
Remember me

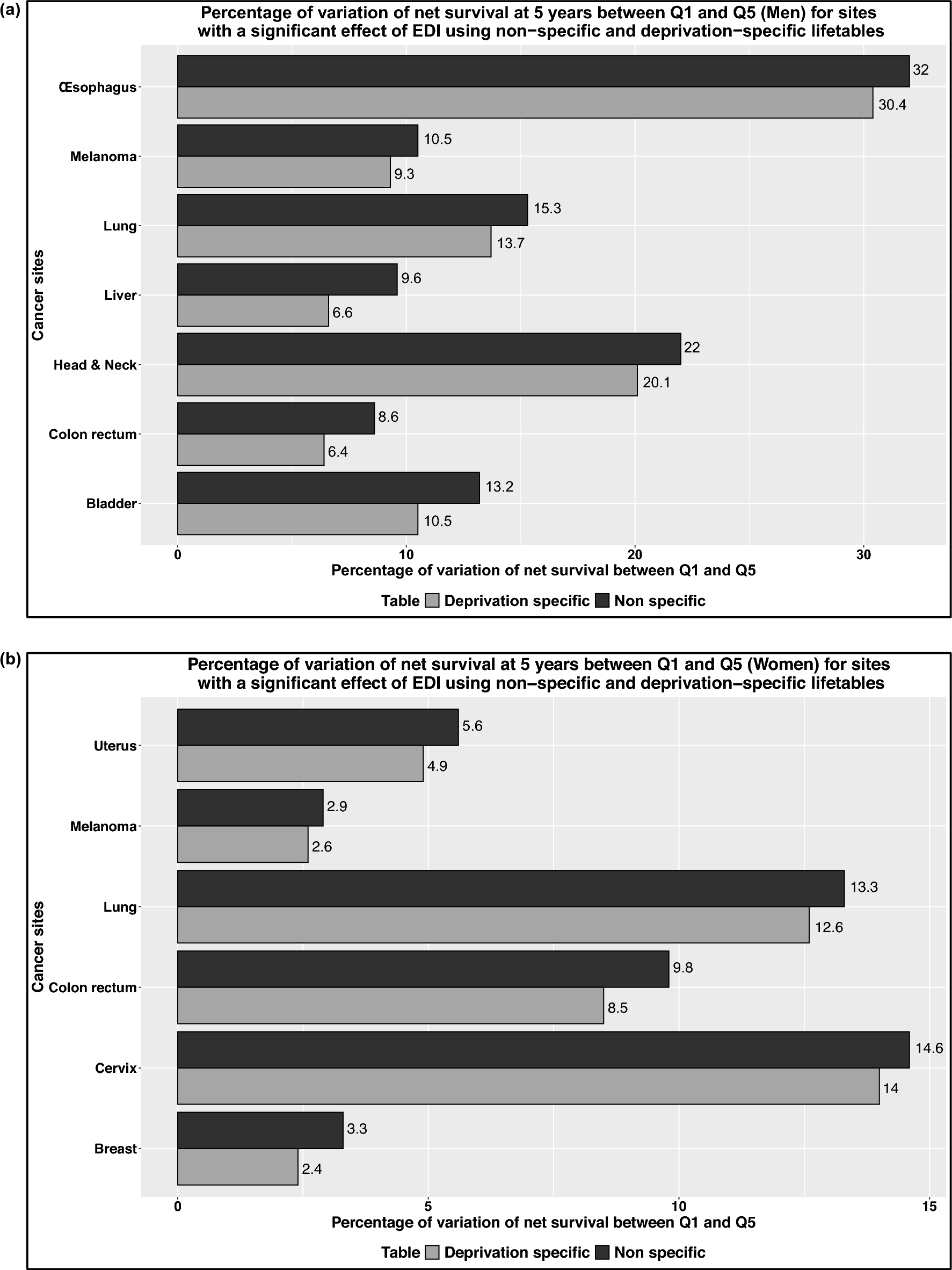



Development of the GFS survey occurred over eight distinct phases: (1) selection of core well-being and demographic questions; (2) solicitation of social, political, psychological and demographic questions from domain experts worldwide; (3) Revision of the initial survey draft based on feedback from scholars around the world representing various academic disciplines; (4) modification of question items following input from experts in multinational, multiregional and multicultural survey research; (5) survey draft refinement based on compiled input from an open invitation to comment, posted publicly and sent to numerous listservs; (6) questionnaire optimization with support from Gallup survey design specialists; (7) adaptation of items from an interviewer-administered to a self-administered survey instrument using best practices for web survey design to minimize item non-response, illogical responses and incomplete responses; and (8) confirmation by scholars in several participating countries that translations accurately captured the intended meaning of each question. Further details about the survey development process of the GFS survey can be found in [10, 11].
Content coverage of the surveyThe aspects of flourishing constitute a broad range of constructs that are related to a person’s well-being. The overall GFS survey includes distinct 109 items in total (43 items in the intake survey and an annual survey of 71 items, with five items shared by both) [11]. A core measure embedded in the survey is the Secure Flourish Index [1], which consists of 12 items that are evenly distributed across six key domains of personal flourishing (i.e., happiness & life satisfaction; physical & mental health; meaning & purpose; character & virtue; close social relationships; financial & material stability); a wide range of measures assessing domains or aspects (e.g., community, political religion, spirituality, socioeconomic factors) that intersect with human flourishing are also included in the survey. The interested reader is referred to Lomas et al. [11] for more information about the survey development process and the full set of survey items, which can also be located in the publicly available codebook (https://osf.io/cg76b).
TranslationWave 1 of the GFS includes 22 countries, namely Argentina, Australia, Brazil, Egypt, Germany, Hong Kong (S.A.R. of China), India, Indonesia, Israel, Japan, Kenya, Mexico, Nigeria, Philippines, Poland, South Africa, Spain, Sweden, Tanzania, Turkey, the United Kingdom, and the United States. The GFS survey was implemented in 36 major languages spoken across these countries, including Afrikaans, Arabic, Assamese, Bengali, Bicol, Cebuano, Chinese, English, German, Gujarati, Hausa, Hebrew, Hiligaynon, Hindi, Igbo, Iluku, Indonesian Bahasa, Japanese, Kannada, Malayalam, Marathi, Odia, Pidgin, Polish, Portuguese, Punjabi, Sotho, Spanish, Swahili, Swedish, Tamil, Telegu, Turkish, Waray, Xhosa, Yoruba, and Zulu. Further details about the countries in which specific language versions of the GFS survey were used can be found in the methodology report appendix (pp. 29–31) [9].
The survey translation process adhered to a modified TRAPD model [14], which stands for translation, review, adjudication, pretesting, and documentation. The translation process that was followed for the GFS survey included (T) a professional translator who translated the survey into the target language using a shared set of notes and guidance about the meaning of specific words, phrases, and concepts; (R) a different professional translator reviewed the translation. This reviewer identified any issues with the translated material, suggested alternative translations, and provided reasoning in English behind their decision for modifications; (A) the original translator received feedback on the disputed translations and accepted or rejected the suggestions. If they disagreed with the reviewer’s edits, the initial translator provided an explanation in English. A third-party reviewer then adjudicated the translation based on the explanation that best aligned with the research objectives; (P) local partners ran a pilot test of the entire questionnaire with at least 10 respondents per language to ensure the accuracy and quality of the translations; and (D) final translations were documented for researchers [15].
In several countries, data collection occurred using a combination of interviewer- and self-administered approaches, depending on the participant’s access to the internet and willingness to complete online surveys. To ensure translation consistency across modes of data collection, a professional translator adapted the final interviewer‑administered translation to reflect the modifications required for the self‑administered version of the survey.
Interviewer trainingAs described by Ritter et al. [9], local field partners employed over 3,000 interviewers in 19 countries to recruit and conduct the first wave of data collection (participants in Hong Kong [S.A.R. of China], Sweden, and the United States were recruited entirely via a web-based approach). Partners were selected based on experience in nationwide survey research studies. They conducted in-depth training sessions with local field staff prior to the start of data collection. Fieldwork teams were assisted by a standardized training manual to ensure consistency and structure. Interviewer training included the following topics: research ethics; protecting participants’ confidentiality; staying safe while in the field; starting the interview; reading survey questions verbatim; handling questions from participants; closed-end and open-end items; skip patterns; interviewing best practices, including probing; respondent selection; household selection and substitution (for face-to-face surveys); and quality control procedures. Field teams trained using the computer-assisted personal interview (CAPI) system for face‑to-face interviews and the computer-assisted telephone interview (CATI) system for telephone interviews, which were employed during fieldwork. These systems ease interviewer burden and facilitate accurate data capture for items such as participant selection in the household, contact data, and skip patterns.
Given the longitudinal research design, interviewer training also focused on accurately capturing the participant contact information required for future recontact. In addition to repeating contact details back to participants, interviewers were trained on double-entry of open-end contact information, which had to match before advancing to the next survey item. Local field partners also emphasized the importance of striking the right balance between friendly persistence in collecting as many forms of contact information as possible and potentially upsetting reluctant participants. Finally, interviewers learned that respondent selection on the annual survey required immediate confirmation of the participant’s name to ensure those who completed the intake survey also completed the annual survey.
Sampling design and data collectionThe GFS employed various survey methodologies to recruit participants [9]. In most countries, local field partners were guided in implementing a probability-based face‑to-face or telephone methodology to recruit panel members. Recruitment involved an intake survey that mainly gathered basic demographics and information for recontact. Shortly following recruitment, participants received invitations to participate in the annual survey via phone or online. The questions on this latter survey will appear in future yearly waves of data collection to obtain repeated measures. A high-level summary of the recruitment and data collection phases is shown in Fig. 2.
Fig. 2
Recruitment and Empanelment in the Global Flourishing Study. Note: The United States (US) sample is a subset of the existing Gallup Panel™
The geographic coverage in each country included in the GFS was the entire country, including rural areas. It represents the entire civilian, non-institutionalized population aged 18 and older. Exceptions included areas where the safety of interviewing staff was threatened, as well as scarcely populated islands and areas that interviewers could only reach by foot, animal, or small boat (although some interviewers reported taking small boats to get adequate population coverage in accordance with the sampling design). Eligibility for participation in the study required the selected participants to have access to a phone or the internet, a practical necessity to help retention. Loss of coverage due to these requirements was < 2% in each country where participants were recruited in person.
Three major sampling frames were used for recruitment in the GFS, namely a probability-based sample, a non-probability-based sample, or a combination of the two [9]. Table 1 summarizes the sampling design within each country. A probability-based sampling approach was used in Egypt, India, Indonesia, Israel, Kenya, Nigeria, Philippines, South Africa, Tanzania, Turkey, and the United States. A non-probability-based sample was recruited in some countries to supplement probability samples so that adequate coverage of population subgroups (i.e., sex, age, region) was achieved. Recruitment and empanelment for Wave 1 of the study occurred between April 2022 and December 2023 [9].
Table 1 Global flourishing study sampling summary across countries for Wave 1Data from Hong Kong (S.A.R. of China) is available in the first wave of data collection. Data from mainland China were not included in the first data release due to fieldwork delays. The first wave of fieldwork in mainland China began in February 2024, and a second wave is expected to occur in November–December 2024. All wave 1 and 2 data from mainland China will be part of the second dataset release in March 2025.
Table 2 summarizes the number of participants who were recruited by different modes in each country. While some countries relied entirely on web-based recruitment (e.g., United States), other countries exclusively used face-to-face recruitment (e.g., Israel, Kenya) or a mix of recruitment methods (e.g., Argentina, Mexico). An additional unique subsample within Nigeria was carried out representative of those without access to a landline, mobile device, or internet. An attempt was made at collecting a similar subsample in India, but implementation was ultimately not completed due to the extremely small proportion that met these requirements there. The weighting approach that was used to ensure that population representative inferences could be obtained in Nigeria is described in more detail within the Weighting and Design Effects section below.
Table 2 Sample size by mode of data collection employed in the Global Flourishing StudyProbability-based samplesFor face-to-face interviews, the selection of probability-based samples was carried out by selecting sampling units stratified by population size, urbanicity and/or geography, and clustering [9]. This complex design varied by country, leading to a different number of sampling stages depending on the country. A stratified single-state or multi-stage cluster design was employed in countries where detailed population information was available from a recent census or other reliable source. Sampling units were selected using probabilities proportional to population size for each sampling stage down to the cluster, with a fixed number of interviews completed within each cluster. Countries with more limited population information (e.g., population data only at the province or district level) utilized a stratified multi-stage cluster design. Primary sampling units (PSUs) were selected during the first sampling stage using probabilities proportional to size, and units at subsequent stages were selected using simple random sampling; no more than four clusters per PSU were used in the last stage of sampling. When a multi-stage sampling design was employed, the pre-determined clusters defined the geographic region from which households and participants were ultimately selected, where interviewers, starting from an address or structure closest the random coordinate starting point that was pre-selected by a field manager, were trained to select every third household to invoke a pseudo-random route. The interviewer randomly selected a participant within each household using the computer assisted personal interview (CAPI) system. If the randomly selected household member was unavailable for the duration of the data collection period, or unwilling to participate in the study, a different household was selected. However, if the randomly selected household member was unavailable due to being at work or out shopping, then more contact attempts were made at varying days of the week and times of day (up to three contact attempts).
For telephone interviews, the selection of participants was carried out using random-digit dialing or a nationally representative list of phone numbers [9]. When applicable, either a dual sampling frame of landline and mobile phones was used or a mobile phone only frame was used. Landline samples were stratified by region, whereas mobile phone samples were primarily stratified by mobile service providers. Brazil was the only exception in that the mobile sampling frame was stratified by region. The size of regional samples was determined to be proportional to the size of the adult population aged 18 or older, and a random participant within each household was obtained using one of the standard methods—enumeration of adults 18 or older and selecting one at random for face-to-face collection or asking for the person who had the next birthday among eligible adults 18 or older for interviews completed over telephone. Interviewers attempted contact over several different days and times, with at least five attempts at contact, to reach the intended participants to complete the interview. When successful contact was made, the telephone intake interview was aided by a computer assisted telephone interview (CATI) system, which was also used to help guide interviewers through the annual survey to maintain valid skip logic when necessary.
Data collection in the United States used the Gallup Panel™, a probability-based, nationally representative panel for which all members are recruited via address-based sampling or random-digit-dial methodology [9]. All online members of the Gallup Panel™ received up to five invitations to complete a single survey that included all intake and annual items together.
For participants from a country other than the United States who completed the intake survey as part of a probability-based sample, retention efforts to ensure completion of the annual survey involved a multipronged approach. As described above, web surveys used multiple outreach attempts across various recontact channels increased the chances that a participant received an invitation and reminders to participate in the annual survey. Receipt of the invitation is a necessary but insufficient condition for ensuring participation. Participants assigned to the annual survey received a welcome message shortly after completing the intake survey that provided more context about the study and a link to a website, which included additional information on frequently asked questions and a way to contact recruiters. For participants assigned to complete the annual survey over the telephone, interviewers received training on refusal conversion tactics. Additionally, the introduction script included a section of short responses to frequently asked questions and concerns. Interviewers applied similar cooperation tactics when attempting to recontact surveys with respondents assigned to the web survey who had not participated after the initial five-invite design. As a small token of appreciation for their time, eligible participants who completed the annual survey received a gift card or mobile top‑up worth roughly $5.
Non-probability based samplesThe samples from Hong Kong (S.A.R. of China), Japan, and Sweden relied exclusively on existing web panels for recruitment, leading to a non-probability-based sample [9]. Data collection in Hong Kong (S.A.R. of China) and Sweden recruited a non-probability sample obtained through online opt-in panels. A small proportion of the sample in Japan (\(N \approx 500\)) was drawn from a probability frame, but the sample was insufficient to project that sample to the target population.
Data collected in Hong Kong (S.A.R. of China), Japan, and Sweden were based solely on a non-probability sample, so creating true sampling weights is not possible; however, as discussed in greater detail in the Weighting and Design Effects section, for Sweden, pseudo-sampling weights based on propensity scores methods were constructed while for the other two countries a baseweight of 1 was assumed and a more detailed cross-classified population targets were used so that weighted estimates are approximately representative of the population.
Combined probability and non-probability samplesData collection in Argentina, Australia, Brazil, Germany, Mexico, Poland, Spain, and the United Kingdom consisted of a combination of two samples: (1) a probability-based sample selected with a face-to-face sampling methodology, or a phone sampling methodology or a combination of the two (both of which are described in more detail in the Probability-based samples subsection); and (2) a non-probability-based sample collected through web panels.
Data collection in Germany and the United Kingdom used high-quality, commercially available, or proprietary third-party panels put together using opt-in methods [9]. Data collection in Argentina, Brazil, Mexico, and Spain recruited directly from a proprietary affiliate network that is the foundation of many commercial panels. This network comprises media entities that offer access to internet and mobile users across the gamut of digital marketing channels, including, but not limited to, social media marketing, email, video, mobile, blogs, and display.
Quotas for age, gender, region, and education were set and monitored during fieldwork in countries that use existing web panels to ensure adequate representation of the population. Participants who were recruited from these panels completed a single, combined survey. Population coverage in Germany, United Kingdom, and Spain excluded the offline population for these countries. Probabilities samples in Latin American countries (Argentina, Brazil, Mexico) reached the offline population with the inclusion of respondents completing the annual survey via telephone surveys assisted by CATI.
Ethics and respondent confidentialityEthical approval was granted by the institutional review boards at Baylor University (IRB Reference #: 1841317) and Gallup (IRB Reference #: 2021-11-02), and all participants provided informed consent. Individuals may withdraw from participating in the study at any point. Consistent with European Union regulations, respondents from a country in this region (e.g., Germany, Spain, Sweden) can additionally request that their data be completely removed from subsequent waves of the GFS. Respondent confidentiality is maintained by giving a pseudo-random identification number that is kept separate from the data that researchers can access. A public use dataset has been created and will be publicly available in February 2025, and can be accessed by anyone submitting a pre-registration to the Center for Open Science prior to then, but this dataset excludes individual identifying information such as location (latitude and longitude are rounded to the nearest degree) and language of assessment. Individual researchers with appropriate institutional review board approval may be able to access a restricted use dataset that contain these more sensitive types of data.
Post-collection data quality evaluationEach country dataset underwent a rigorous quality assurance process by survey type (intake or annual) and mode (telephone, face-to-face, or web). Gallup’s regional directors of survey research verified that the sampling plan was followed, confirmed the data were nationally representative, and reviewed the data for consistency, reliability, and validity by interviewer and region [9]. They also checked response consistency across demographic items on the intake and annual survey. After the regional directors reviewed the data, quality control analysts at Gallup performed additional validity reviews. The data were centrally aggregated and cleaned, ensuring that correct variable codes and labels were applied. The data were then reviewed by a team at Gallup in detail for completeness, accuracy, and logical consistency.
Face-to-face and telephone survey administrationTo ensure interviewers followed the methodology and administered the survey properly, vendors were required to conduct in-field validations for a percentage of face‑to‑face and telephone interviews. Face-to-face interviews were validated by supervisor accompaniment, in-person recontact, phone recontact, or listening to recorded interviews. Telephone interviews were validated by live listen-ins or audio recordings.
At least 30% of completed face-to-face interviews were validated using accompanied interviews, in-person recontacts, or telephone recontacts. Validations were distributed across all regions and interviewers. The supervisor/validator evaluated the interviewer’s performance in implementing the survey methodology, including starting point selection, random route procedure, correct disposition code usage, participant selection, and proper survey administration (e.g., reading each question verbatim, not leading the respondent, etc.). Globally, approximately 25% of recruitment telephone interviews and 30% of baseline telephone interviews were validated. These validations confirmed that the interview was completed, methodological standards were followed (e.g., participant selection), and the survey was administered appropriately [9].
Additionally, interviewer productivity metrics and metadata were tracked throughout data collection [9]. These data will be made available as part of the sensitive data release starting in August 2024, and researchers will need to obtain IRB approval prior to accessing these data. The CAPI and CATI platforms used in the project provided monitoring tools for regularly evaluating collected data. Quality control analysts and in-country partners used these tools to ensure that completed interviews were valid and adhered to the methodology. Holistic reviews at regular fieldwork intervals covered a range of quality control procedures and aimed to identify suspicious patterns in the data (e.g., anomalies in interview duration, location, household selection, and participant selection). Flagged interviews were further investigated and validated, and surveys with quality issues were removed and replaced (when possible). At the end of fieldwork, final data vetting by Gallup ensured the validity, reliability, and accuracy of the collected data. The overall retention rates for each country after non-response and quality checks are provided Table 3.
Table 3 Availability of variables for non-response and post-stratification adjustments for each country in wave 1 of the Global Flourishing Study annual surveyOnline surveyQuality control was informed by the recent American Association for Public Opinion Research task-force report [16]. In addition to the standard quality control processes used to evaluate face‑to‑face and telephone data, the following quality control procedures were applied to completed online surveys. First, response metadata (i.e., response digital fingerprint) was evaluated to ensure surveys weren’t completed by bots, responses came from valid devices, and that all responses were unique. Duplicates or completed online surveys that were not from valid digital sources were removed in line with recommendations for quality assurance [17]. Next, responses were evaluated for inconsistency in responses to closely related items. Such cases were removed when other quality issues were present, but a seemingly inconsistent response by itself was not sufficient for removal. Next, participants who consistently selected a single response category for items within a question block were flagged as potentially problematic (i.e., straight-line responses). Such response patterns are plausible for valid cases, so such cases were only removed if other quality issues were present. Lastly, the total time required to complete the survey was checked against a minimum threshold of time required to read through the questions included in the survey [18]. A common threshold of 4 min was used across all countries for the annual survey, and a modified thresholds of 5 min was used for participants taking the combined intake and annual survey. Taken together, these response characteristics were used to evaluate each online survey response to ensure that the final cases included in the annual survey represent valid responses by participants.
Handling seemingly inconsistent responsesAlthough the above data quality checks were used to ensure the final dataset available for use by researchers has a minimal number of inconsistent and invalid responses, the dataset may nevertheless may contain seemingly inconsistent responses. A seemingly inconsistent response could be due to various reasons, such as misinterpretation of question by the respondent, temporary loss of attention by respondent, accidental data entry error by the interviewer, or another reason that is unknown to us but is internally logically consistent for the respondent. Adopting a holistic approach to quality control at the case level, a case is not thrown out of the dataset due to one or two perceived response inconsistencies. An ostensibly inconsistent case would require additional burden of proof before being discarded; otherwise such discarding has the potential to create unintended consequences related to disproportionate removal of certain types of respondents. Researchers may, however, still come across responses that seem logically inconsistent but may still be valid responses by the respondent.
To illustrate this, consider responses to the items Relationship with Mother (wording: Please think about your relationship with your mother when you were growing up. In general, would you say that relationship was very good, somewhat good, somewhat bad, or very bad? If you didn’t know your mother or if she died, select “Does not apply.”) and Love from Mother (wording: In general, did you feel loved by your mother when you were growing up? If you didn’t know your mother or if she died, select “Does not apply.”), it would be seemingly inconsistent to select “Does not apply” to only one of these items. However, the circumstances that each respondent was considering while responding to these items may vary. For example, a respondent may endorse “Does not apply” to the Love from Mother item because they equated “love” with “romantic love” or some form of love they felt wasn’t applicable to a familial relationship, whereas they perhaps did in fact have a relationship with their mother. Other explanations are also possible. The translation of the concept of “love” was challenging for this item, which is documented and discussed at length in the companion paper on translation and cognitive interviewing [11].
In practice, there are several approaches researchers can take to handling such cases. One possibility is to recode any response of “Does not apply” as a missing value and then handle missing data using a method appropriate to their analysis (e.g., multiple imputation, full-information maximum likelihood, etc.). Another approach could be to use “Does not apply” as a category of variable to evaluate whether those who respond “Does not apply” differ from a suitable reference group for the chosen analysis. The appropriate method for handling seemingly inconsistent responses will depend on context and purpose of the analysis. Caution should be exercised so that unintended measurement errors are not introduced by overcleaning.
Weighting and design effectsCase weighting was used to ensure samples were nationally representative of each country and was intended to be used for calculations within a country [9]. The methodologies and sources used to build country samples varied significantly. These differences required a customized approach to data weighting that incorporates probability and non-probability samples [19]. Final country weights only included respondents who completed the intake and annual surveys. To produce the final respondent weight, an initial weight was constructed for those who completed the intake survey. Further calibration on the initial weight occurred when an additional layer of post-stratification was adjusted for non-response on the annual survey. All non-response/post-stratification adjustments matched variables based on the marginal distribution of each matching characteristic. Countries where more detailed cross-classified population targets were used are shown in Table 3. The methods used for weighting intake surveys can be grouped into three main approaches based on the type of sample sources.
Approach 1: Probability samples onlyCountries using probability-based samples only: Egypt, India, Indonesia, Israel, Kenya, Nigeria, Philippines, South Africa, Tanzania, Turkey, and United States. In countries where data were collected using a single probability-based sample (e.g., Israel), sampling weights were constructed as the inverse of the selection probability for inclusion in the sample based on each country’s sampling methodology [9]. For face-to-face sampling methodology, overall selection probability accounted for selection probabilities at different stages of selection, including disproportionalities in allocation, selection of primary sampling units, selection of secondary sampling units (if applicable), household selection within the ultimate cluster, and selection of one eligible respondent within the household. The creation of sampling weights for probability only samples depended on whether households were sampled via a random-digit-dialing or pseudo-random route (see Probability-based samples subsection).
Under the random-digit-dialing phone sampling methodology, base sampling weights accounted for the selection of telephone numbers from the respective frames and corrected for unequal selection probabilities due to the selection of one adult in landline households and for dual users coming from both the landline and mobile frame [20, 21]. The base sampling weight for case \(i\) is
$$ w_ = \left[ }} }} \times \frac }} \times LL_ } \right) + \left( }} }} \times CP_ } \right) - \left( }} }} \times \frac }} \times LL_ \times \frac }} }} \times CP_ } \right)} \right]^ , $$
where \(S_ =\) total count of landline completes in corresponding landline; \(F_ =\) the total count of phone numbers in the landline frame in the corresponding stratum; \(S_ =\) the total count of mobile completes in each mobile stratum; \(F_ =\) the total count of mobile phone numbers in the corresponding stratum in the cell frame; \(AD_ =\) number of adults in household \(i\); \(LL_ = 1\) if respondent has a landline phone, otherwise \(LL_ = 0\); and \(CP_ = 1\) if respondent has a cell phone, otherwise \(CP_ = 0\) [9].
Under the face-to-face sample methodology, the base sampling weights similarly accounted for unequal probability of inclusion, but with a slightly difference in sampling frame. The general method used across countries to construct the base sampling weights assuming a single stage design is
$$ w_ = \left[ }}} \right) \times \left( }} HH_ }}} \right) \times \left( n_ }} n_ }}} \right)} \right]^ , $$
where \(HR_ =\) total number of adults in household \(i\) in PSU \(K\) in stratum \(H\); \(HH_ =\) number of households interviewed in PSU \(K\) in stratum \(H\); \(\sum\nolimits_ H H_ =\) total number of households in PSU \(K\) in stratum \(H\); \(P_ =\) number of PSUs sampled in stratum \(H\); \(n_ =\) population size of PSU \(K\) in stratum \(H\); and \(\sum\nolimits_ } =\) total population size of stratum \(H\) [9]. The formula is adjusted accordingly for different sampling designs.
Once the abovementioned base sampling weights were constructed, weights were post-stratified to adjust for non-response and match existing known target population totals (e.g., auxiliary data from a country-level census). Variables used for non-response/post-stratification adjustments included age, gender, education, region, employment status, marital status, and other variables that possibly vary by country depending on the availability of a reliable secondary source. Table 3 lists out, for each country, which variables were used.
The resulting distribution of post-stratified weights was highly skewed with some extreme weights; these extreme weights were trimmed to reduce estimator variance [22]. Trimming was conducted at both ends of the distribution of weights. The resulting minimum/maximum weight (i.e., trim points) generally fell between the 1–5%- and 95–99%-tiles. The weights were then redistributed across the remaining sample. The trim points were determined based on a tradeoff between bias (generally < 1% difference for age, gender, region, urbanicity and less than 3% for education) and variance as measured by design effect (taking into consideration just the variability in weights). For the purpose of weight calibration, the design effect measured by variability in weights where preferred design effect were below 2.
In several countries, data were collected using more than one probability-based sample (e.g., Indonesia), where the weighting was initially conducted separately for each sample. A combined case weight was then obtained using a composite weighting procedure to project the final combined weight to the target population of adults [23]. The design effects associated with different sample sources are described below.
Design effects and combined weights. For illustrative purposes, consider the multi-sample source data collected in Indonesia that consisted of face-to-face and telephone recruitment. Let \(w_\) represent the weight assigned to case \(i = 1,2, \ldots , n_\) from the face-to-face sample and let \(w_\) represent the weight assigned to case \(j = 1,2, \ldots ,n_\) from the telephone sample. The number of complete face-to-face and telephone samples are \(n_\) and \(n_\), respectively. The corresponding effective sample sizes under each recruitment methods are
where \(deff_\) and \(deff_\) are the design effects associated with face-to-face and telephone sampling, respectively [9]. The design effects were estimated using Kish’s method [24], where the design effects are approximated by
$$ deff_ = n_ \times \frac \left( ^ } \right)}} w_ } \right)^ }},\quad }\;\;i = 1,2, \ldots ,n_ $$
$$ deff_ = n_ \times \frac \left( ^ } \right)}} w_ } \right)^ }},\quad }\;\;j = 1,2, \ldots ,n_ $$
The design effects associated with each country are reported in Table 4. A total design effect was estimated for each country and a design effect specific to each mode of data collection for the annual survey (web survey, telephone interval, and face-to-face for Nigerian subsample). In all but one country (the United States) the total design effect was at most 2.0, and in the United States, the design effect was 5.49.
Table 4 Global Flourishing Study annual survey design effects—variability in weights—associated with each countryThe final weights are computed adjusting for the effective sample size of each sample source, resulting in weights
$$ w_^ = \left( ^ }}^ + n_^ }}} \right) \times w_ , $$
$$ w_^ = \left( ^ }}^ + n_^ }}} \right) \times w_ . $$
A note on the Nigerian sample. In Nigeria alone, the intake sample was split into two parts—one to cover households with individuals having access to a landline, mobile phone, or the internet, and a small number of PSUs to represent individuals living in households that do not have access to a landline, mobile phone, or the internet. Each sample was weighted separately and projected to the corresponding target population. Targets for the population without access to landline or a mobile phone were derived from the latest Demographic and Health Survey in Nigeria [25]. The resulting weighted samples were combined where 90% of sample came from sources with access to telephones or internet and 10% of the sample came from sources not having access to telephone nor internet. This latter sample constitutes what we call a “hard-to-reach” population that is less often included in large scale surveys and studies.
Approach 2: Non-probability samples onlyCountries and territories using a non-probability sample only: Hong Kong (S.A.R. of China), Japan, and Sweden. Data collection in Hong Kong (S.A.R. of China) and Sweden only used a non-probability sample obtained through online opt-in panels [9]. A small proportion of the sample in Japan was drawn from a probability frame, but it was insufficient to project that sample to the target population. For the purposes of constructing weights, all records in Japan were treated as non-probability samples. Since the selection probability of inclusion in the final sample is unknown, pseudo-base sampling weights were constructed using propensity weighting [19, 26]. The Sweden sample relied solely on propensity weighting. Hong Kong and Japan samples utilized a baseweight of 1 followed up with raking with detailed population targets (see Table 3). This approach estimated the probability of inclusion in the panel frame and generated respondent-level survey weights for subsequent analysis, see pg. 16–17 of [16].
A limitation of solely using a non-probability sample is the need to have an auxiliary probability-based sample from the same country with a subset of identical items [
Comments (0)