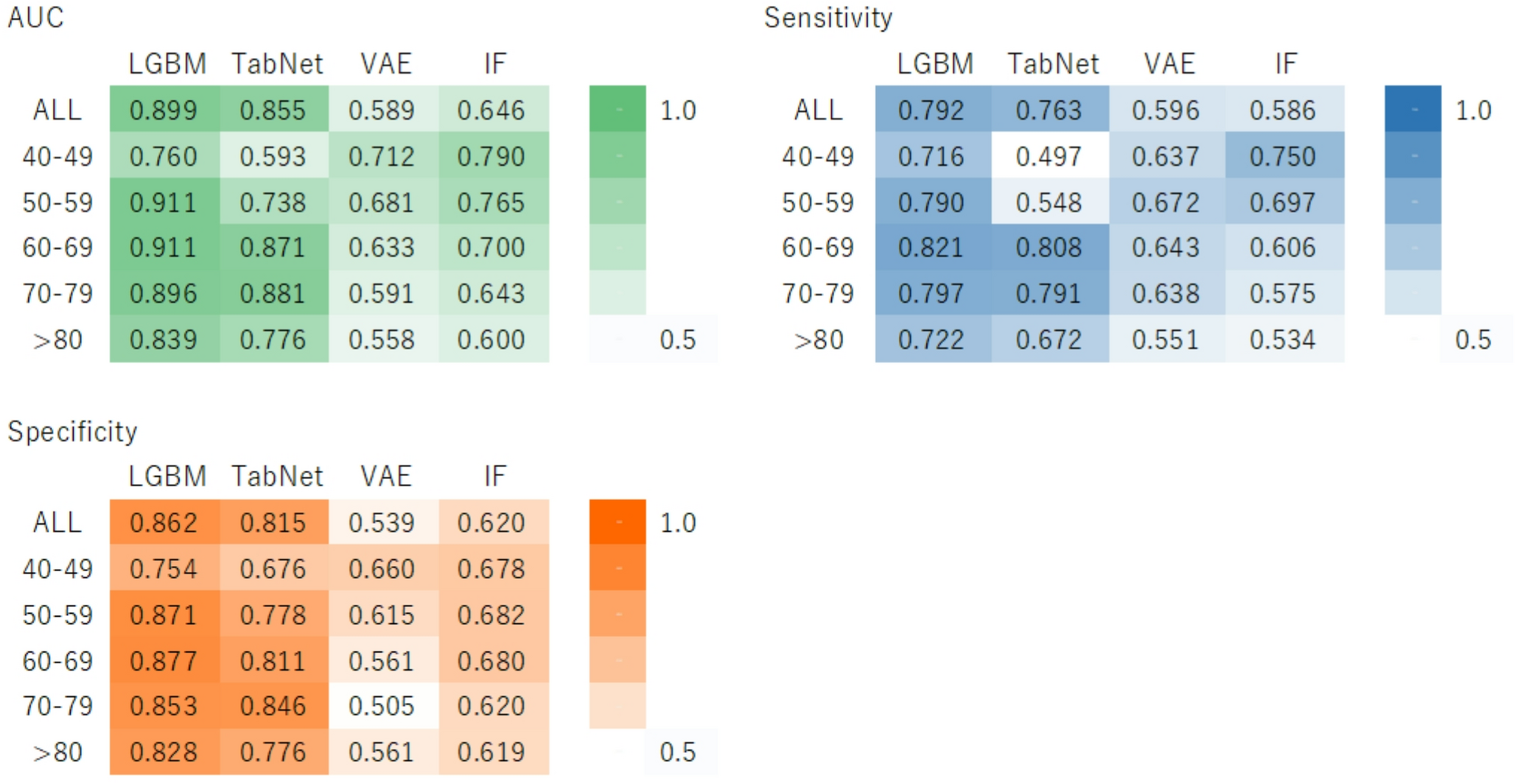
This study had three distinct strengths. The first was the development of a general model for all age groups and age-specific models, demonstrating optimized DM prediction models tailored to each age group. Notably, in the external validation, the AUC comparison revealed that the all-age LGBM model performed better for individuals within their 40s to 60s, whereas the age-specific LGBM model demonstrated superior performance for those aged 70 years and older. Second, we proposed a novel DM prediction model that incorporates not only conventional ML methods, but also deep learning and an anomaly detection approach. This approach allowed us to clarify the impact of data imbalance and sample size variation on the model’s performance. Finally, we re-evaluated the generalizability of the model across different populations, thus enhancing its reliability.
In a review by Nomura et al., the AUC for models predicting new-onset DM using ML ranged from 0.71 to 0.872 [6,7,8, 26,27,28,29,30,31]. Lai et al.., as an example, developed a five-year DM prediction model based on data from 13,309 Canadian individuals aged 18–90. In this dataset, the incidence of DM within five years was 20.9%, and the issue of imbalanced data was addressed using a class-weighting method. Their gradient boosting model achieved an AUC of 84.7%, a sensitivity of 71.6%, and a specificity of 83.7% [29].
Similarly, Ravaut et al. predicted the onset of type 2 diabetes DM (T2DM) within five years using a large dataset of 2,137,343 individuals. In their study, 1,967 individuals developed T2DM within five years, accounting for 0.092% of the total cohort. They applied the synthetic minority oversampling technique, and their gradient boosting model achieved an AUC of up to 80.26%, with a sensitivity of 71.6% [31]. These findings suggest the importance of considering not only the total number of cases, but also the data imbalance between the target disease group and the rest of the population.
However, in previous studies on DM prediction models, sensitivity typically ranged from 42.2 to 71.6%; low sensitivity is a notable issue [6]. One of the main objectives of specific health checkups in Japan is the prevention and early detection of lifestyle-related diseases, such as DM. Therefore, highly sensitive models are desirable for screening. Currently, few reports exist on DM prediction algorithms that exhibit both high AUC and sensitivity. In our developed models, using a general model for all age groups or age-specific models, we demonstrated that the sensitivity and AUC outperformed previous studies in every age group.
In particular, the LGBM model showed high predictive accuracy across multiple age groups. The LGBM model employs a gradient-boosting ML framework based on decision trees. It is generally considered to have high predictive accuracy, as it tends to form more complex decision trees than other boosting ML algorithms, leading to improved prediction performance. Additionally, the LGBM model can handle missing data and provides feature importance metrics [15]. However, there was a risk of overfitting; therefore, we conducted hyperparameter tuning and a 50-fold cross-validation to ensure model stability.
TabNet is a deep-learning model for tabular data. While it is expected to perform as well as the LGBM model on tabular data, it is designed for large and complex datasets; for smaller datasets (fewer than several thousand records), the risk of overfitting or underfitting increases [16]. Specifically, in the 40s subgroup, both internal and external validations across all age groups had datasets with fewer than several thousand records, which may have decreased predictive accuracy.
Furthermore, data imbalance poses a significant challenge not only in terms of sample size but also in terms of data distribution. Generally, during population health checkups, normal data overwhelmingly outnumber abnormal or disease-related data, causing models to learn disproportionately from the majority class. Common methods for addressing imbalanced data include under- and oversampling, which are widely used in the development of disease prediction models.
Another method of addressing imbalanced data is to treat it as an anomaly detection problem, rather than a classification problem. Anomaly detection is a data mining technique used to identify data points that behave differently from the majority of accumulated data. The IF model uses a decision-tree-based anomaly-detection method [17], whereas the VAE model is neural-network-based and uses reconstruction errors for anomaly detection [18]. The IF model is particularly effective in detecting minority class data, whereas the VAE model can handle complex data structures and nonlinear data. In our study, the IF model showed the highest AUC and sensitivity in the 40s age group for internal validation, proving that it is particularly effective for imbalanced data.
This study had several limitations. First, the external validation was limited to data from a single municipality with a sample size of approximately 15,000 individuals. Therefore, further validation across municipalities and diverse populations is required. Evaluating the generalizability of the model across different regions and cultural backgrounds is a crucial task for future research. Second, we did not develop prediction models for individuals aged < 40 years. Given the increasing incidence of DM in younger populations, it is essential to develop models that account for the risk of DM onset in younger age groups to inform future interventions. Additionally, there is a risk that cases of type 1 or slowly progressive type 1 diabetes may be misclassified as type 2 DM. Incorporating mechanisms to accurately distinguish between these different types of diabetes is necessary to further improve prediction accuracy. Third, we did not conduct a feature importance analysis stratified by age group. Although models were developed separately for each age group, differences in key predictors remain unknown. Future work should incorporate age-specific analyses (e.g., SHAP) to clarify these differences [32 Finally, participant numbers and diabetes prevalence varied greatly by age group, which may have affected performance. This imbalance, despite mitigation with stratified sampling and undersampling, should be considered when interpreting age-specific results.
In conclusion, we developed general and age-specific models for all age groups, demonstrating the effectiveness of diabetes prediction models optimized for each age group. Moreover, we propose novel prediction models that incorporate deep learning and anomaly detection in addition to traditional ML methods, with a focus on disease prevalence. Future challenges include conducting external validation on broader populations, developing prediction models for individuals under 40 years of age, and implementing mechanisms to distinguish between different types of diabetes. Addressing these challenges will enable the development of more widely applicable models that can be used in clinical practice. Therefore, the development of diagnostic prediction algorithms is becoming increasingly widespread. It is crucial to focus on the prevalence of diseases across different age groups and the quality of databases used to develop high-performance prediction models. In future prospective studies, we plan to assess the effectiveness of active health guidance using this model to prevent the onset of diabetes.


Comments (0)