Data acquisition and processing
The pan-cancer RNA sequencing data and clinical data of The Cancer Genome Atlas (TCGA) were obtained using the R package “TCGAbiolinks” (2.22.4) [12]. All sequencing data were converted to log2(TPM + 1). Similarly, the HNSCC dataset from TCGA was downloaded, including 504 tumor samples and 44 normal samples. The copy number variation (CNV) data, derived from the GDC online portal (https://portal.gdc.cancer.gov/), were acquired and processed utilizing the GISTIC algorithm. We also retrieved the immunohistochemistry results, tissue expression levels, and cell line expression data from the Protein Atlas online portal (https://www.proteinatlas.org/) [13].
Six bulk-seq datasets containing immunotherapy data were downloaded from the Gene Expression Omnibus (GEO) database (https://www.ncbi.nlm.nih.gov/geo/), including GSE145996 (melanoma), GSE91061 (melanoma and non-small cell lung cancer), GSE67501 (renal cell carcinoma), GSE126044 (non-small cell lung cancer), GSE122220 (melanoma), and GSE115821 (melanoma). Furthermore, two GEO datasets with survival data were downloaded, namely GSE65858 (HNSCC) and GSE78220 (melanoma).
In addition, single-cell sequencing datasets GSE164690 and GSE139324 of HNSCC were downloaded from the GEO database. The SCTransform method in the R package “Seurat” (4.1.1) was applied to merge the two datasets, and the SCT method was employed for normalization [14]. FindVariableFeatures function with parameters selection.method = “vst” and nfeatures = 2000 was used to select cell populations that met the requirements for subsequent analysis. The R package “SingleR” (1.10.0) was applied for cell annotation of the merged scRNA-seq dataset [15]. Then, the FindAllMarkers function with thresholds min.pct = 0.25 and logfc.threshold = 0.25 was set, and the Wilcoxon rank-sum test with this function was used to compare gene expression differences between different cell types.
Assessment of the immunologic features of the TME in HNSCC
The present study comprehensively characterized the immune features of the TME by incorporating the levels of immune chemokines, immune cell infiltration, and expression of immune checkpoints.
Immune modulators
Immune modulators were analyzed to assess the capacity of genes to regulate immunity. Charoentong et al. conducted a study on genomic and transcriptomic data obtained from 20 solid tumor samples in the TCGA dataset [16]. Their results revealed that specific genomic features were linked to distinct immune phenotypes and that these associations varied among different cancer types. Drawing on the findings of this study, Jiao Hu et al. analyzed a total of 122 immune regulators, which consisted of 42 stimulators, 23 inhibitors, 41 chemokines, 18 chemokine receptors, and 20 major histocompatibility complex (MHC) genes [17]. The above immune regulators were subsequently utilized in the exploration of immunotherapy for bladder cancer. Here, we also employed the 122 immune regulators to assess the immune characteristics of the TME.
T cell-related inflammation
In the study by Mark Ayers et al., the T cell-inflamed gene expression profile was defined as a gene set associated with T cell infiltration and activation [18]. This gene set was used to predict the clinical response to immunotherapy. At the same time, the authors classified gene expressions using the T cell-inflamed gene expression profile and demonstrated its strong correlation with the clinical response to PD-1 blockade therapy. This gene set was previously established as a useful indicator for evaluating the immune status of the TME. Accordingly, we collected 18 T cell-inflamed gene expression profiles and utilized them to evaluate the role of PERP in T cell-related inflammation.
Cancer-immunity cycle
The immunological cycle of interaction between cancer and the immune system was described by Daniel S. Chen et al. [19]. A cycle involving the release of cancer cell antigens, antigen presentation, initiation and activation, trafficking of T cells to tumors, T-cell infiltration, recognition of cancer cells by T cells, and tumor elimination was proposed. The factors affecting the immune cycle, such as TMB, T-cell phenotype and function, TME, immune checkpoints, and cancer immunotherapy, were further discussed. In our research, the cancer-immunity cycle was applied to describe the process of immune cell activation in the TME.
Immune cell infiltration
Immune cell enrichment scores were computed for each sample using eight distinct algorithms for evaluating immune cell infiltration: cibersort, epic, mcp_counter, quantiseq, single-sample gene set enrichment analysis (ssGSEA), timer, and xcell. Marker genes for key immune cell populations were collected and summarized from existing literature and were used to evaluate the correlation of the PERP gene with these markers [17].
Cell communication and enrichment
To further validate the impact of the PERP gene on the communication between tumor cells and immune cells, we performed cell communication analysis and gene enrichment analysis using single-cell sequencing data. Cell communication was inferred and quantified by combining the single-cell expression profile with known ligands, receptors, and their auxiliary factors. Significantly, interacting ligand-receptor pairs were identified using the probability of interaction between ligands and receptors and perturbation testing. Then, the cell-cell communication network was integrated by adding the number or intensity of significantly interacting ligand-receptor pairs between cell types. A circular plot was used to display the quantity and intensity of interactions. The wilcoxauc method from the R package “presto” (1.0.0) was utilized to identify differentially expressed genes (DEGs) between distinct cell types. The human species C7 immunological gene set was obtained from the R package “msigdbr”(7.5.1), followed by gene set enrichment analysis (GSEA) of specified cell subtypes using the R package “fgsea” (1.22.0) [20].
Logistic regression analysis
The logistic regression models were fitted using the R package “rms” (6.4.0) function and the R package “ResourceSelection” (0.3-5), and the coefficients were estimated using the maximum likelihood method. The significance of the coefficients was assessed using the Wald test. The goodness-of-fit of the models was evaluated using the Hosmer-Lemeshow test. A p-value less than 0.05 was considered statistically significant.
Therapeutic response assessment
Based on the research of Jiao Hu et al., gene sets related to anti-tumor immunotherapy, anti-EGFR, anti-FGFR3, and other treatments were collected [17]. Using the ssGSEA algorithm, we obtained enrichment scores of samples on these pathways, which were then used to calculate the correlation with PERP. In addition, we collected commonly used drugs for HNSCC treatment from relevant studies [21,22,23,24,25], and obtained gene information on the targets of anti-tumor drugs from the Drugbank database [26]. Furthermore, drug response data were obtained from the CellMiner online database(https://discover.nci.nih.gov/cellminer). Pearson correlation coefficients were calculated between PERP and each drug.
Utilizing metabolic gene sets for enrichment analysis in sequencing data
To investigate the relationship between the PERP gene and metabolism, 86 metabolic gene sets were obtained from the msigdb. First, the enrichment scores of all 86 metabolic gene sets were obtained using the ssGSEA algorithm. The Pearson correlation coefficient between PERP expression levels and metabolic enrichment scores was then calculated using the R package “stats”(4.2.2). Proportional hazard assumption testing and Cox regression analysis were performed on metabolic pathways with p < 0.05 in the previous correlation analysis using the survival. Samples meeting the pre-defined p-value threshold in the univariate analysis were included in the multivariate Cox regression model construction. The Cox regression models were fitted using the survival (3.3.1) function and rms (6.3-0).
Immune-related differentially expressed genes (IRDEGs)
According to the median expression of PERP, the tumor samples in the TCGA-HNSCC dataset were separated into high and low-expression groups. Differential gene selection was conducted with the R package “edgeR” (3.38.4), using selection criteria of |LogFC|>1 and p < 0.05 to identify DEGs. ESTIMATE analysis was performed on all tumor samples to determine inflammation and stromal scores. Genes that displayed a negative or positive correlation with immune and stromal scores, respectively, were selected from the upregulated and downregulated DEG groups and defined as IRDEGs.
Model construction and validation
The prediction model was built based on optimal survival-related IRDEGs. Before construction, 503 tumor samples from the TCGA-HNSCC dataset were split into training and validation sets at a ratio of 7:3. In the training set, univariate Cox regression analysis was carried out on the IRDEGs with a screening criterion of p < 0.05 to identify genes significantly associated with survival. Lasso regression was subsequently performed on the survival-related IRDEGs to select the optimal survival-related IRDEGs, and a nomogram was constructed using the above genes. The model thus built was tested for predictive power using internal validation. Receiver operating curves (ROC) and the corresponding area under the curve (AUC) values were applied to evaluate the discriminating power of the nomogram. Furthermore, the prognostic predictive ability of these genes was evaluated on an external dataset utilizing the identical model construction method. ROC and the corresponding AUC values were used to assess the discriminating ability of the nomogram.
Consensus cluster analysis
Consensus clustering is a powerful technique for improving the stability and robustness of clustering results. This method applies a variety of clustering algorithms to the TCGA-HNSCC dataset and combines the resulting clustering assignments to obtain a more stable and accurate clustering solution. By using the R package “ConsensusClusterPlus”1.60.0), the consensus clustering was applied to identify subgroups of patients based on the survival-related IRDEGs expression profiles, and it was found that the resulting clusters were more robust and biologically meaningful compared to those obtained by using a single clustering algorithm. The following nondefault parameters were used: maxK = 12, rep = 1000, distance = “euclidean,” innerLinkage = “ward.D2,” pItem = 0.8 and pFeature = 1. To determine the optimal number of clusters, the following metrics were applied: consensus matrix heatmap, consensus cumulative distribution function (CDF) curve, and delta area plot. These metrics are commonly used in consensus clustering analysis to evaluate the stability and reproducibility of clustering results.
GSVA
The GSVA package was used in this study to evaluate pathway enrichment. The “msigdb.v7.0.symbols.gmt” dataset was utilized, and the R package “gsva” (1.44.5) was employed. The gene expression matrix used in this analysis was obtained from the previous Lasso regression analysis. The following parameters were used in the GSVA analysis: mx.diff = F, verbose = F, and parallel.sz = 1. This method allowed for the assessment of pathway enrichment in a continuous and unsupervised manner and was utilized to identify pathway activity differences between different clusters.
Cell culture
DOK (Dysplastic Oral Keratinocyte) and HNSCC (FaDu, HN8, and SCC4) cell lines, along with murine-derived head and neck tumor cell line Meer and the human embryonic kidney 293T (HEK293T) cell line, were used in this study. The mouse HNSCC cell line Meer was generously gifted by Dr. Joseph Califano (University of California San Diego, USA). The remaining cell lines were acquired from the ATCC cell repository or the cell repository of the Chinese Academy of Sciences. DOK cells were cultured in 1640 medium (Gibco, USA), Tu686 in DMEM/F12 medium (Gibco, USA), and Meer in a mixed medium consisting of DMEM (Gibco, USA), F12 (Gibco, USA), Fetal Bovine Serum (Gibco, USA), and supplements including hydrocortisone, transferrin, insulin, Tri-iodo-Thyronine, mouse EGF. Other cell lines were cultured in a DMEM medium. All these media were supplemented with 10% fetal bovine serum (FBS; Gibco, USA) and 1% Penicillin/Streptomycin (C100C5, NCM Biotech, China). Cell lines were incubated in a humidified chamber at 37 ℃ in 5% CO2. All experiments were conducted with mycoplasma-free cells.
Opal multiplex immuno-histochemistry
Wax-embedded paraffin sections from formalin-fixed specimens were deparaffinized and rehydrated. Subsequently, endogenous horseradish peroxidase (HRP) was blocked using a 3% hydrogen peroxide solution for 30 min. Heat-induced epitope retrieval was performed in a citrate buffer (95℃, 5 min). Following overnight incubation with the primary antibody at 4℃, fluorescent development was carried out using the Opal 7-Color Automation IHC Kit (Akoya Biosciences, Cat # NEL821001KT) following the manufacturer’s instructions. The images were captured using the Vectra® Polaris™ Automated Quantitative Pathology Imaging System and analyzed with inForm Tissue Finder and phenoptr™ software. This study employed formalin-fixed, paraffin-embedded primary head and neck squamous cell carcinoma samples from the Xiangya Hospital Central South University. The research was carried out in compliance with the approved protocol of the Clinical Research Ethics Committee of the Xiangya Hospital Central South University (protocol 2023030315), and written informed consent was obtained from all participating patients.
Cell counting kit-8 (CCK8)
Cell proliferation was assessed using the CCK-8 kit (Beyotime, C0038) and the Cell-Light EdU Apollo 643 in vitro kit (RiboBio, C10310) as per the manufacturer’s instructions. In brief, cells were seeded at a density of 2 × 10^3 cells per well in 96-well plates with 100 µL of complete medium. At various time points, CCK-8 reagent was added, and absorbance at 450 nm was measured using a microplate reader (Biotec).
Wound healing assay
FaDu, HN8, and Meer cells were cultivated within 6-well plates. Once the cells had achieved a confluence level of 95%, precise incisions were made vertically across the monolayers. Subsequently, a serum-free medium was employed to sustain the cells. Visual documentation was conducted, and the distances between the incisions were measured at both the initial time point (0 h) and after a lapse of 24 h.
Migration assay
Migration assays were performed using Transwell chambers (8 μm; Corning, Tewksbury, MA, USA). Cells were collected, rinsed, and resuspended in serum-depleted DMEM. A suspension containing 3 × 10^4 cells/well was added to the upper chamber, while the lower chamber was filled with DMEM containing 10% FBS as a chemoattractant. Transwell chambers were incubated at 37 °C for 48 h to allow cells to migrate to the underside of the filter. Migrated cells were fixed with 4% paraformaldehyde, stained with 0.1% crystal violet, and quantified under a microscope.
Mouse tumor model and treatment
The research protocol involving animal studies was approved by the Institutional Review Committee of Xiangya Hospital, Central South University (protocol XY20240711004). Male Nude mice and C57BL/6 mice aged 4–6 weeks were obtained from Hunan Slake Jingda Experimental Animal Co., Ltd. and housed at the Department of Animal Science, Central South University. PERP knockout or control Meer (1 × 106) cells were subcutaneously injected into the dorsal flank of each nude or C57BL/6 mouse. At the end of three or five weeks, the mice were euthanized, and the tumors were harvested and weighed. For the evaluation of the combination treatment group. When the tumor size reached 100mm3, 100 µg mouse anti–PD–1 antibody (BE0146, Bio X Cell) or IgG control (BE0089, Bio X Cell) was given via intraperitoneal injection (100 mg/injection every 3 days).
Flow cytometry
Employing flow cytometry, we analyzed the composition of CD8 + T cells derived from lymph nodes and tumor tissue. Tumors and lymph nodes were dissected, minced, and digested with 1 mg/ml Collagenase/Dispase (Sigma-Aldrich, 10269638001) and 1X DNase I (Qiagen, 79254) at 37 °C for 30 min. Dissociated tumor and lymph node mononuclear cells were filtered through a 70 μm filter to achieve a single-cell suspension before staining for flow cytometry analysis. Cells were stained using Anti-CD8a PE (eBioscience, Cat#12-0081-82, 1:100), anti-CD3e PE-Cyanine7, (eBioscience, Cat#25-0037-42, 1:100), anti-CD3 PerCP-Cyanine5.5, (eBioscience, Cat#45-0037-42, 1:100), anti-PD-1 APC/Cyanine7, (BioLegend, Cat#135224, 1:100), anti-Granzyme B FITC, (eBioscience, Cat#11-8898-82, 1:100), and cells were fixed and permeabilized with True-Nuclear™ Transcription Factor Buffer Set(Biolegend, Cat#424401), and dead cells were stained with Ghost Dye™ Violet 510 (Cytek Biosciences, Cat# SKU 13-0870-T100) before fixation and permeabilization and excluded during analysis. Cells were imaged on a BD Biosciences LSRFortessa and analyzed with Flowjo.
In vivo delivery of isotopically labelled glucose
Glucose-derived carbon was traced in vivo using 13C6-labelled glucose (Cambridge Isotope Laboratories, CLM-1396). Specifically, mice bearing tumors were generated as described above, 5% glucose was injected directly into the tumours 21 days after implantation at 5 mg/kg.
Sample collection and metabolite extraction
Tumors were dissected in ice-cold sterile PBS and snap-frozen in liquid nitrogen and stored at − 80 °C for further analyses. 3–10 mg per thymus tissue was added to pre-chilled Lysis Buffer containing metal beads to a final concentration of 15 mg/ml and then homogenized. After 30 min of vortex at 4 °C, suspensions were then centrifuged at 18,300 g for 10 min at 4 °C. The supernatant containing metabolites was applied for metabolomics.
LC-MS analysis and metabolite identification
Metabolomics analysis was conducted using a ThermoFisher Dionex UltiMate 3000 UHPLC system coupled with a Q Exactive HF MS. A Kinetex C18 column (2.1 × 150 mm, 1.7 μm) was employed with a flow rate of 0.45 ml/min, column oven temperature set at 45 °C, and sample maintained at 4 °C with an injection volume of 10 µl. Mass spectrometry parameters were set as follows: Resolution 60,000, Scan Range 65–900 m/z, Maximum injection time 200 ms, Automatic gain control (AGC) 3 × 106 ions, Sheath gas 45, Auxiliary gas 15, Sweep gas 0. Samples were injected randomly, and every 10 samples were followed by a quality control (QC) sample injection. LC-MS data analyzed using customized El-Maven software (version 0.12). Compounds were identified by m/z and retention time (RT). Peak intensities were determined by calculating the average of the three scans surrounding the “AreaTop”.
Co-immunoprecipitation (co-IP) and western blot
Cells were collected and lysed by 1mL lysis buffer (Beyotime, China, containing 20mM Tris (pH7.5), 150mM NaCl, 1% Triton X-100, sodium pyrophosphate, β-glycerophosphate, EDTA, Na3VO4 and leupeptin) with 1 mM PMSF on ice for 0.5 h. Then, cell lysate was centrifuged at 13,200 rpm at 4 °C for 15 min. Then, protein A/G agarose beads (Thermo Fisher Scientific, USA) and primary antibody were added to the supernatant and incubated at 4 °C overnight. The beads were washed with lysis buffer on ice for six times, and the beads were then subjected to western blot analysis [27]. The antibodies used for immunoblotting were listed as follows: anti-PERP (ab129083, Abcam), anti-GAPDH (ab9485, Abcam), anti-Lamin B (ab176880,Abcam), anti-PD-L1 (28076-1-AP, Proteintech), anti-p65 (Cat#8242T, CST), anti-Phospho-p65 (Cat# 3003T, CST).
CD8 T cell-mediated cytotoxicity assay
CD8 T cells were isolated from healthy human peripheral blood using a magnetic bead-based isolation kit (STEMCELL, Cat#17953) and activated with anti-CD3/CD28 antibodies (STEMCELL, Cat#10971) plus IL-2 (1000 IU/mL) for 72 h. Target Fadu cells were subjected to four conditions: sgNC, sgPERP, 2-DG treatment, or sgPERP with 10 mM glucose supplementation. These cells were then labeled with CFSE (Biolegend, Cat#423801) and co-cultured with activated CD8 T cells at varying effector-to-target (E: T) ratios (1:1, 6:1, 12:1, 25:1) for 24 h. After co-culture, all cells were harvested, stained with 7-AAD (Biolegend, Cat#420403), and analyzed by flow cytometry to determine dead tumor cells based on CFSE + 7-AAD + populations.
RNA sequence
Total RNA was prepared by Trizol (Invitrogen, Cata No. 15596026). RNA sequence was performed by Novogene (Beijing, China) on the illumine sequence platform. RNA degradation and contamination were monitored on 1% agarose gels and RNA purity was checked using the NanoPhotometer spectrophotometer (IMPLEN, CA, USA), RNA integrity was assessed using the RNA Nano 6000 Assay Kit of the Bioanalyzer 2100 system (Agilent Technologies, CA, USA). The clustering of the index-coded samples was performed on a cBot Cluster Generation System using TruSeq PE Cluster Kit v3-cBot-HS (Illumia) according to the manufacturer’s instructions. The library preparations were sequenced on an Illumina Novaseq platform and 150 bp paired-end reads were generated.
Statistical analysis
The significance of PERP expression in paired and non-paired samples was determined using the Wilcoxon signed-rank test and Wilcoxon rank-sum test, respectively. The prognostic worth of PERP was established via Univariate Cox regression analysis and the Kaplan-Meier method. The Log-rank test was applied in estimating the disparity in survival curves. The relationship between PERP and other factors was examined for statistical significance via the Spearman correlation analysis. The significance of comparisons across two and multiple groups was determined through the t-test and one-way ANOVA, respectively. R 4.3.0 software was employed for all statistical computations, with a P value of less than 0.05 deemed significant.



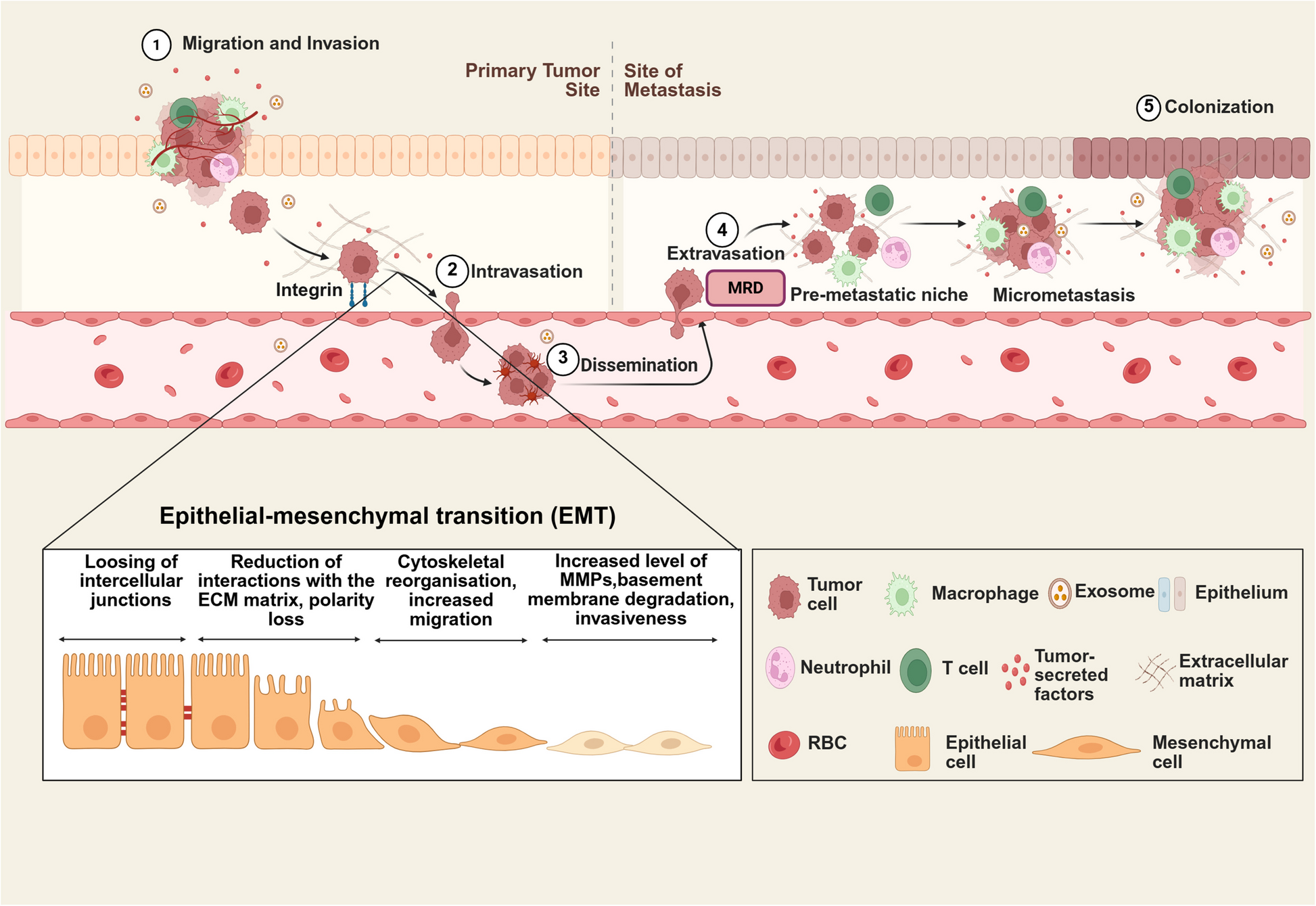
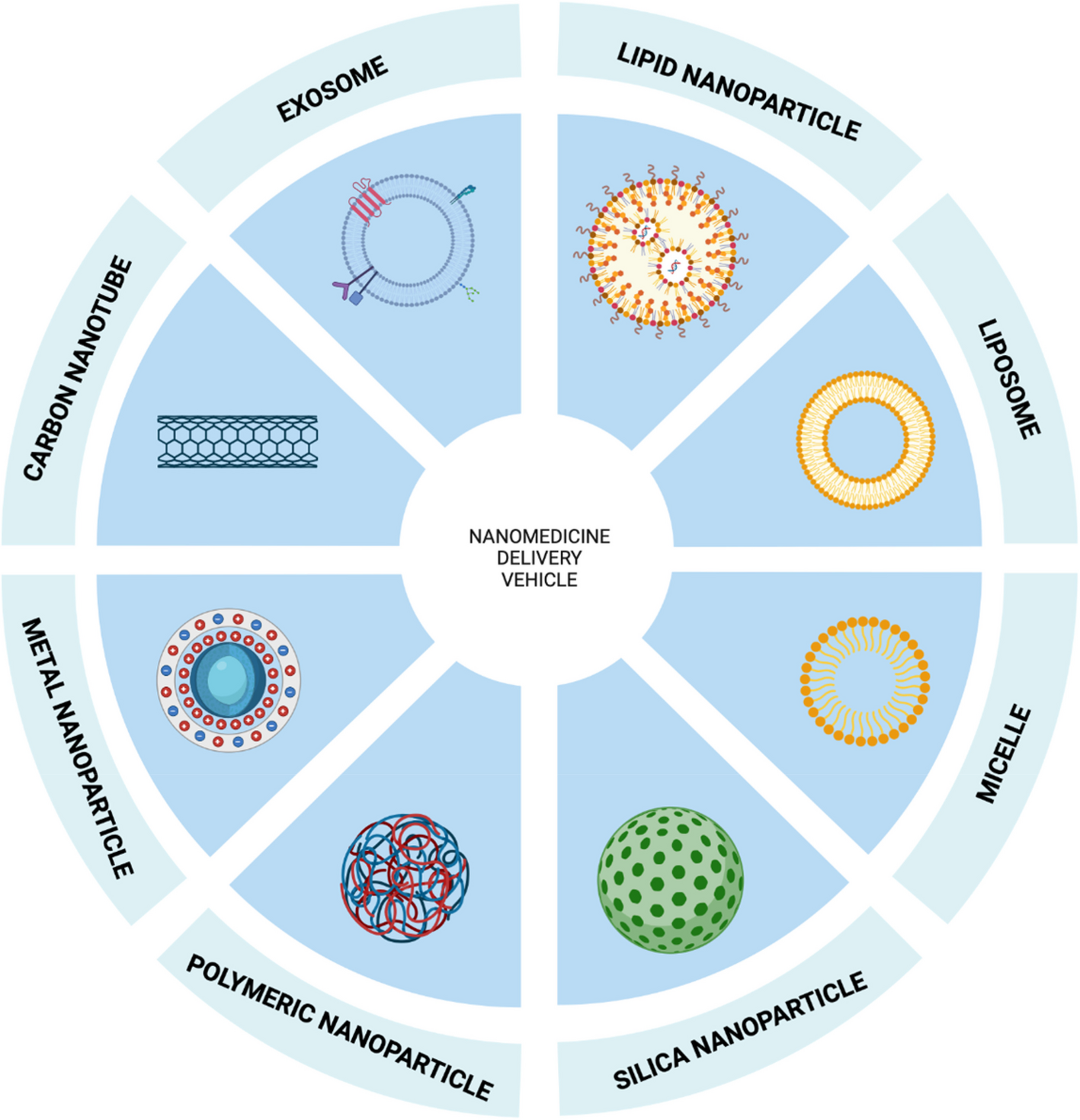
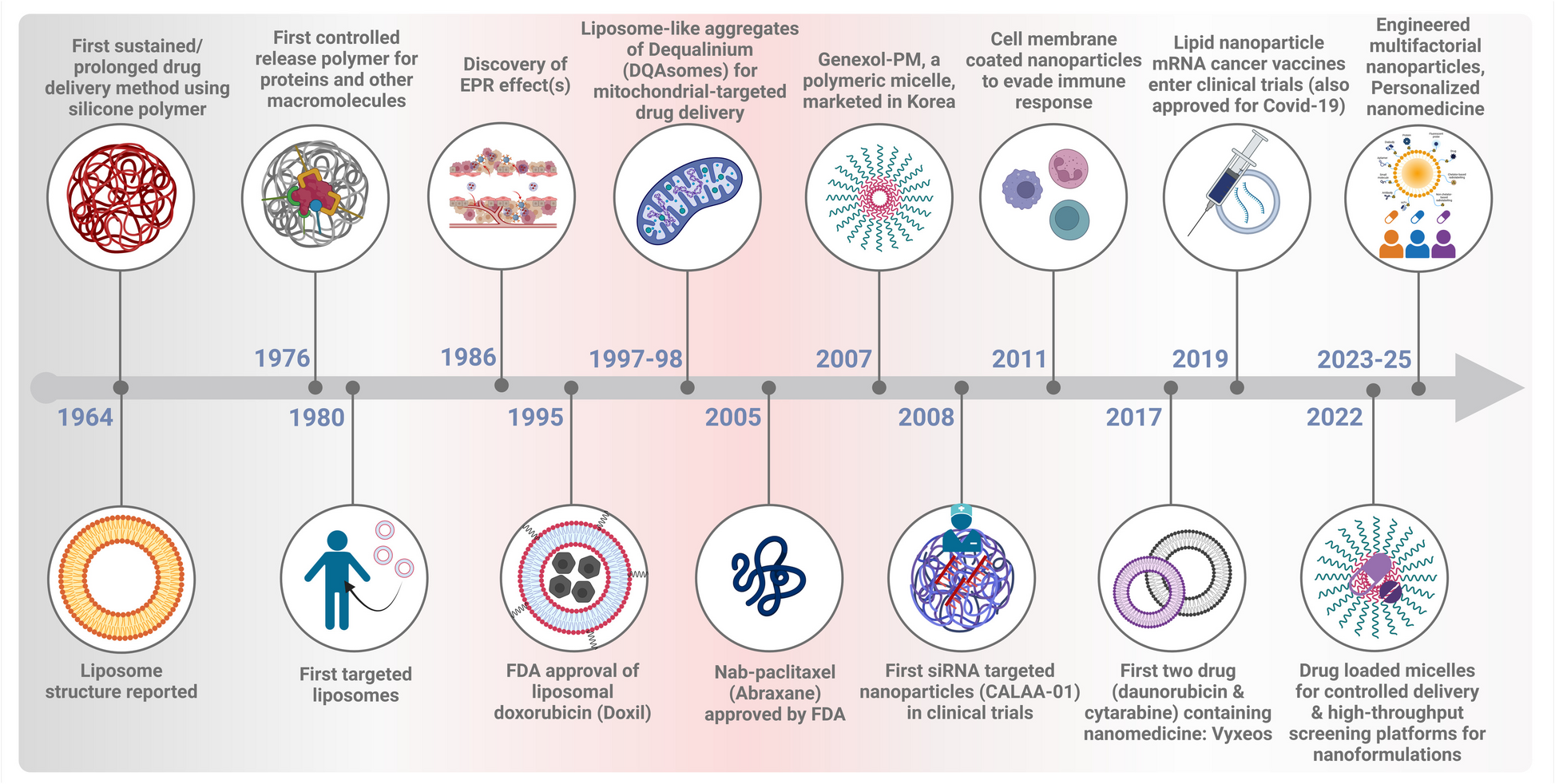
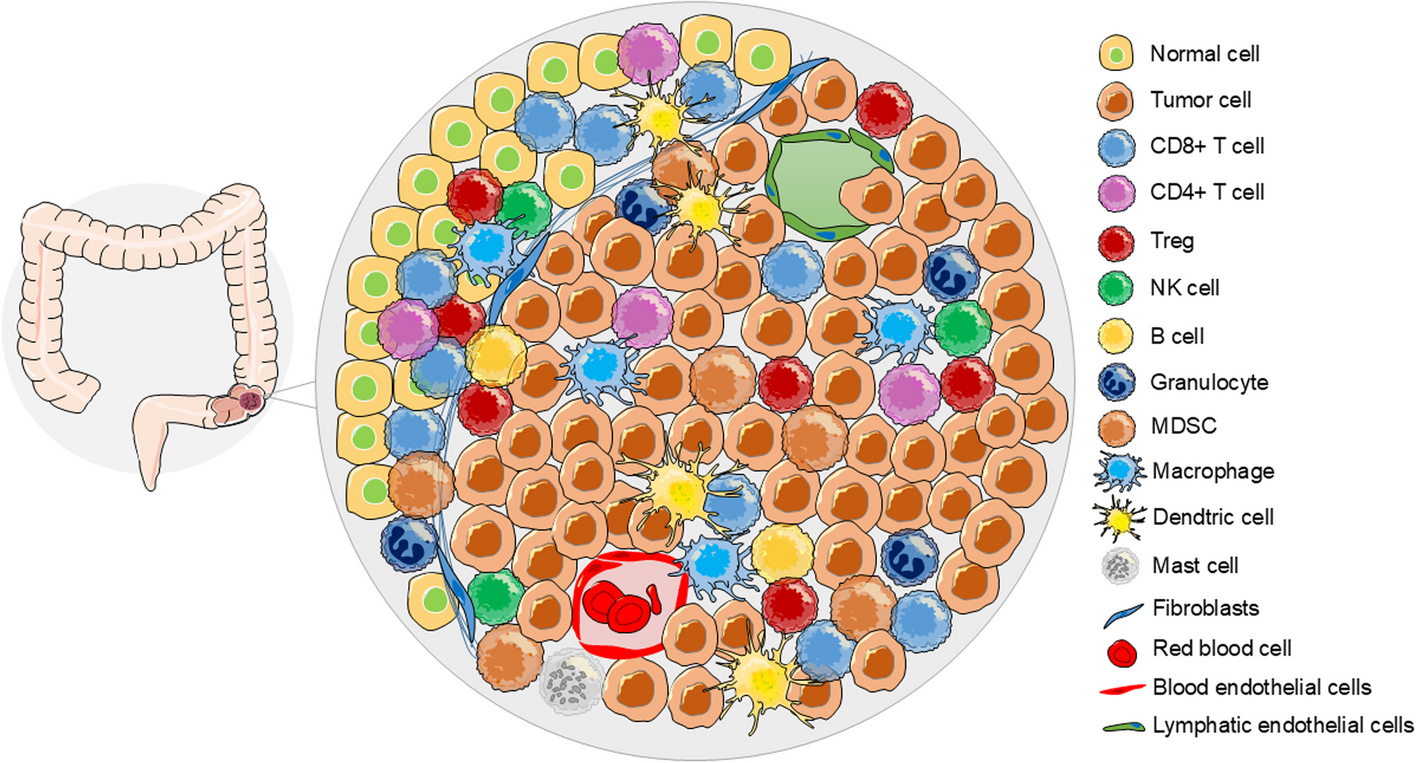
Comments (0)