with access points (APs) using technologies such as 5G/6G base stations, LiFi, or WiFi. Furthermore, processing units placed within the network, either as a central unit (CU) or distributed unit (DU), enable the development of distributed computing scenarios for applications. DUs are typically located closer to the AP and thus to the UE, which consequently leads to reduced latency. However, DUs are usually limited in their processing capabilities. CUs, on the other hand, are usually more capable of processing computationally intensive applications but are located further away from the APs and UEs, adding considerable delays that may violate the latency requirement of time-sensitive tasks. These computing capabilities do not only allow the dynamic distribution of network functions (i.e., functions necessary for the network connection, for optimal network performance) but also parts of applications, so-called modular application functions (MAFs). MAF is a generalized term and can represent a software component of any type of application which can be executed either on local or network resources. The main advantage of this generalization is the optimized placement potential. By handling abstract MAFs with various attributes such as priority, throughput constraints, and latency constraints, the actual executed application is hidden for the placement within the network, allowing any type of application (including network functions) to be placed according to the desired optimization parameters. As an example, in Fig. 1 a robotic examination suite is shown on the patient side, which is operated by a doctor on the clinician side. In this case, several MAFs are needed to perform various tasks such as robot controlling, robot path planning, video and audio streaming. To further improve the quality of service (QoS) of such applications, the interaction between the network and MAFs can be considered during development. The advantage of using MAFs is that they can be dynamically placed and executed on different processing units depending on the current state of the network. That way, the overall performance of an application and the whole network (number of executed applications, power consumption, etc.) can be improved even further. All components are interconnected with networking switches, which can be programmable, enabling the packet forwarding behavior to be completely defined by the network operator. Finally, the RAN is connected to the Internet via a core network.
Fig. 1
Envisioned 6G RAN architecture to provide wireless connectivity for various medical use cases. It consists of access points (APs), distributed units (DUs), central units (CUs), an access path to the Internet and interconnecting network switches. The architecture allows modular application functions (MAFs), i.e., parts of medical applications, to be executed on local user equipment (UE) or on network resources
System architectureThe system architecture of our distributed robotic control is depicted in Fig. 2. It follows the network topology shown in Fig. 1 by distributing components between the patient side, clinician side, and resources within the network. The control architecture was developed using ROS 2, given its advantages in distributed setups due to the data distribution service (DDS) communication middleware [21]. The implementation uses FogROS2, a package which allows the robot programmer to delegate any ROS node to be launched on a virtual server from various cloud providers [22]. FogROS2 handles instantiating the server, setting up necessary dependencies for the robot application, and configuring a virtual private network (VPN) between the nodes to enable communication. The application was fully containerized to enable it to run remotely within a data center context and be completely platform-agnostic.
Fig. 2
Flowchart laying out the distributed control system architecture using the MAF concept. The arrows indicate data being passed from one MAF to another. The demonstration task pipeline (MAF 1-4)—as described in Section “Demonstration task"—is highlighted in red
Fig. 3
The system configurations investigated in this work. MAFs were delegated to either the local or remote computer at launch time by editing the launch file for the demonstration task
To ensure that all processes could meet the real-time requirements of the robotic controller, the configuration of the Docker container was adapted to give the containerized applications the same capabilities as if they were natively running on the host machine. To make the containerization as transparent as possible to the processes within, the container was configured to start with the SYS_NICE capability, which allows the container to change the niceness of processes, set real-time scheduling policies, CPU affinity, and other operations [23]. Furthermore, to allow the nodes in the docker container to communicate with the remote nodes hosted on the server and with the robot controller, all virtual networking performed by both Docker and the orchestrator software was disabled by configuring the container to exclusively use the host network. We used K3s, a lightweight version of Kubernetes, as the orchestration solution to manage the Docker containers due to its focus on performance and easy setup [24]. For evaluation purposes, the demonstration task described in the following section was integrated in a model setup consisting of a local, consumer-grade PC (Dell Precision 3240, Intel Core i7-10700) on the patient side and a performance-oriented remote server (Dell 3930, Intel Xeon E-2286G) as a DU. The computers were linked via a cable-based private subnetwork using a network switch (Ubiquiti Enterprise XG 24).
Demonstration taskTo provide a basis for the investigation of the robotic control infrastructure, a subset of the modular system was used as a demonstration task. The pipeline for this demonstration task is highlighted in Fig. 2. The task was chosen to include all components needed to approximate a basic robotic workflow. Furthermore, the included components were specifically selected to illustrate the diverse requirements of MAFs. In this case, the simplified workflow was defined as the autonomous placing of a diagnostic instrument, such as a stethoscope or ultrasound probe, onto the abdomen of a patient at a defined contact point. Consequently, the high-level strategy of the demonstration task was to visually identify a target point via one of the integrated cameras, and then navigate the tool center point (TCP) of the robot arm to this point in a predefined orientation.
In the first step, the camera node (MAF 1) brings images streamed from a depth camera (RealSense D405, Intel Corporation, USA) attached to the robotic arm (Panda, Franka Emika GmbH, Germany) into the ROS 2 ecosystem via the RealSense Software Development Kit (SDK) and published as a ROS 2 message [25]. While many configuration parameters exist, the default settings were used in this evaluation to keep the setup as general as possible. The computer vision (CV) node (MAF 2) is then used to identify the target point in the received images. The target for this task is an ArUco marker placed on the examination table [26]. Given their predetermined structure, the identification and pose extraction of these markers is very straightforward. In this setup, the target identification is performed using OpenCV [27]. Once the target pose is determined relative to the camera’s coordinate frame, it is converted into a pose relative to the robot base coordinate frame using the tf2 library [28]. With the target representation in the correct coordinate frame, the trajectory is generated by the path planning node (MAF 3) via the MoveIt 2 framework, an open-source robotic manipulation platform [29]. A rapidly exploring random tree planner (RRT-Connect) is used to generate and validate the trajectory, as it is fast and sufficiently accurate for an initial characterization. The final step in the demonstration task pipeline is to execute the planned trajectory via the local controller (MAF 4). Each of these steps is performed by a separate ROS 2 node, which communicates with the others via the ROS-typical publisher-subscriber model.
Evaluation procedureTo characterize the behavior of each node when running locally but also remotely, various configurations of the ROS 2 nodes were analyzed. The robot arm controller node and the RealSense camera node could only be run locally, since they interface with the hardware. This left the computer vision and path planning nodes as candidates to be analyzed since they could be offloaded to the server. The evaluation procedure was designed to evaluate every combination of these two nodes on the server and local PC. The resulting four test cases are shown in Fig. 3.
Before each evaluation run, the robot was positioned in the default ‘ready’ position. The ArUco marker target was placed directly in front of the robot base in view of the end-effector camera. The starting configuration for each trial run can be seen in Fig. 4.
Fig. 4
Starting configuration for the evaluation procedure. The robot was always started from this ‘ready’ position to simplify the evaluation workflow. The ArUco target on the table was placed so that it was in view of the hand camera from the ‘ready’ position. It was not moved during the evaluation runs
For each configuration, ten evaluation runs were performed. Each evaluation run consisted of commanding the robot to move to the target, resetting to the ‘ready’ position, and then commanding the robot to move to the target again. During each run, all network traffic of both PCs was captured via the tcpdump command line utility [30]. Simultaneously, the CPU usage was reported by the kernel and recorded every second as a percentage of the maximum performance possible by the respective computer via the nmon monitoring utility [31]. In each evaluation run, the CPU monitoring tool was launched before starting the robot task. The remote nodes for the task were then automatically started on the server during the launch process via FogROS2. This step required setup time to create the necessary container and copy the node’s source code before they were able to launch. Once the remote nodes were set up, the VPN connection was automatically established. The network monitoring was started as soon as this VPN setup was complete, just before executing the robot task. Given the large amounts of data sent between the computers, only the first 300 bytes of each packet were captured by tcpdump. This proved to be sufficient since only the Ethernet and IPv4 header of a packet are needed for the latency measurements, the former with a length of 14 bytes in most cases [32] and the latter with a length of 20 bytes [33]. The remaining data provided the ability to discriminate packets with the same headers and eliminate false matches. Upon completion of the evaluation runs, the resulting network and CPU usage data were aggregated and evaluated for each node configuration. The investigated metrics were CPU usage, throughput, and latency. The method of aggregation varied by metric to best highlight the relevant characteristics. The CPU usage was normalized to remove the impact of differing runtime on the CPU averages and plotted as bar charts. The throughput was aggregated by stacking the individual throughput plots. This allowed for an overview of the throughput usage trends over time. Additionally, a box plot of the throughput provided insight into the overall throughput distribution across the individual evaluation runs. The latency data were concatenated and then plotted as a violin plot to highlight the statistical distribution of packet delay for each configuration.
Fig. 5
CPU usage of the local PC and server for the different configurations. The red line indicates the normalized mean CPU utilization across all runs for a given configuration; a both local configuration; b, c MoveIt Remote configuration; d, e CV Remote configuration; f, g Both Remote configuration
Comments (0)