






Remember me









In team sports, such as basketball, volleyball, and ice hockey, the precise detection of players serves as the fundamental basis for intelligent auxiliary analysis of player movement data, assessment of multi-player coordinated behaviors, and comprehensive team technical and tactical analysis (Lu et al., 2011, 2013; Nishikawa et al., 2017; Stein et al., 2018; Kong et al., 2020). However, in the aforementioned competition scenarios, the statistical distribution of players' bounding boxes becomes wider and unbalanced due to the diversity of shooting distances and angles, along with the continuous movement and random switching of the camera. Specially, this substantial imbalance impairs the detection and localization abilities of existing model algorithms, particularly concerning extremely small and extremely large scale bounding boxes targets. Therefore, enhancing the detection ability of multiple players in non-equilibrium scale statistical scenes has become a significant challenge in the research and improvement of numerous algorithms in the field of computer vision.
As for the improvement of traditional algorithms, the primary emphasis lies on explicit multi-scale feature acquisition and fusion. In Lu et al. (2011), the combination of Histogram of Oriented Gradients (HOG) with color information is proposed. Stein et al. (2018) suggests the fusion of color histograms with target center points. Additionally, Santhosh and Kaarthick (2019) introduces the combination of the Deformable Parts Model (DPM) with Scale Invariant Feature Transform (SIFT) keypoints. These methods can significantly enhance the ability to extract explicit features of players through artificially designed operators. However, they exhibit more localized effectiveness and encounter difficulties in adaptively detecting targets of all scale bounding boxes.
The improvement based on deep learning models primarily leverages the universal object detection framework and its extensions (Akan and Varli, 2022; Sah and Direkoglu, 2023) to achieve the acquisition and fusion of implicit multi-scale features. As demonstrated in Nishikawa et al. (2017), the multi-branch output structure of the enhanced YOLOv3 model is directly employed to acquire and merge adjacent scale basketball player features. Building upon the addition of various scale feature detection branches, Kong et al. (2019) further integrates a spatial pyramid pooling (SPP) module, enhanced by hole convolution, into the training of the medium scale detection branch with the largest sample volume. This integration aims to enhance the complexity and precision of feature extraction and mitigate potential model overfitting or underfitting arising from sample imbalance. In Buric et al. (2019), features from non-adjacent scales were fused by integrating improved Feature Pyramid Networks (FPNs) into the backbone network, and the Fast R-CNN model was combined to enhance the detection effectiveness of multi-scale football players. Simultaneously, incorporating an attention mechanism into the backbone network for multi-scale feature extraction and fusion is also a prevalent approach. In line with this, both Komorowski et al. (2020) and Hurault et al. (2020) utilize attention mechanisms to enhance the detection capability of football players. In He (2022), attention mechanism was combined with a encoder-decoder model to obtain and fuse multi-scale features through encoding and decoding, achieving the detection of multiple types of multi-scale players. However, the naturally formed player detection dataset still exhibits an imbalance in the distribution of scales, resulting in a significant number of omissions in the detection of players with small sacle bounding boxes and inaccurate positioning of players with large scale bounding boxes in the aforementioned improved algorithms.
In response to the above issues, and inspired by techniques from partial feature fusion (Zhang et al., 2022) and data processing (Ding et al., 2023), this article proposes a multi-scale attention mechanism that weakly relies on the scale statistical distribution features of the dataset and a scale equalization algorithm. These methods combine the strong implicit feature extraction ability of deep learning models with the local enhancement characteristics of traditional operators describing explicit features, thereby further improving the accuracy of multi-scale player detection. The main innovations and contributions of this article include: (1) The proposal introduces the Similar to Intersection over Union (SIoU) label to represent explicit feature information of multi-scale targets. Based on this label, relevant network modules are constructed to generate coarse-grained scale attention feature planes that aid in multi-scale target detection. (2) An algorithm combining non Supervised learning and interval estimation using the statistical distribution information of the coarse-grained scale attention feature plane is proposed, so as to form a fine-grained scale attention with higher concentration. (3) We presents a scale equalization algorithm that is attached to the SIoU label and integrated into the training of the scale attention generation module. The algorithm aims to address the issue of network overfitting during training, which arises from the presence of a significant volume of samples with identical scale targets. Additionally, it mitigates the training error caused by the imbalance in the scale distribution of players' bounding boxes in ball team competitions.
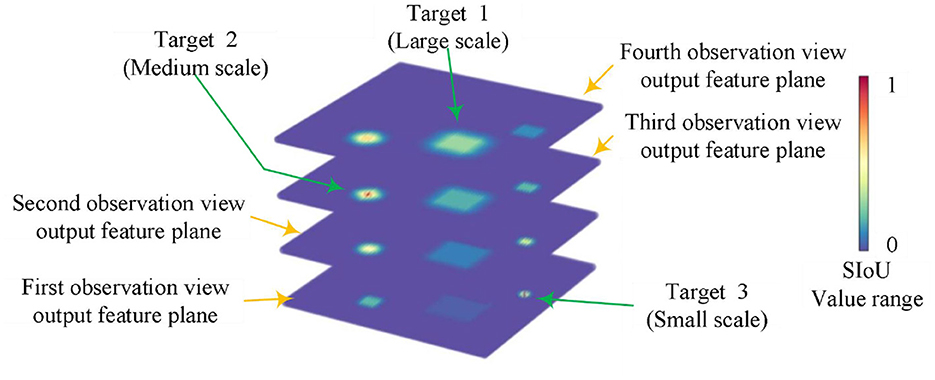
2 The principle of SIoU labelThe Intersection over Union (IoU) (Yu et al., 2016) is a metric commonly employed in object detection tasks to assess algorithm performance. It is defined as the ratio between the intersection and union of the predicted field of view bounding box and the target's actual bounding box. This article formulates equation (2) using equation (1) to compute the SIoU (Similar to Intersection over Union) label. The SIoU label represents the ratio of intersection and union between the predicted field of view bounding box and the actual bounding box of the target in the output feature plane of the observed field of view. It calculates this value while continuously shifting the center position (x, y) of the predicted field of view bounding box. Starget(k) denotes the true bounding box of the k-th target, and Skernel(x, y, z) represents the predicted bounding box of the z-th observation field when the output feature plane is centered at point (x, y). The SIoU values that can be generated through systematic variation of the size of the predicted field of view bounding box and the target's actual bounding box are illustrated in Figures 1, 2. This numerical characteristic of change exhibits similarity to the credibility of the human visual system when observing multi-scale targets across different fields of view, thus providing an explicit expression of multi-scale characteristics.
IoU=SoverlapSunion (1) SIoU(x,y,z,k)=Soverlap(x,y,z,k)Sunion(x,y,z,k)=Starget(k)∩Skernel(x,y,z)Starget(k)∪Skernel(x,y,z) (2)Figure 1. The visualization of SIoU features across distinct scales for various targets.
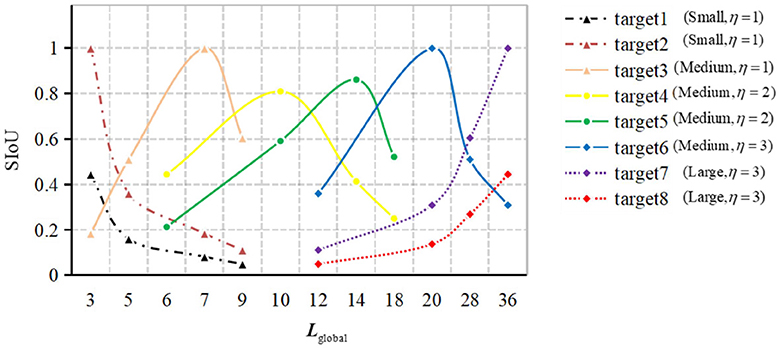
Figure 2. Numerical distribution of SIoU values for typical scale targets.
Figure 2 displays a representative statistical distribution of SIoU values, obtained through a typical single point quantization calculation, applied to targets of various scales using four corresponding equivalent prediction field of view boundary boxes. The typical single point quantization value refers to the SIoU value calculated when the predicted field of view bounding box aligns precisely with the center position of the target's actual bounding box. This serves as an illustrative example of certain feature points in Figure 1.
In Figure 2, the distinct line types represent different predicted branches η to which the target belongs. The calculation of these branches is determined by equation (3), where ηmax denotes the upper limit of the number of predicted branches in the model. In equation (3), ℓtarget(k)denotes the edge length of the k-th target, which is computed following equation (4). Likewise, ℓkernelz(xcenter,ycenter) signifies the edge length of the z-th basic predicted field of view bounding box, calculated based on equation (5). The set Lglobal, comprising the edge lengths of all globally equivalent predicted field of view bounding boxes in the figure, is derived following equation (6).
η=min(max(log2ℓtarget(k)max( )+2,1),ηmax) (3) ℓtarget(k)=Starget(k) (4) ℓkernelz(xcenter,ycenter)=Skernel(xcenter,ycenter,z) (5)The variation pattern observed in different color curves in Figure 2 indicates that the SIoU value exhibits correlation between the same target and different predicted fields of view bounding box. Moreover, it demonstrates distinguishability for targets of the same category but different scales. Among the four consecutive SIoU values obtained, those corresponding to small-scale bounding box targets exhibit relatively small values and display a decreasing trend. In contrast, the SIoU values for medium-scale bounding box targets are relatively larger, with an initial increase followed by a subsequent decrease. For large-scale bounding box targets, the SIoU values are relatively small and demonstrate an upward trend. These trends primarily emphasize the relative relationships among SIoU values, rather than the absolute values themselves.
Figure 3 presents the statistical distribution of all corresponding SIoU values computed for equivalent target bounding box sizes ranging from 3 × 3 to 54 × 54. These calculations are performed when the observation view output feature planes of the three prediction branches are set to 56 × 56, 28 × 28, and 14 × 14, respectively. The SIoU values are categorized into two groups based on the size of the predicted view bounding box and the actual target bounding box. As depicted in the Figure 3, the SIoU numerical ranges for the majority of target exhibit considerable overlap and intersections with one another. This observation suggests that employing any volume of samples and training the model to extract the four required SIoU numerical features for targets of diverse scales indirectly enhances the extraction capability of relevant SIoU values for targets of other scales. Moreover, it indicates a weak dependence of the SIoU value on the scale statistical distribution of the dataset.
Figure 3. Statistical distribution of SIoU numerical ranges for all scale targets.
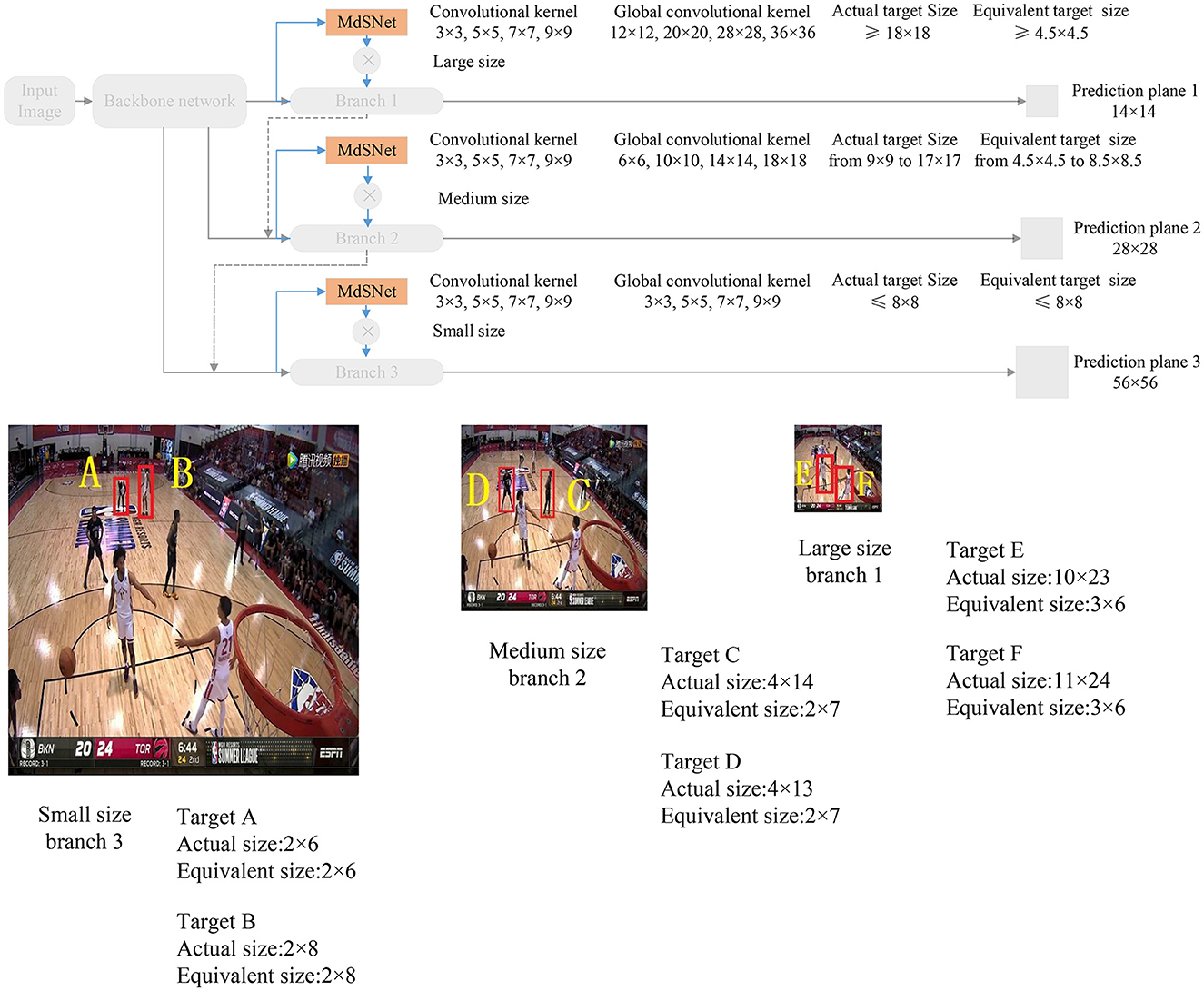
When employing the SIoU value-based label to assist the depth Convolutional Neural Network in constructing a multi-scale attention plane, and under the condition where all branches share the same SIoU value, the network model can accommodate different scale targets through its multi-scale branch structure. Additionally, the predicted field of view bounding boxes at various scales can be efficiently replaced by globally equivalent predicted field of view bounding boxes in different branches, utilizing basic convolutional kernels with size of 3 × 3, 5 × 5, 7 × 7, and 9 × 9, respectively. As depicted in Figure 4, the input basketball game image comprises a total of 6 targets, consisting of 2 large-size targets, 2 medium-size targets, and 2 small-size targets. Following the aforementioned guidelines, the scale attention for targets A and B is assigned to the small-size branch 3, the scale attention for targets C and D is assigned to the medium-size branch 2, and the scale attention for targets E and F is allocated to the large-size branch 1.
Figure 4. Guidelines for selecting target belonging branches.
3 Proposed methodBased on the SIoU label, we initially construct a network module to extract multi-dimensional distribution features. It utilizes coarse granularity scale attention formed by the explicit features of multiple scales to enhance multi-target detection with scale imbalance. Subsequently, leveraging the distinctive characteristic of a single target type in team sports, the K-medoids algorithm is enhanced by incorporating player bounding box information and statistical features, resulting in a fine-grained scale attention optimization algorithm. Finally, the proposed scale equalization algorithm is integrated with the SIoU label to jointly facilitate the training of the network model incorporating multi-scale attention.
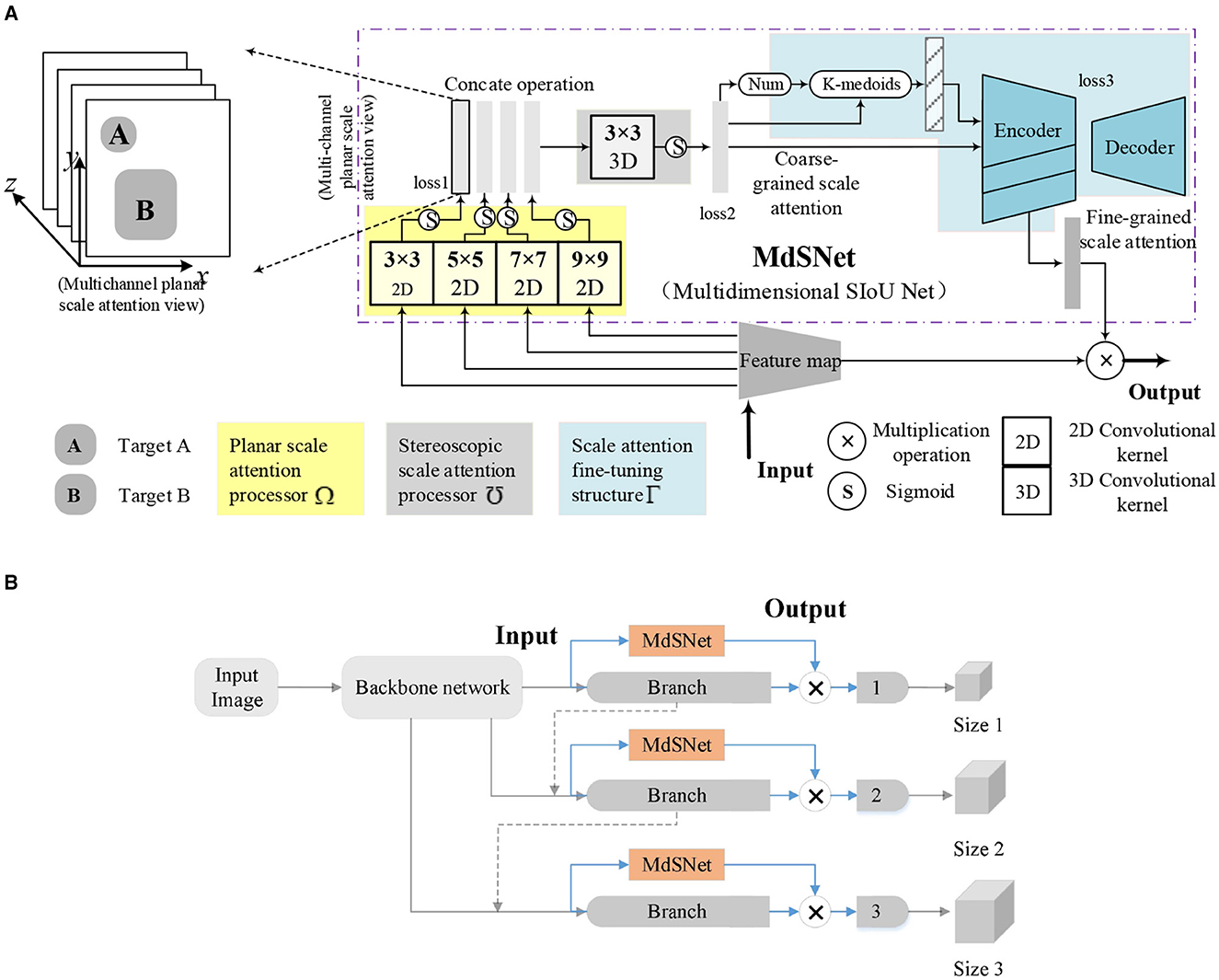
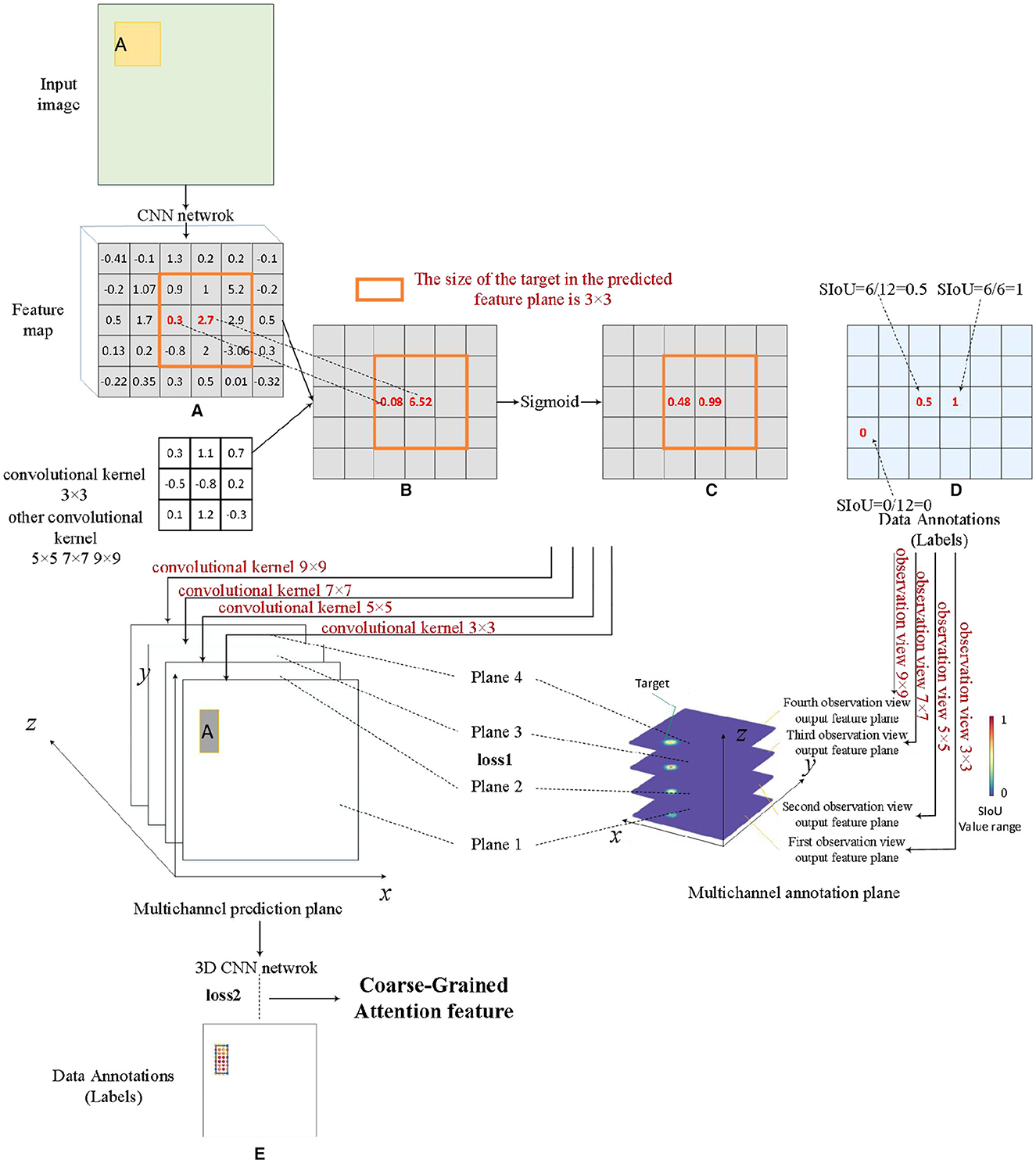
3.1 Network module for SIoU feature extractionThis article introduces a network module named MdSNet (Multidimensional SIoU Net) designed to extract multi-dimensional SIoU features generated by multi-scale targets through the application of multi-scale convolution kernels. As depicted in Figure 5A, MdSNet comprises three main components: a planar scale attention processor, a stereoscopic scale attention processor, and a scale attention fine-tuning structure. Their corresponding training loss functions are denoted as loss1, loss2, and loss3, respectively. Simultaneously, we illustrate the relationship between the MdSNet module and traditional object detection and localization models in Figure 5B. Ultimately, the module outputs a fine-grained scale attention feature plane.
Figure 5. Schematic diagram of the MdSNet and its relationship with target detection model. (A) Schematic diagram of the MdSNet. (B) The relationship between MdSNet and a typical target detection model.
The planar scale attention processor incorporates multi-scale convolutional kernels and sigmoid functions. The four sizes of convolutional kernels generate four planar scale attention feature maps for all corresponding targets in their respective scale branches. The resulting feature maps are then concatenated to form a multi-channel structure. The stereoscopic scale attention processor is composed of a 3D convolutional kernel and sigmoid functions. It takes multi-channel planar scale attention concatenation maps as input, producing coarse-grained scale attention planes, and predicting the number of potential targets within the planes. The scale attention fine-tuning structure comprises a statistical feature extraction process and a codec, ultimately yielding a fine-grained scale attention plane.
3.2 Process for coarse-grained attention generationThe planar scale attention processor and the stereoscopic scale attention processor collectively constitute the pivotal components of the SIoU multi-dimensional distribution feature extraction network module. The training process commences sequentially, considering both the sample volume of the dataset and the structure of the network model. Firstly, the planar scale attention processor is trained, and the data labels during training are generated based on equation (2). Figure 6A is a conventional feature map, while Figure 6B is a single channel feature map obtained using a fixed size convolution kernel. Figures 6C, D illustrate the predicted data and label data, respectively. At this stage, the loss function loss1 is constructed based on the L2 norm, which is the mean square error function, and the optimizer used is the Stochastic Gradient Descent (SGD) algorithm. The main objective of this training process is to discriminate the various SIoU numerical information generated by different scale bounding box targets under the influence of the same size convolutional kernel. The emphasis lies in obtaining the absolute distribution of SIoU features in the plane space, as expressed by each output channel feature map. Secondly, the stereoscopic scale attention processor is trained to improve the capability of extracting multi-dimensional SIoU features, with a particular emphasis on capturing the relative relationships between the SIoU values of each channel within the input multi-channel planar scale attention feature map. Data labels required for training are generated using a normal distribution, where the statistical distribution of each target is set as a normal distribution with parameter (μ, σ), serving to approximate the coarse-grained scale feature range. The specific values of this parameter can be determined through experimental evaluations. This is shown in Figure 6E. At this stage, the loss function loss2 is constructed based on the L2 norm.
Figure 6. Coarse-grained attention feature generation process. (A) Feature map, (B) single channel feature map, (C) feature map after sigmoid function, (D) the intermediate process of data annotations operation, and (E) data annotations.
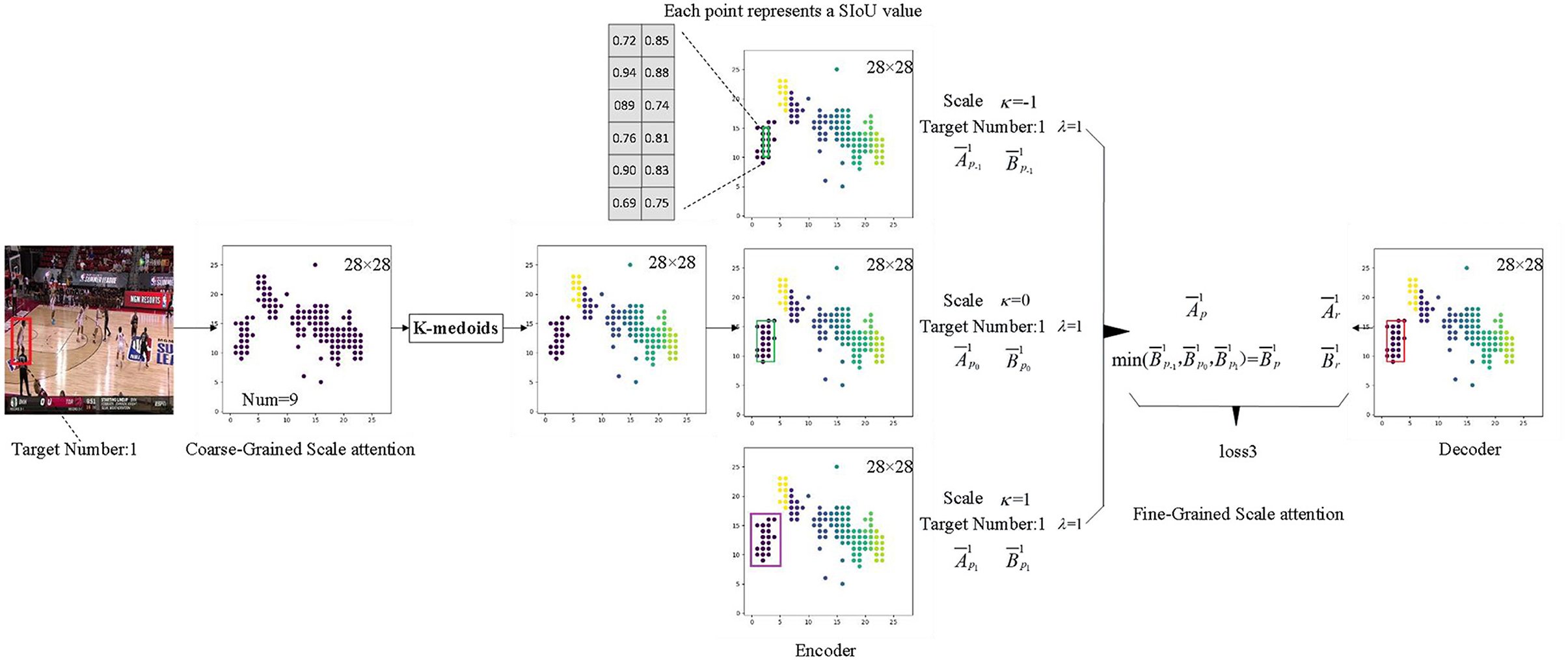
3.3 Process for fine-grained attention generationScale attention fine-tuning structure employs real data to compensate for the subjectivity of the SIoU label in this study, and it aims to optimize the coarse-grained scale attention features produced by the MdSNet network module. This structure executes Algorithm 1, initially employing the enhanced K-medoids algorithm in conjunction with the number of targets predicted by the previous processor in the feature map to compute the center position of each target on the coarse-grained scale attention feature plane. Subsequently, the orientations of all targets are sorted using the Manhattan distance. Finally, through training with a codec and statistical interval estimation method, the confidence interval derived from real data guides the module to generate the best-matched confidence interval, achieving fine-tuning of scale attention.
Algorithm 1. Fine-grained scale attention optimization algorithm.
The essence of the K-medoids algorithm improvement resides in the distance calculation method between the associated feature points, as illustrated in equation (7). φ and τ are obtained based on equations (8) and (9), respectively, where (x0, x1)(y0, y1) represents the coordinate information of the two points, and fsize denotes the size of the current feature plane. Considering that competitive game images are resized to a standard size of 448 × 448 before being fed into the network model, the bounding boxes of players exhibit evident aspect ratio characteristics. Consequently, for distance calculation, an ellipse with a major-to-minor axes ratio of τ is constructed, and the ratio τ is adjusted based on the statistical distribution characteristics of the player's bounding box width and height.
Lxy=(x02φ+x12τ·φ-y02φ-y12τ·φ)2 (7) φ=(x0+tan(1fsize)·x1)2 (8)The specific process is depicted in Figure 7. When implementing a codec, the confidence interval within the corresponding bounding box range serves as both the decoder and encoder. The confidence region range is determined using equation (10), where A¯ represents the sample mean and B¯ represents the interval width. B¯ can be computed using equation (11), where S¯ represents the square root of the sample variance, and n is the number of sample points. For coarse-grained scale attention planes, once the bounding box information for each target is established, it can be assumed that its scale features follow a normal distribution. Although the true mean and variance of the corresponding statistical distribution are unknown, confidence data within a certain bounding box can be used as a sampling sample to calculate its sample mean A¯ and sample variance S¯. Consequently, the confidence interval for the statistical mean μ at a confidence level 1-α can be computed. The decoder obtains the necessary bounding box information from the real data labels of the target. Given the fixed scale size of each branch adapted by the MdSNet network module, the encoder acquires the boundary box information from the boundary boxes obtained after multiple length and width expansions or contractions of each scale branch. By utilizing the feature information from the encoder with the narrowest confidence interval range (i.e., the encoder feature with the most concentrated scale feature data), along with the real label information from the decoder, the loss function is solved in accordance with equation (12), this corresponds to the loss3 in the figure.
(A¯-B¯,A¯+B¯) (10) B¯=S¯ntα/2(n-1) (11) loss=(Ar¯-Ap¯)2+(Br¯-Bp¯)2 (12)Figure 7. The specific generation process of fine-grained attention features.
3.4 Scale equalization algorithmThe scale equalization algorithm equalizes image scale statistics that approximate a normal distribution. It achieves this by indirectly using the scaling factor γh,wi,j, without directly altering the sample bounding box size in the dataset. The algorithm's purpose is to reduce missed detections of relatively small-scale bounding box targets within the dataset. Drawing inspiration from the image grayscale value equalization algorithm (Acharya and Kumar, 2021), we transform the probability density functions of the image height statistic h and width statistic w, following equations (13) and (14) respectively, to derive new statistics ϕ and ψ. Since h and w are independent of each other, ϕ and ψ are also independent, as indicated by their joint probability density as shown in equation (15).
ϕ:H(h)=∫0hf(h)dh (13) ψ:H(w)=∫0wf(w)dw (14) f(w,h)=f(ϕ)·f(ψ) (15)Since both ϕ and ψ follow a uniform distribution after transformation, f(w, h) = 1 also adheres to a uniform distribution probability density on 0 ≤ w ≤ 1 and 0 ≤ h ≤ 1. As a result, the statistical information of the non-balanced scale quantity in the dataset can be effectively balanced. The scaling factor γh,wi,j, obtained through the equalization algorithm, and the SIoU label designed in this paper can be multiplied and fused following equation (16). The parameters mhi and nhi represents the quantity values of the i-th level of height statistics for targets in the source dataset before and after the execution of the algorithm, respectively, while mwj and nwj represent the quantity values of the j-th level of width statistic for targets in the source dataset before and after algorithm execution. The fundamental principle of this scale equalization lies in the utilization of scaling factors to introduce perturbations during the training process, particularly for targets with a large volume of specific scales, with the aim of mitigating overfitting.
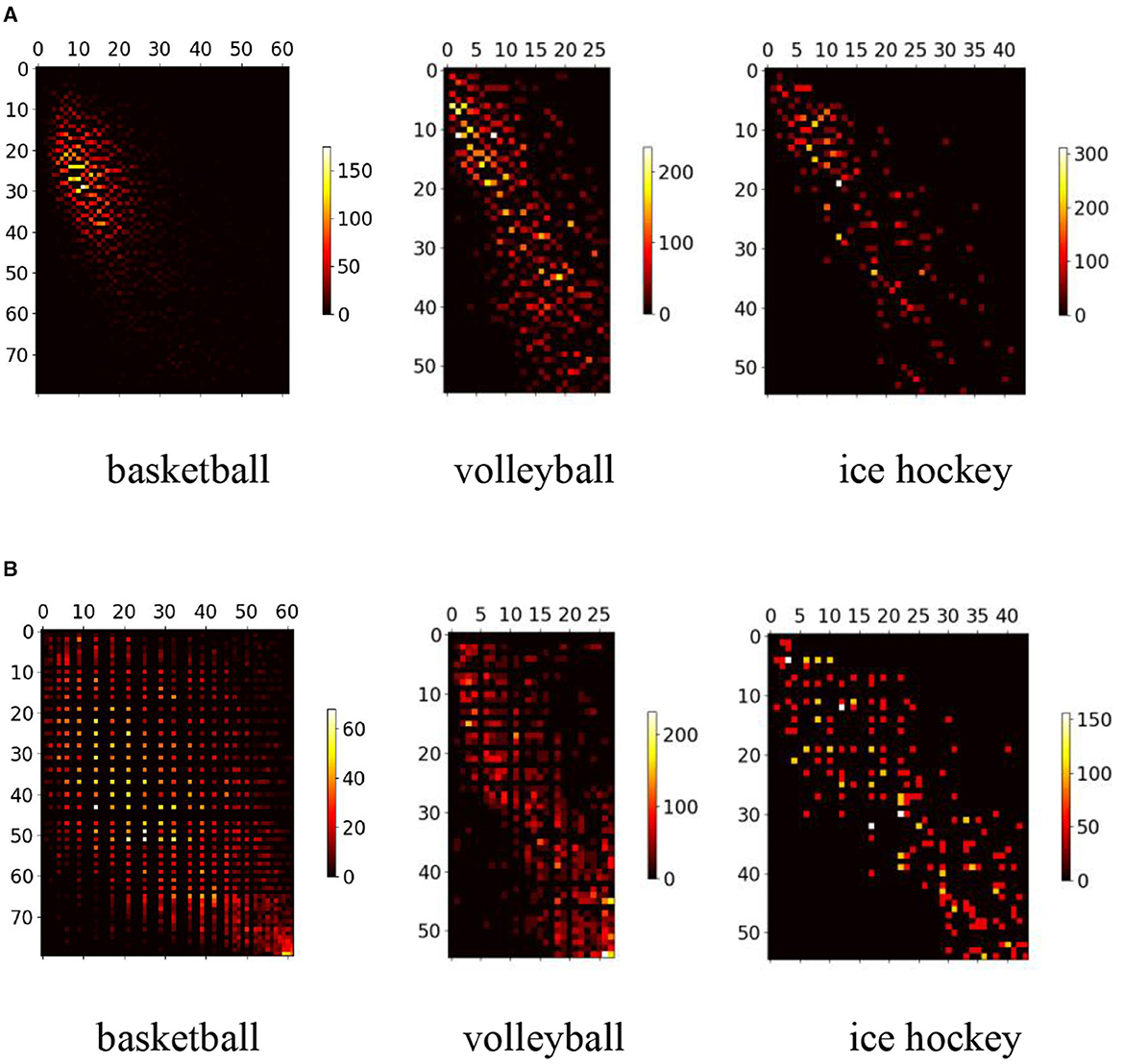
γh,wi,j=nhimhi·nwjmwj (16) 4 Experiment 4.1 Dataset and statistical distribution analysisCurrent competitive game datasets predominantly encompass medium-scale bounding box samples, as depicted in Figure 8A, for player detection, often overlooking the relatively scarce instances of both small-scale and large-scale bounding box samples, illustrated in Figure 8B.
Figure 8. Sample images from the dataset. (A) Primary scale samples. (B) A limited number of small-scale and large-scale samples.
We undertake the reconstruction of a comprehensive competitive competition dataset that encompasses targets of diverse scale bounding boxes. Sample scale equalization, based on Algorithm 2, is then implemented. The dataset comprises three distinct game scenarios: basketball, volleyball, and ice hockey. Each scenario encompasses ~25 min of valid video sequences, each with a frame rate of 25. Extracting 5% of the image frames from the video, player information is annotated, resulting in around 15K, 13K, and 16K labels for basketball, volleyball, and ice hockey, respectively. The initial scale distribution of the dataset, depicted in Figure 9A, exhibits unevenness and approximately follows a normal distribution. Post-processing with Algorithm 2 yields the scale distribution depicted in Figure 9B, markedly enhancing overall distribution balance compared to the original dataset.
Algorithm 2. Sample Scale Equalization Algorithm.
Figure 9. The scale distribution of the dataset. (A) The scale distribution of the original dataset. (B) The scale distribution after dataset scale equalization.
4.2 Experiment on multi-scale attention generationThe process of formulating scale attention predominantly encompasses acquiring two categories of information: the coarse-grained features of multi-scale attention and the fine-grained features of multi-scale attention. In the experiment, the ResNet architecture was adopted as the backbone network, leading to the construction of three scale attention branches: large, medium, and small. The ultimate dimensions of the predicted feature planes were 56 × 56, 28 × 28, and 14 × 14, respectively. To acquire coarse-grained information of multi-scale attention features, the hyperparameters were set as follows: μ = 0.85 and σ = 0.15, utilized during the generation of training labels. For the fine-grained information of multi-scale attention features, following the principles outlined in Algorithm 1, corresponding quantity fine-tuning encoders were designed for the three scale branches. The visualization outputs of the experience are depicted in Figure 10, where Figure 10A is the original image. These results illustrate that coarse-grained scale attention, Figure 10B, effectively segregates the scale features of the target for detection and enhances its positional information. Additionally, fine-grained scale attention, Figure 10C, further refines the precision and concentration of potential target positions, building upon the foundation laid by coarse-grained scale attention. Certainly, fine-grained scale attention not only enhances detection accuracy but also results in a several-fold increase in the overall runtime of the network model. This is especially due to the improved K-medoids algorithm, which adds considerable time overhead. Therefore, the scale attention model is better suited for offline video processing, similar to the one investigated in this article.
Figure 10. Comparison between coarse-grained and fine-grained scales attention. (A) Original image (B) Coarse-grained scale attention (C) Fine-grained scale attention.
4.3 Comprehensive experimentThis section presents three comprehensive sets of experiments concerning multi-scale player detection. The first set is ablation experiments focusing on the three fundamental processes outlined in our method, aiming to evaluate the efficacy of each process. The second set involves experiments conducted with a dataset volume of approximately 10%, serving as a preliminary validation of the proposed method's capacity to enhance target detection accuracy. In the third set of experiments, algorithmic comparisons are conducted across various dataset volumes, serving to underscore the limited influence of sample size distribution on the multi-scale attention model.
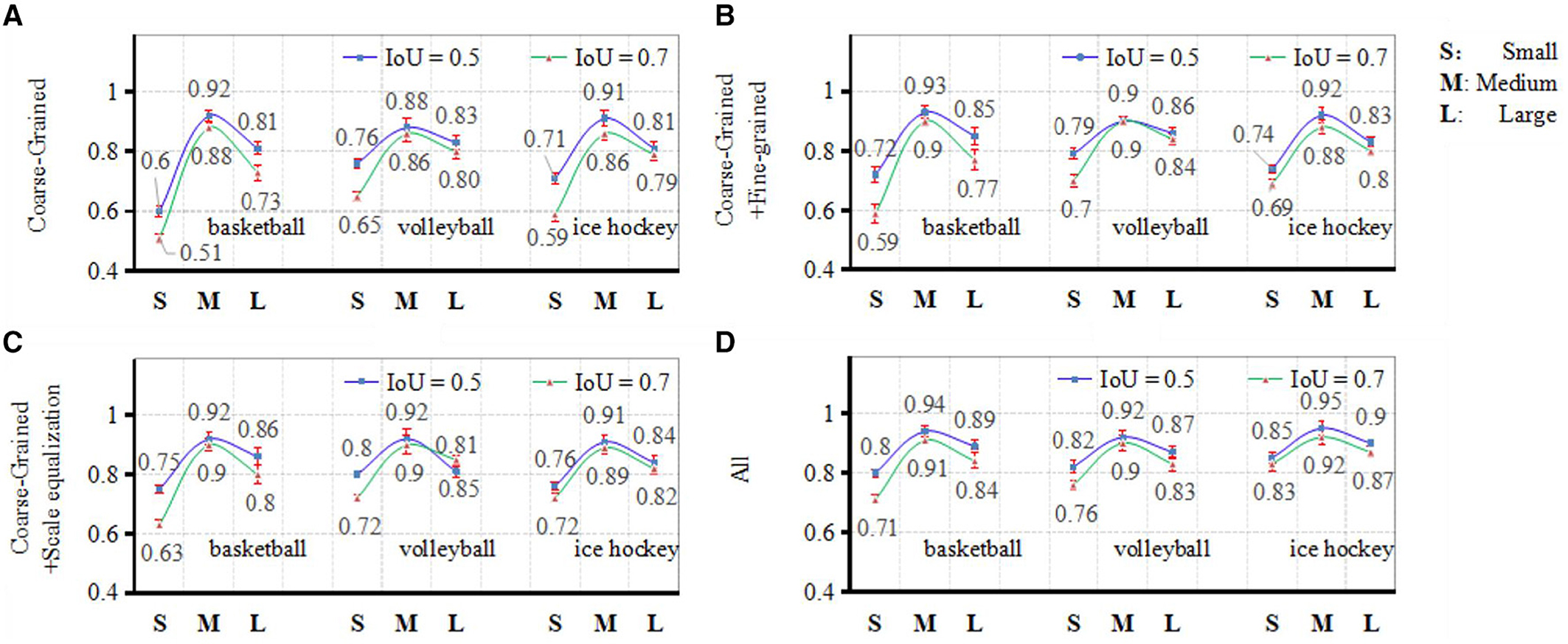
4.3.1 Ablation experimentThe experimental findings, presented in Figure 11, depict ablation experiments conducted on the three core processes encompassing coarse-grained scale attention, fine-grained scale attention, and scale equalization, as formulated in the methodology of this article.
Figure 11. Results from ablation experiments comparison. (A) Coarse-grained, (B) coarse-grained and fine-grained, (C) coarse-grained and scale equalization, and (D) all.
The evaluation metrics employed in this experiment are computed according to equation (17), where TP denotes the count of correctly predicted positive player instances, FP signifies the count of erroneously predicted positive player instances, and FN represents the count of erroneously predicted negative player instances. In the course of the experiment, the IoU thresholds for player detection were set at 0.5 and 0.7, respectively. The accuracy of target detection was assessed across four scenarios: solely employing coarse-grained scale attention, utilizing both coarse-grained and fine-grained scale attention, incorporating coarse-grained scale attention and the scale equalization algorithm, and integrating all three core processes. Analyzing the results reveals that coarse-grained scale attention serves as the fundamental framework for achieving multi-scale object detection in ball games. Fine-grained attention functions as a secondary refinement of coarse-grained attention, showcasing more pronounced enhancements in detection outcomes particularly under higher IoU requirements. The scale equalization algorithm is particularly effective in enhancing the detection capability for maximum and minimum scale bounding box targets within smaller sample volume, yielding notably improved effects compared to fine-grained scale attention.
ACC=TPTP+FP+FN (17) 4.3.2 Algorithm comparison experiment under low data volumeTo provide an initial validation of the capability of multi-scale attention to enhance the accuracy of conventional object detection algorithms, a subset amounting to approximately 10% of the player detection dataset was extracted. Leveraging the YOLOv3 algorithm and pretraining the backbone network on the PETA dataset, comparative experimental results were obtained for the approach presented in this article, the approach augmented with the FPN (Zhao et al., 2019) module, the approach augmented with the PANet (Bochkovskiy et al., 2020) module, and the approach augmented with the BiFPN (Zhang et al., 2021) module. As illustrated in Figure 12, the images in the odd-numbered rows depict the detection results of players enclosed within medium-scale bounding boxes. Conversely, the images in the even-numbered rows encompass the detection outcomes of players enclosed by bounding boxes of maximum or minimum scale.
Figure 12. Results of pl
Comments (0)