
Remember me

The dataset used to develop this tool (SVPath) comprises 203 temporal bone histology sections from a normal macaque ear, M1. A separate normal macaque ear, M2, was also used to validate the SVPath tool further. Ten-micron thick slices were sequentially sectioned from the temporal bones parallel to the plane of the superior semicircular canal for both ears resulting in around 500 slices for each ear. The slices were then scanned using an Olympus microscope at × 20 magnification. Each scanned image was downsampled by 4 × and saved in the tiff image format using QuPath [14]. The average size of a single image was ~ 500 megabytes.
Deep Learning Method to Segment Stria Vascularis and Capillary BedAn overview of the proposed method used to segment and analyze the SV automatically is shown in Fig. 1. Before using any deep learning method, in the preprocessing block, blank pixels were added to the borders of each tiff image (~ 13,000 × 16,000 pixels) to create square image represented by 18,000 × 18,000 pixels (px) for image standardization. The proposed algorithm uses two neural network architectures: YOLOv8 and nnUnet. YOLOv8 is a recent modification to the original YOLO framework: an efficient object detection neural network used to extract patches of images where features are present [15]. nnUnet is an improvement on a traditional U-net: a fully convolutional neural network that can perform semantic or pixel-level segmentation of structures [16]. Each of these models is implemented with PyTorch and other Python libraries [16]. The training process for these models is described below.
Fig. 1
Overview of the method to extract stria vascularis and its associated capillaries from whole slide imaging
After the data is preprocessed into uncompressed square images, it is incorporated into the trained [YOLOv8]2, which consists of two individual YOLOv8 neural networks to extract features at the level of the WSI and then at the level of the cochlea. The uncompressed square WSI is first compressed into a 2048 × 2048 px image that is then processed in the first YOLOv8 to determine the location of the cochlea within the WSI. The location of the cochlea in this compressed image is mapped to the uncompressed square WSI and used to extract an uncompressed square region (9000 × 9000 px) centered around the cochlea. Like the initial step, this region is compressed and input into the second YOLOv8 neural network to determine the location of SV within the uncompressed region around the cochlea. From this location, 512 × 512 px patches centered around each SV are extracted and stored in a separate folder. This method overcomes the limitation of extracting small features from WSI while preserving the original uncompressed image. The 512 × 512 patches are then analyzed separately by nnUnet to extract binary masks of the SV and its associated capillary bed. These masks are stored and used in the SV Analysis Tool (SVAT) described below.
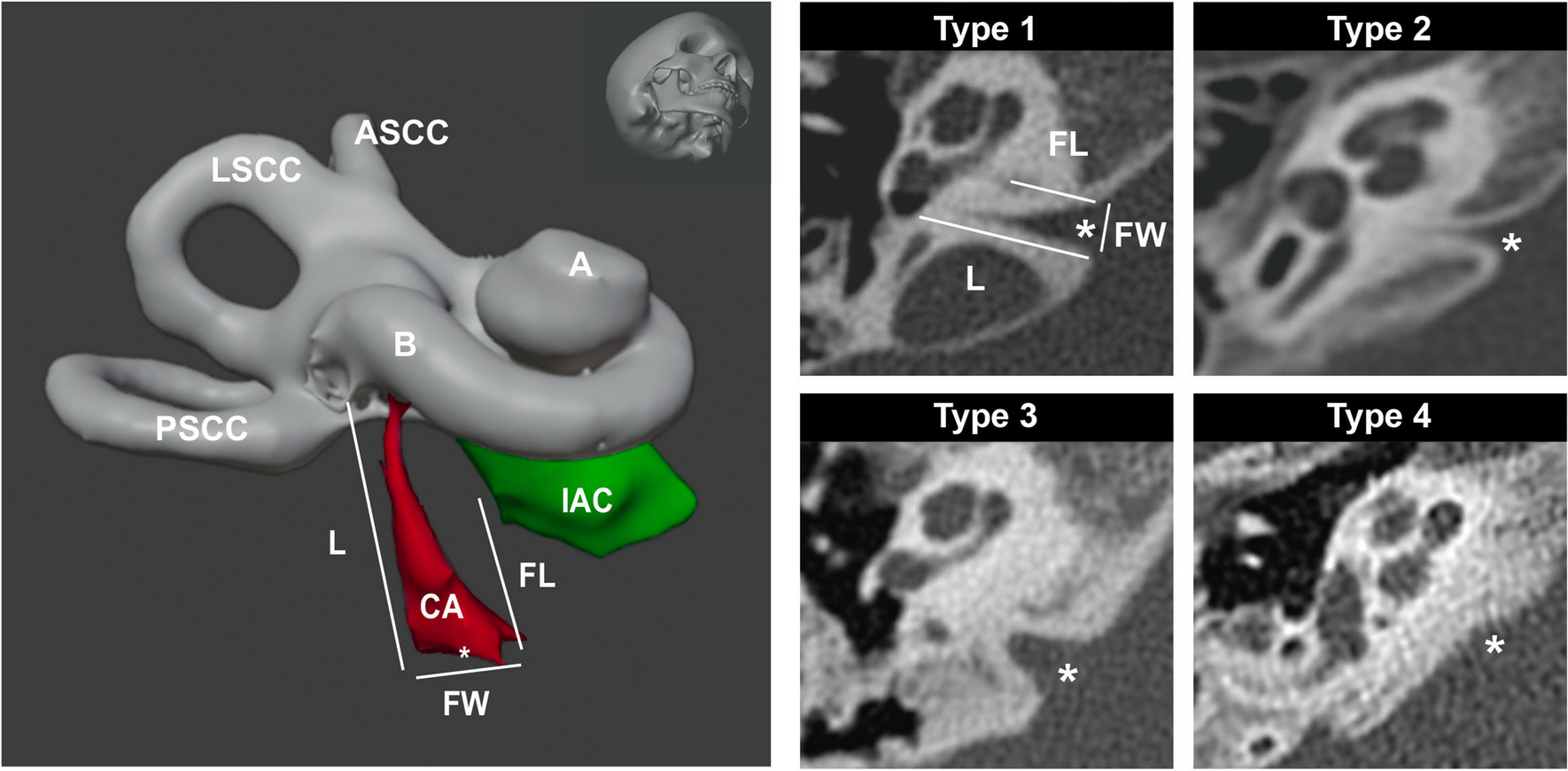
Stria Vascularis AnalysisAs part of SVPath, SVAT was developed to extract features of the SV; an overview of these features is shown in Fig. 2. As noted in other studies, the morphology of the SV is analyzed primarily by measuring its width and cross-sectional area [2, 3, 7, 10]. SVAT uses the binary mask of the SV generated from the previous step to calculate the pixel area that was later converted into micrometers [2]. Conversion from pixels to micrometers was done by correlating measurements of features within QuPath to pixels in image. The width of the SV is measured in three different ways, as shown in Fig. 3: minimum Feret diameter (w1), width along the union of the midline of the bounding box and the SV mask(w2), and average width (w3). The average width is defined by the formula below.
Fig. 2
Overview of features extracted from stria vascularis (SV). A Outline of SV; overall area and width were computed from this region. B Capillary regions in SV are highlighted; the average area of capillary in SV and total capillary area per SV were extracted. C Outline of nuclei in the SV; total number of cells per SV was extracted
Fig. 3
Width calculation from SV; w1, the minimum Feret diameter; w2, intersection of SV area and the midline of the bounding box of SV; w3, area of SV (a)/height of bounding box (h)
$$Average\; width=\frac$$
The height of the SV is computed from the bounding box around the SV mask. All units are reported in pixels, later converted into micrometers.
The binary mask of the capillary bed is processed to extract the number of capillaries found in the SV, the total area of the capillary lumen per SV, and the average area per capillary measured. The final metric reported by software is the number of nuclei found in the SV. The number of nuclei is calculated by first taking the original 512 × 512 color SV patch and performing K-means image clustering to segment the nuclei within the SV. These nuclei are then analyzed to determine the average area of a single nuclei in a patch. Then, the total nuclei area is divided by the average area of a single nuclei in the patch to estimate the total number of nuclei in each patch. This method for calculating the number of nuclei has been validated in other studies [18]. While there are some multi-nucleated, irregular cells within the SV, counting the number of nuclei can estimate the number of cells [19].
Training and Evaluation of [YOLOv8]2 and nnUnetTo train the YOLOv8 neural network for cochlea detection, a smaller random data set of 110 compressed square WSI (2048 × 2048 px) from macaque M1 was manually labeled with a bounding box around the cochlea using Roboflow, an easy-to-use machine learning platform [20]. Labeling was performed by three separate raters. Once these slides were labeled, the data was randomly partitioned into a training and validation set with an 80/20 split. Using the training subset, a PyTorch implementation of YOLOv8 neural network was trained on a virtual graphics processing unit (GPU) and evaluated on the validation set. The training was run for 30 epochs. Three performance metrics were used to assess YOLOv8:
1.Precision: Positive predictive value of the bounding box generated by neural network compared to the labeled ground truth.
2.Recall: Sensitivity of the bounding box generated by neural network compared to the labeled ground truth.
3.mAP: An average of the precision and recall per class labeled across all the images in the validation set.
Performance metrics were captured specifically for the internal validation dataset. A similar process was done for the YOLOv8 neural network for SV detection, except 78 compressed square images of the cochlea region (2048 × 2048 px) were used for the dataset, and the SV region was labeled. The performance metrics used to evaluate the Yolov8 neural network are consistent with other literature [23].
Once the SV region was extracted into a 512 × 512px patch, nnUnet was used to segment the SV and its associated capillaries. The nnUnet was trained and validated on 220 patches extracted from the M1 ear using the [YOLOv8]2 method described above. The SV and its associated capillary bed in each of these patches were manually labeled using RoboFlow. During the training process, the dataset was randomly partitioned into five folds; each fold randomly divided the 220 patches into training and validation subsets with an 80/20 split. The nnUnet was trained on each fold separately for 50 epochs. Optimizable parameters that maximize the performance of nnUnet were determined based on the individual performance of each of these folds. To evaluate nnUnet performance, two similar metrics were used:
1.Dice score (i.e., dice similarity coefficient, DSC): The overlap between the predicted segmentation and the ground truth by computing the intersection of the two masks and dividing it by the average of their areas. A higher dice score indicates better alignment between prediction and truth, with one being a perfect match.
2.Intersection over union (IoU): The ratio of the intersection to the union of the predicted and ground truth masks. An IoU score of 1 represents a perfect match.
Dice and IoU are commonly used metrics used to evaluate segmentation neural networks [24]. Both capture similar metrics; however, IoU is more significantly affected by incorrect segmentation-compared to dice scores, resulting in lower scores. In previous literature, dice values greater than 0.7 are considered acceptable segmentation performance [11]. Performance metrics were captured for the entire dataset.
External Validation on Macaque Ear M2In addition to validating this method on the M1 ear, a second normal macaque ear, M2, was used to increase the generalizability of this model. The dataset of M2 ear consisted of 7–8 WSI from the mid-modiolar region within the cochlea with approximately 20 SV. Each SV with its associated capillaries was manually labeled and compared with labels generated using the SVPath tool outlined above. Additionally, the generated labels were analyzed using the SV tool to demonstrate how this tool could be used to compare different ears.
Comments (0)