
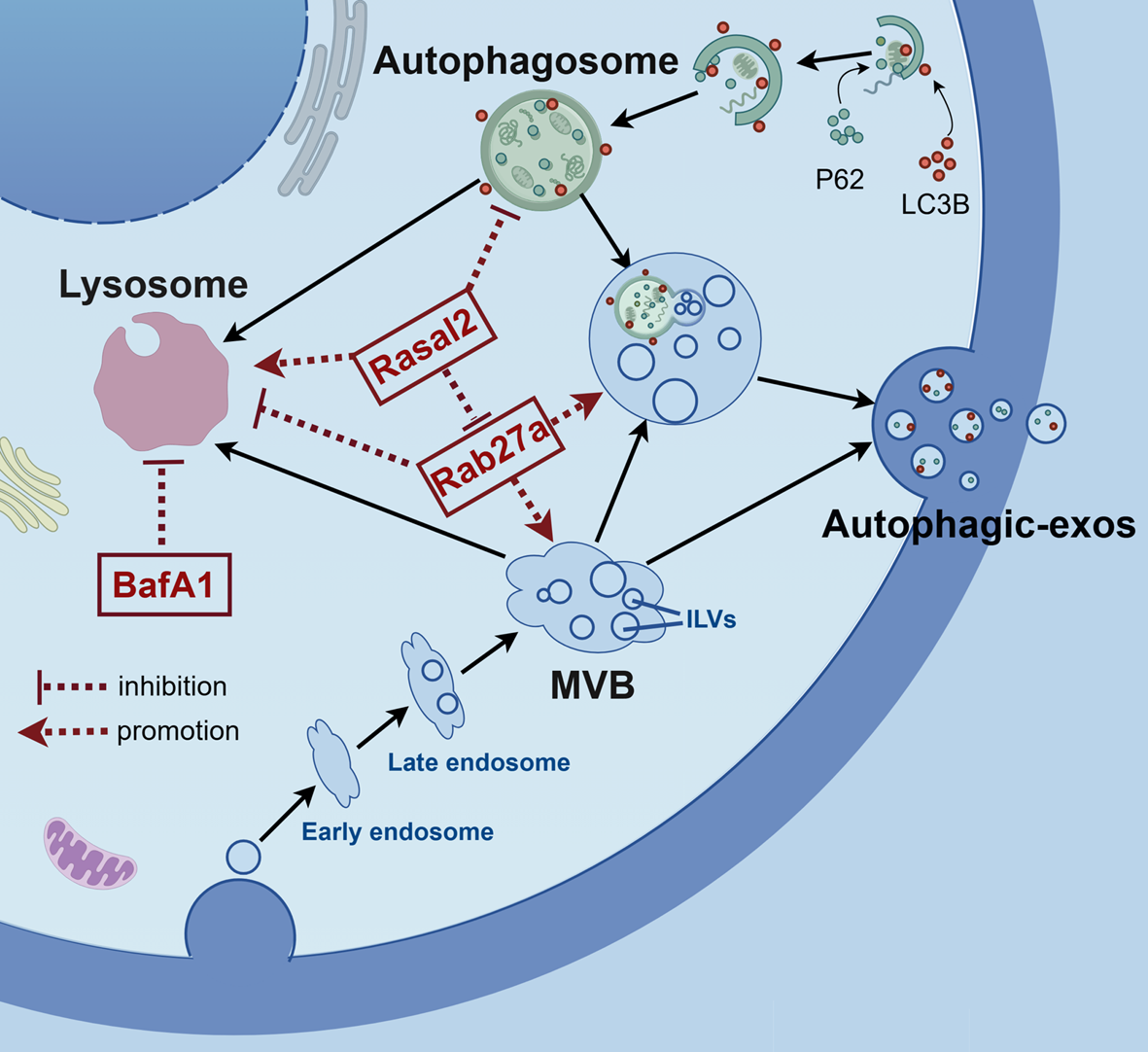
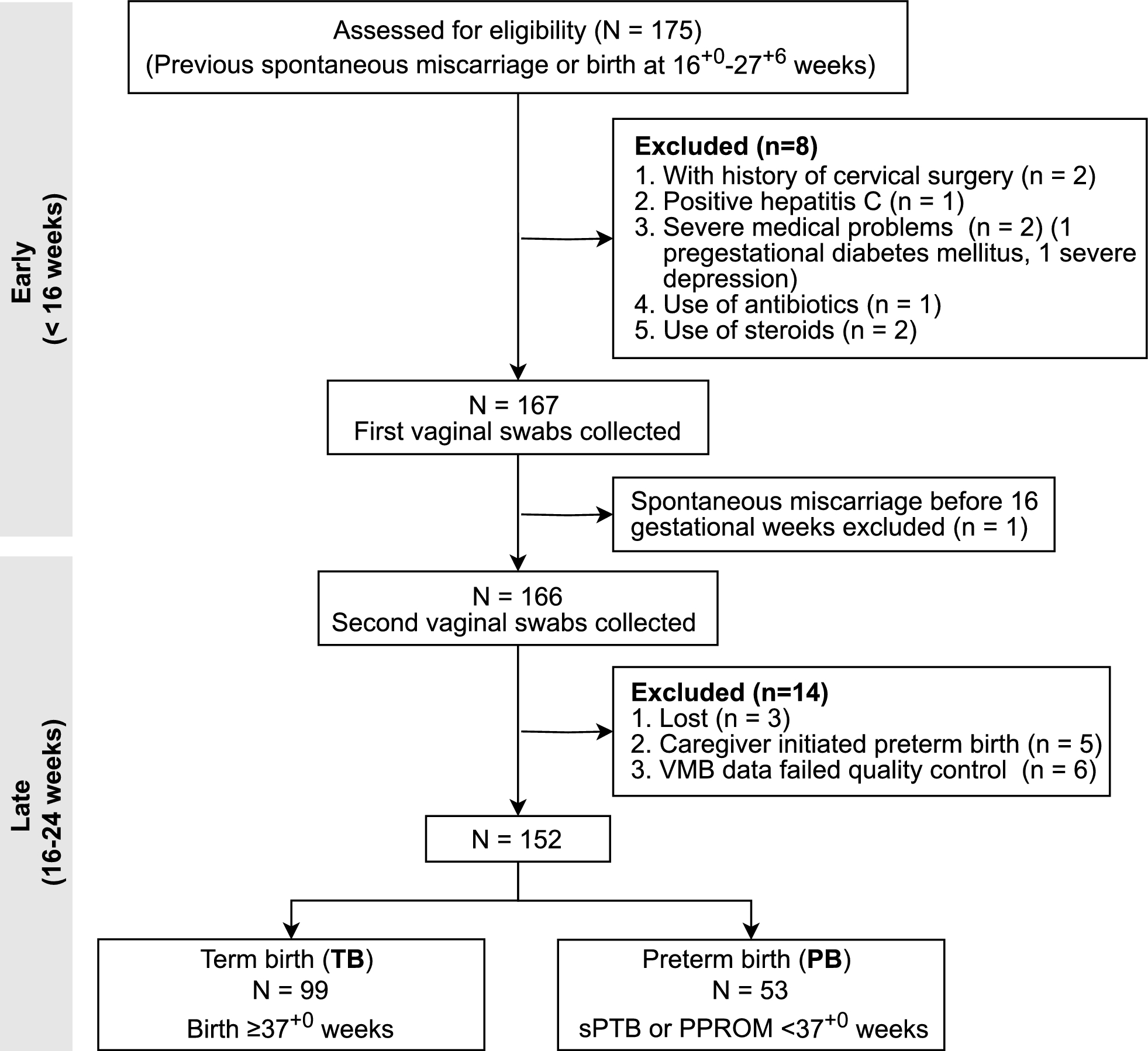
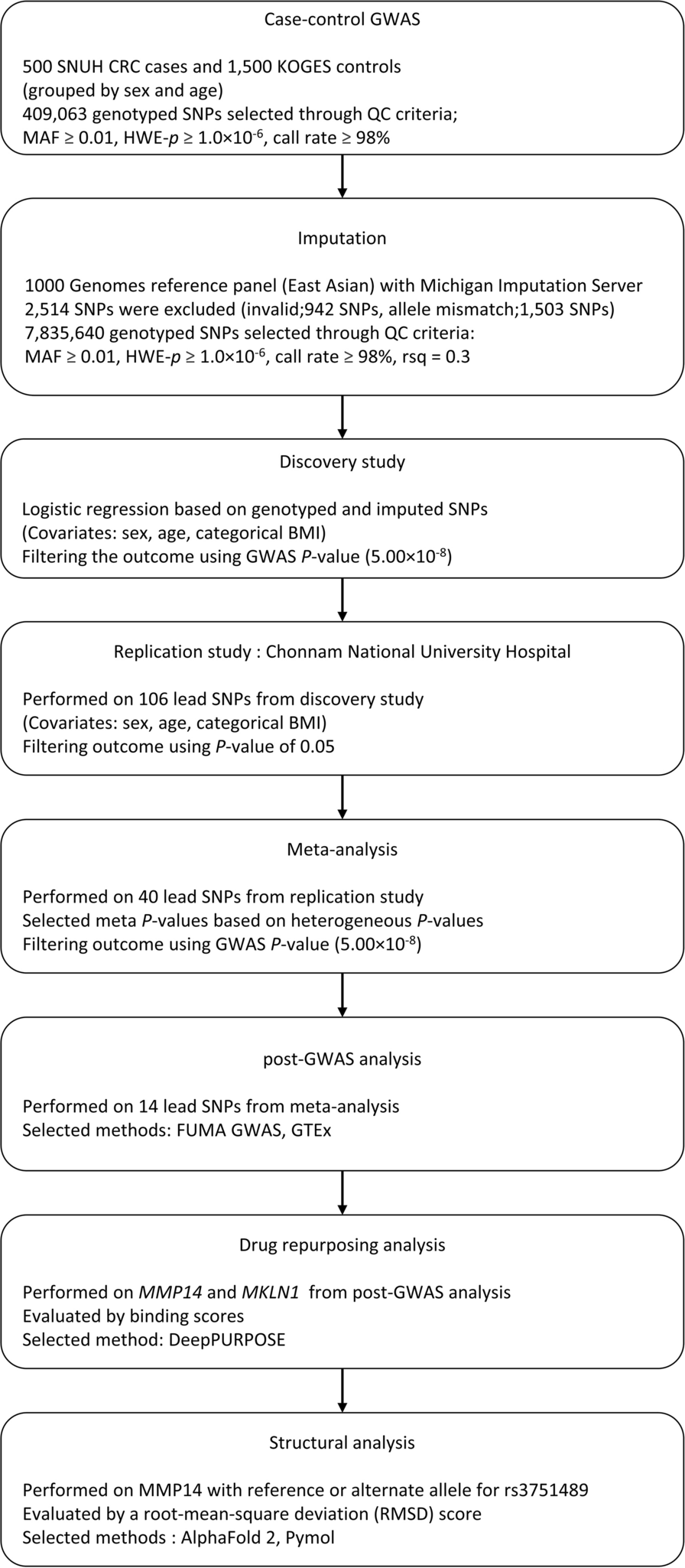
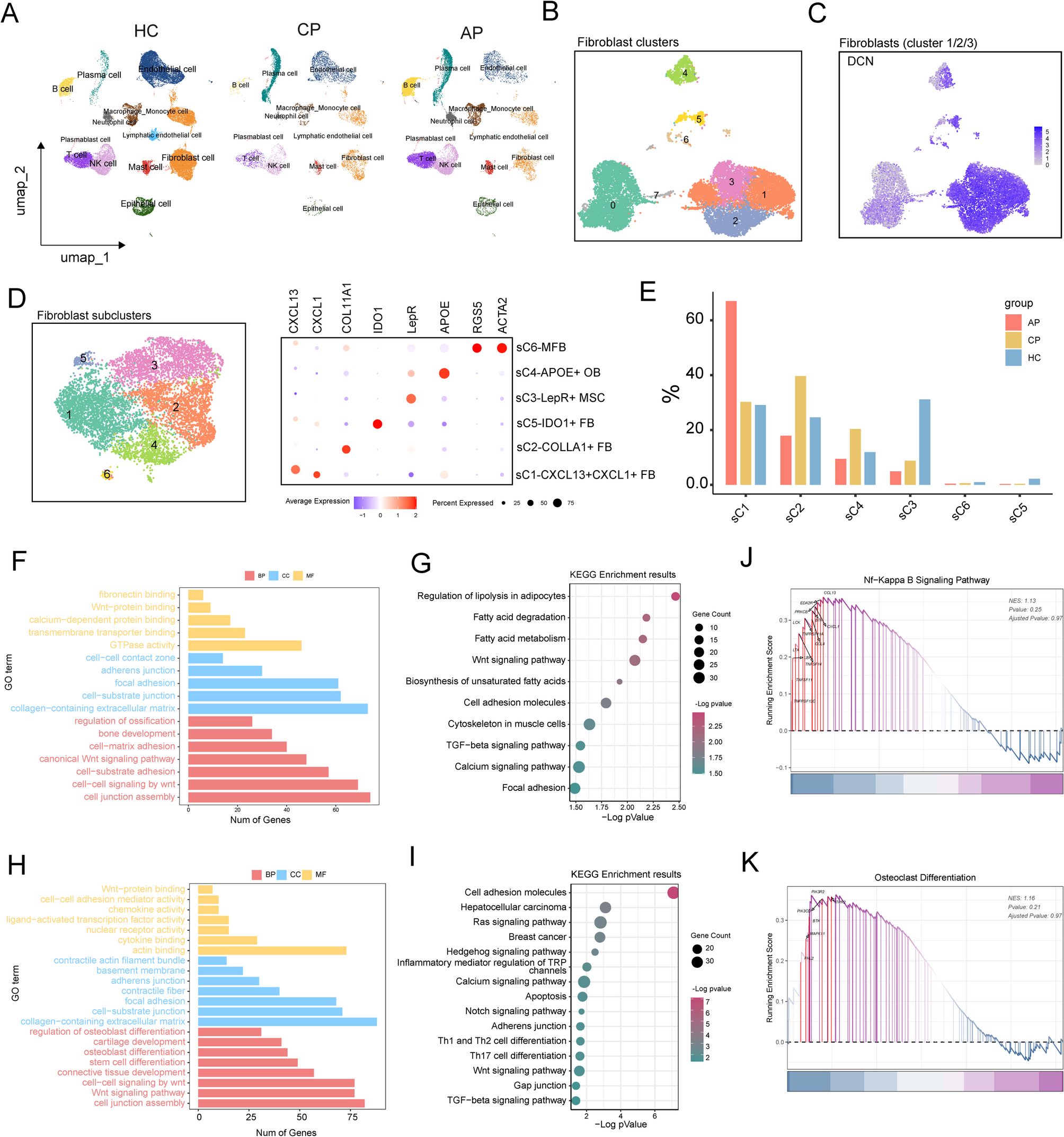
Remember me




Excluding 35 subjects without genotyping data, 349 patients were included in the final analysis [pancreatic cancer incidence group (n = 113) vs. control (n = 236)]. The baseline characteristics of the total subjects are presented in Table 1. No significant differences were noted between the pancreatic cancer incidence and control groups. To summarize, the mean age was 52.4 years in the pancreatic cancer incidence group and 52.7 years in the control group (p from t-test = 0.991). The pancreatic cancer incidence group included 77.0% male and 23.0% female, while the control group included 73.7% male and 26.3% female, indicating no significant difference between the groups (p = 0.511). No statistical difference was noted in BMI, with the pancreatic cancer incidence and control groups showing respective mean values of 24.6 and 24.3 (p = 0.238). In addition, the two groups showed no significant difference in CA 19–9 (pancreatic cancer incidence group, 20.0 ± 2.48; control group, 8.37 ± 0.526; p = 0.346). The Chi-squared test confirmed the lack of any significant difference in the frequency of current smokers between the two groups (pancreatic cancer incidence group, 31.7%; control group, 30.3%; p = 0.116).
Table 1 Baseline clinical and biochemical characteristics of subjectsDiscriminant metabolites between the pancreatic cancer incidence and control groupsAmong the 3165 detected features from MS, 173 metabolites were identified. A heatmap comparing the abundance of identified metabolites between the pancreatic cancer incidence and control groups is shown in Additional file 1: Figure S1.
Before establishing the XGBoost model, a random seed 6:4 was applied to divide the training and the test sets (Additional file 2: Data S2). In the training set, 68 individuals from the pancreatic cancer incidence group and 141 from the control group were included. There was no significant difference in the age and sex distribution between these two groups. The proportion of current smokers in the pancreatic cancer incidence group was 30.9%, which showed a statistical difference from the control group of 30.5% (p = 0.018). In the test set, 45 individuals were from the pancreatic cancer incidence group, while 95 were from the control group. There were no significant differences in terms of age, gender, or smoking status between these two groups.
We fitted XGBoost on the training dataset (n = 209) and calculated the feature importance for identifying the effect of metabolites on the fitted model. As a result, 11 metabolites that considerably differed between the groups were selected (feature importance ≥ 4.0), as summarized in Table 2. The levels of serum eicosa-11,14,17-trienoic acid, kynurenic acid, γ-glutamyl tyrosine, lysoPE(18:0/0:0), trans-3'-hydroxy cotinine, and L-leucine were found to be elevated in the pancreatic cancer incidence group. In contrast, the pancreatic cancer incidence group had lower N(6)-methyllysine, palmitic amide, adipic acid, 9-decenoylcarnitine, and 5α-pregnane-3,20-dione levels than the control group.
Table 2 Identification of meaningful metabolites using XGBoostThe performance values of the XGBoost model on the training and test sets are shown in Additional file 2: Data S2. The training set had an accuracy of 0.952, precision of 0.983, recall of 0.868, and AUC of 0.998. In the case of the test set, an accuracy of 0.671, precision of 0.471, recall of 0.178, and AUC of 0.640 were recorded.
Metabolite-genomewide association analysisUsing 11 selected metabolites, we conducted a metabolite-GWAS. We generated a Manhattan plot to identify significant SNPs and performed linkage disequilibrium clumping with a threshold of p ≤ 5 × 10–6 to mitigate the tendency for correlation between genetic variants located nearby. Logistic regression analysis was performed to demonstrate their association with the incidence of pancreatic cancer (Table 3). Particularly, the G allele of rs2370981 mapped to NRXN3, strongly related to eicosa-11,14,17-trienoic acid, was identified as a protective allele for pancreatic cancer [OR = 0.371, p = 0.043]. Other four notable SNPs (i.e., rs59519100, rs11164375, rs72805402, and rs55870181) were all associated with a higher risk of pancreatic cancer; rs59519100 showed a significant association with γ-glutamyl tyrosine, rs11164375 with lysoPE (18:0/0:0), rs72805402 (mapped to ZNF503) and rs55870181 with L-leucine; Manhattan plots for these are presented in Additional file 1: Figure S2.
Table 3 Genome-wide association analysis of pancreatic cancer-related metabolitesNetwork analysis between metabolomic biomarkers and clinical/biochemical indicatorsWe divided the subjects into each SNP’s effect allele carrier and non-carrier groups. Then, clinical/biochemical indicators and pair metabolites of the SNP were used to create network models based on the z-score obtained after comparing the pancreatic cancer incidence and control groups for each variable and the partial correlation values between them (Fig. 1).
Fig. 1

The network between metabolites and clinical/biochemical indicators in each SNP group. ALB albumin, ALP alkaline phosphatase, ALT alanine aminotransferase, AST aspartate aminotransferase, BIL bilirubin, BMI body mass index, BUN blood urea nitrogen, CHO total cholesterol, CRE creatinine, DBP diastolic blood pressure, FBS fasting blood sugar, GGT gamma-glutamyltransferase, HDL, high-density lipoprotein, LDL low-density lipoprotein, SBP Systolic blood pressure, TG Triglyceride, URIC uric acid, WBC white blood cell. Node presents metabolite or clinical/biochemical indicators; the edge between two nodes indicates a partial correlation. The color of the nodes represents the z-score when comparing the pancreatic cancer incidence and control groups. Positive and negative correlations are represented using light-red and light-blue edges. Thicker edges represent stronger correlations between the two metabolite levels
As a result, pair metabolites of rs2370981, rs55870181, rs59519100, and rs72805402 displayed significantly different partial correlation network patterns with the clinical/biochemical indicators on comparison of the effect allele carrier and the non-carrier groups of each SNP. In summary, the risk allele carriers of rs2370981 showed several significant partial correlations that were not detected in the non-risk allele carriers; eicosa-11,14,17-trienoic acid with low-density lipoprotein (LDL) (r = 0.613, p = 0.045), alanine aminotransferase (ALT) (r = 0.632, p = 0.037), white blood cell (r = 0.816, p = 0.002), body mass index (r = -0.636, p = 0.036), and creatinine (r = − 0.67, p = 0.024). Moreover, a significant negative partial correlation between γ-glutamyl tyrosine and aspartate aminotransferase (AST) (r = − 0.237, p = 0.049) was observed in the risk allele carriers of rs59519100. Finally, l-leucine exhibited notable partial correlations with a few clinical/biochemical indications. l-Leucine and diastolic blood pressure (r = 0.18, p = 0.046) and L-leucine and glucose (r = − 0.259, p = 0.004) were identified as the risk allele carriers of rs55870181. In addition, in the non-risk allele carriers of rs72805402, l-leucine positively correlated with the blood urea nitrogen level (r = 0.137, p = 0.049) and negatively correlated with high-density lipoprotein (r = − 0.146, p = 0.035).
Mediation and moderation analysesMediation analysis, after adjusting for age and sex, was conducted on the selected metabolites and SNP biomarkers for pancreatic cancer. We noted significant outcomes in the association between γ-glutamyl tyrosine and rs59519100. Although rs59519100 showed no significant direct effect on pancreatic cancer incidence (β = 0.069, p = 0.242), γ-glutamyl tyrosine mediated the indirect effect of rs59519100 on pancreatic cancer incidence (β = 0.056, p = 0.002) with causal mediation effects of 44.6% relative to the total effect (Fig. 2).
Fig. 2
Mediation and moderation analysis. The result of the mediation analysis is presented in the blue circle and that of the moderation analysis in the red circle. Adjusting odds ratio (AOR) and confidence interval are indicated with points and lines on the graph. Variables marked with a are derived from the age- and sex-adjusting model. Variable marked with b is derived from the age-, sex-, and smoking status-adjusting model
Next, we conducted a moderation analysis after adjusting for the age and sex so as to explore the effect of smoking status as a moderator on the association among γ-glutamyl tyrosine, rs59519100, and pancreatic cancer (Fig. 2). The level of γ-glutamyl tyrosine was negatively associated with pancreatic cancer risk (β = -0.504, p < 0.001). It was maintained after adjusting the smoking status (β = − 0.508, p < 0.001). When the interaction effect (smoking status * γ-glutamyl tyrosine) was added to the linear model, this interaction term was found to be positively associated with pancreatic cancer risk (β = 0.666, p = 0.033). In other words, the smoking status affected the association between γ-glutamyl tyrosine and pancreatic cancer risk. In addition, smoking did not significantly modulate the other associations (Additional file 1: Figure S3).
Evaluation of the predictive power as a biomarker for pancreatic cancerFigure 3 depicts the prediction model using conventional risk factors and significant biomarkers identified in the present research. First, the total subjects' results (n = 349) are as follows: an area under the curve (AUC) obtained from the prediction model consisting of age, sex, and CA 19–9 was 0.569 [0.484–0.654]. The conventional model with age, sex, smoking status (never, ever, current), and CA 19–9 was 0.564 [0.480–0.649]. On adding five SNP biomarkers (i.e., rs2370981, rs59519100, rs11164375, rs72805402, and rs55870181) and four metabolic biomarkers (i.e., eicosa-11,14,17-trienoic acid, γ-glutamyl tyrosine, lysoPE(18:0/0:0), and L-leucine) to the conventional model, AUC was improved to 0.702 [0.640–0.763]. The highest AUC of 0.738 [0.661–0.815] was observed in the final model consisting of all variables (i.e., age, sex, smoking status, CA 19–9, rs2370981, rs59519100, rs11164375, rs72805402, rs55870181, eicosa-11,14,17-trienoic acid, γ-glutamyl tyrosine, lysoPE(18:0/0:0), and l-leucine). Furthermore, the predictive power of the model using variables indicating significance in mediation and moderation analyses (i.e., age, sex, smoking status, γ-glutamyl tyrosine, and rs59519100) was an AUC of 0.651 [0.588–0.713], which was within the range of predictive power of the previously described models.
Fig. 3
ROC curves for the prediction of pancreatic cancer in total subjects. Prediction models in the total subjects (n = 349), training set (n = 209), and test set (n = 140). The variables utilized in each model are different, and each model is displayed in a different color
The prediction performance trend was similar even when analyzed separately into training (n = 209) and test sets (n = 140). In both sets, the final model when metabolic and SNP biomarkers were added to the conventional model exhibited the most potent prediction power, and the predictive power of the final model was considerably improved when compared to the conventional model. The final model of the training set had an AUC of 0.843 [0.769–0.918], whereas the conventional model was 0.625 [0.526–0.725]. In addition, the final model of the test set had an AUC of 0.734 [0.618–0.850], while the conventional model showed 0.568 [0.416–0.719].
Comments (0)