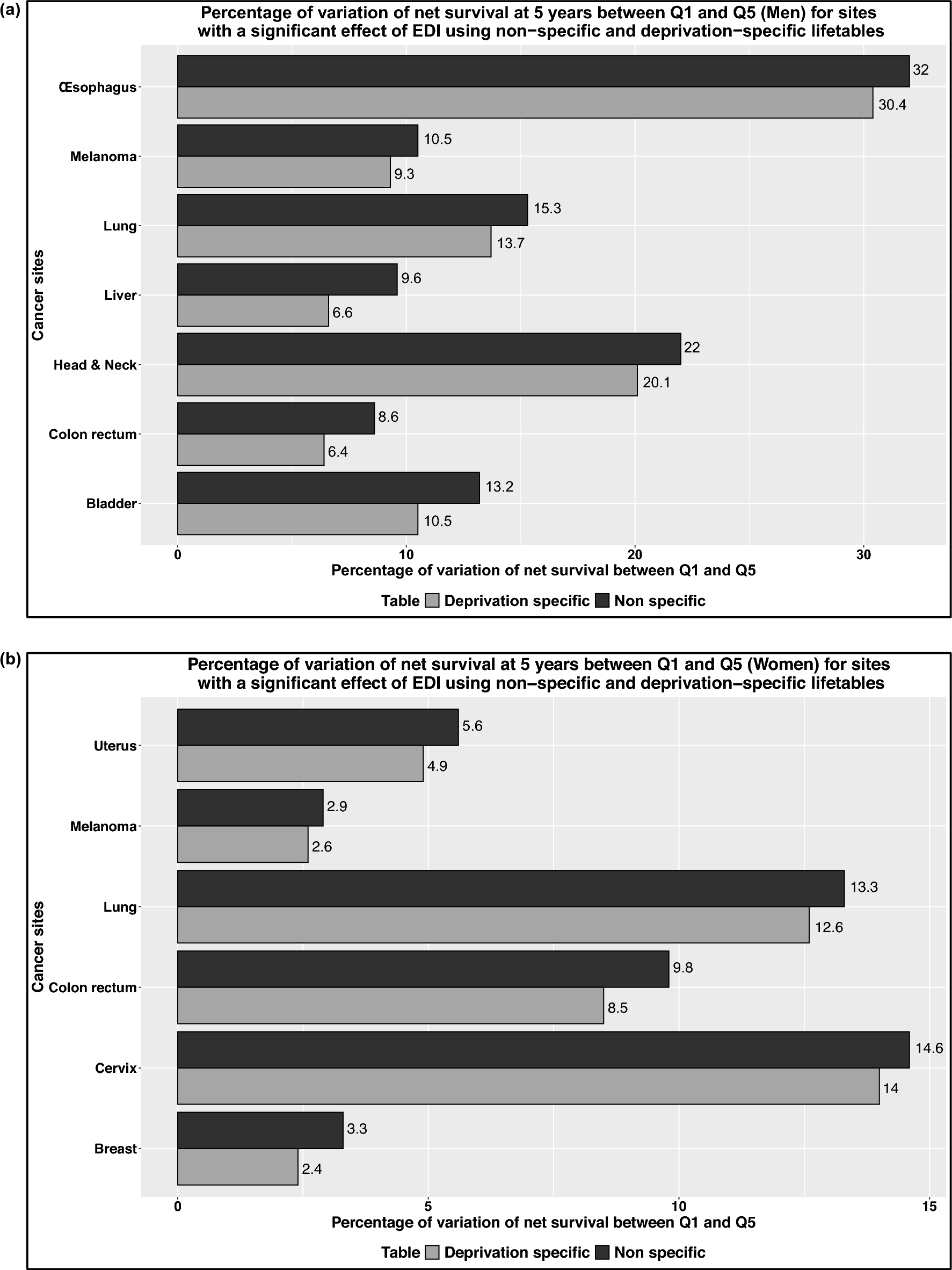
Our analysis of 385 867 abstracts on RCTs from 1975 to 2021 shows a steep increase in the number of abstracts on RCTs each year. The proportion of abstracts reporting statistical inference exclusively declaring that there is a “significant” difference between two groups has gradually and modestly decreased in favor of reporting numerical p-values, and p-thresholds along with confidence intervals. Nonetheless, confidence intervals are reported markedly less frequently than p-values. Within abstracts reporting effect-measure estimates on binary outcomes, reporting of hazard ratio estimates shows the greatest increase over time. The reporting of NNT and NNH estimates has not gained traction. The reporting of odds ratio estimates is found in about one third of all abstracts on RCTs that report effect-measure estimates on dichotomous outcomes.
A text mining project of 1.6 million PubMed abstracts and 385 000 PMC full texts of biomedical research articles published between 1990 and 2015 found that reporting of p-values (numerical or threshold, e.g. p < 0.05 or p ≤ 0.05) in abstracts has increased from 7.3% to 1990 to 15.6% in 2014 [14]. Within the group of abstracts reporting a p-value (numerical or threshold, e.g. p < 0.05 or p ≤ 0.05), the proportion of abstracts reporting a p-threshold decreased over time in favor of reporting numerical p-values [14]. Previous systematic reviews on the reporting style of statistical inference in selected major medical and epidemiological journals [7], psychiatry journals [8], cardiology journals [10], clinical pharmacology journals [9], and cancer journals [15] showed that the percentage of confidence intervals in abstracts containing statistical inference has increased, even if reporting of p-values dominates. Even in 2021, a confidence interval is reported for effect-measure estimates for binary outcomes in a minority of RCT abstracts. Thus, for the majority of RCT abstracts, readers have no immediate way to assess statistical uncertainty of effect-measure estimates. Failure to report CIs may reflect a lack of appreciation by authors, reviewers or editors for the information that the interval estimates convey.
In a review in 2008 of 193 publications in five major general medical journals of RCTs that used binary primary outcomes, OR estimates were reported in 12%. A total of 14% reported OR estimates for other outcomes or for subgroup analyses [16]. Another paper analyzed 580 publications of RCTs in the New England Journal of Medicine from 2004 to 2014. In a subset of publications where RR estimates could be calculated from reported OR estimates, the OR estimate was found to overestimate the RR estimate in 62% of cases. The overestimation was > 50% in 28 RCTs and > 100% in 13 RCTs [17]. Rombach et al., in an analysis of 200 publications on RCTs, found that only 55% of publications reported an effect-measure estimate at all [18]. One of the earliest publications to point out that the OR deviates from the RR when the risk of the outcome is substantial in at least one of the study arms was from Cornfield [19]. The assessment of how rare a condition should be depends on the tolerance regarding the approximation error. For example, if one wants the error to be no greater than 10% for the RR, the risk of the outcome should be no greater than 10% in each study arm [20]. In 2011, Knol et al. reported extreme cases of abstracts in which the OR estimate deviated considerably from the RR estimate in a RCT [16]. We found one example in which the estimated risk of the outcome was 95% in one study arm and 68% in the other [21], for a risk difference estimate of 27%. The authors did not report risk difference, however. Rather, they reported an OR estimate of 9.3. Had they reported RR instead, it would have been 0.95/0.68 = 1.4. The deviation of the OR from the RR is influenced not only by the rarity of the outcome in all treatment levels, but also by the difference in risks between the study arms. The difference between OR and RR may remain small even with high risks in the study arms as long as the risks are similar (e.g., risk in one study arm 72%, in the other study arm 70%, OR = 1.10, RR = 1.03, risk difference + 2% points). ORs in abstracts of RCTs may come from embedded case-control studies, from cross-sectional analyses (prevalence OR), or from longitudinal analyses of RCT data and may therefore have different interpretations.
Interestingly, Kolaski et al. (2023) cite work showing that authors often label their study design incompletely or inaccurately, resulting in incorrect indexing of papers in PubMed and other literature databases [22]. We used “publication types” keyworded by the National Library of Medicine in our search strategy of publications on RCTs. We also combined that with text word searches to improve recall (albeit at the expense of search precision). This may explain why our review also included case-control studies embedded in RCTs or secondary analyses for prognostic and treatment prediction models based on RCT data in some cases.
Whereas absolute effect measures gauge clinical importance and public health importance in general, relative effect measures obscure it [23, 24]. In their code of practice for the pharmaceutical industry, the Association of the British Pharmaceutical Industry (ABPI) states: “Referring only to relative risk, especially with regard to risk reduction, can make a medicine appear more effective than it actually is. In order to assess the clinical impact of an outcome, the reader also needs to know the absolute risk involved. In that regard relative risk should never be referred to without also referring to the absolute risk. Absolute risk can be referred to in isolation” [23]. Nevertheless, it remains a rarity for studies to report absolute effect measure estimates (i.e., difference measures) for binary outcomes, or to report both absolute and relative effect-measure estimates as recommended by CONSORT in 2010. In a review of 359 full papers published in general medical journals in 1989, 1992, 1995, and 1998, that reported results from RCTs and mentioned a statistically significant treatment effect, absolute effect measures were reported in 5.0% and NNT was reported in 2.2% [25].
In 2016, the American Statistical Association explicitly stated, “The widespread use of ‘statistical significance’ (generally interpreted as ‘p ≤ 0.05’) as a license for making a claim of a scientific finding (or implied truth) leads to considerable distortion of the scientific process.” [26]. More recently, the ASA provided an even stronger statement that “it is time to stop using the term ‘statistically significant’ entirely. Nor should variants such as ‘significantly different,’ ‘p < 0.05,’ and ‘nonsignificant’ survive, whether expressed in words, by asterisks in a table, or in some other way. Whether it was ever useful, a declaration of ‘statistical significance’ has today become meaningless” [27]. It remains unclear why confidence intervals around effect-measure estimates are so rarely reported in abstracts of RCTs, although the CONSORT guideline has long called for this and the ASA explicitly discourages making decisions based on statistical significance.
Our study involved the complete review of all RCT abstracts from 1975 to 2021 (385 867 abstracts) and the use of a validated text-mining algorithm that automatically detected the reporting of statistical inferences, the statistical reporting style of outcomes, and effect-measure estimates for binary disease outcomes. Nonetheless, our analysis has also several important limitations. First, we only studied abstracts of RCTs, which may not capture the reporting style of the full text. For example, based on 300 abstracts from the three leading clinical pharmacology journals from 2012 to 2016, 50% of the abstracts contained statistical inference, whereas in the full text of the same publications, 88% contained statistical inference. The proportion of reporting confidence intervals in abstracts that contained statistical inference was also lower (45%) than in the full texts of the same publications (58%) [9]. Our rationale to focus on abstracts was that (1) the reporting style in abstracts reflects the results that authors consider most noteworthy, (2) the abstract is often the only part of a publication that is read, and (3) although proper presentation and interpretation of study results is relevant throughout the manuscript, it is especially relevant in abstracts [28]. Second, our PubMed algorithm identified not only RCT abstracts that contained comparative analyses on the primary endpoint, but also post-hoc analyses of RCT data (e.g. prognostic prediction models, nested case-control studies in RCTs), and also protocols on RCTs. For this reason, we limited our analyses of the reporting style of statistical inference to abstracts that contained some statistical inference. Similarly, with regard to the reporting of effect-measure estimates for binary outcomes, we restricted our analysis to abstracts in which an effect-measure estimate for binary outcomes was present at all. Third, our text-mining algorithms were not perfect. We therefore used time-stratified random samples of abstracts to validate the algorithms. For example, the error rate of the categorization of statistical reporting style among abstracts containing statistical inference was 2.5%. The text-mining algorithm regarding the detection of effect-measure estimates of interest worked nearly perfectly.





Comments (0)