Developing the CAT
The CAT was developed based on an open-source online adaptive testing platform Concerto developed and maintained by the University of Cambridge Psychometrics Centre (Available from: https://concertoplatform.com/about) [23]. The essential elements of the CAT involved item parameters calibration, initial item, item selection method, ability estimation method, and stopping criteria [24].
Item parameters calibration
The item bank of the CAT was the same as the paper-and-pencil version of mCOPD-PRO. Item parameters including discrimination (a) and difficulty (b) were estimated using graded response model of IRT. Before modelling, the core assumptions (unidimensionality, local independence, and monotonicity) were evaluated. The unidimensionality assumption was assessed using both exploratory and confirmatory factor analysis. For the former, a ratio of the eigenvalue for the first factor to the second factor in excess of four was supportive of the unidimensionality assumption [25]. As for the latter, the recommended criteria for fit indices were as follows: (1) the comparative fit index and non-normed fit index were close to 0.90; (2) the incremental fit index was close to 0.95; and (3) the standardized root-mean-square residual and root-mean-square error of approximate (RMSEA) were close to 0.08 [26, 27]. A Chen and Thissen’s index of > 0.30 implied possible local dependence [28]. The monotonicity was considered acceptable if the scalability coefficients (Hi) for the items were > 0.30 [29]. The data were from 366 patients with COPD in the phase of validation of the paper-and-pencil version of mCOPD-PRO [9]. The mean age was 66 years; 279 cases (76.2%) were males and 87 cases (23.8%) were females.
Initial item and item selection method
Item selection is dependent on the examinee’s responses to a given item. The random and maximum Fisher information (MFI) methods were adopted to select items. The former is simple and effective, and selects items randomly, while the latter selects items based on the information of items. Thus, the initial item selected by the random method is random, while that selected by the MFI method is the one with the maximum information.
Ability estimation method
As a key component of CAT, the ability estimation method not only affects the accuracy of ability estimation, but also affects the efficiency of item selection and the determination of stopping rule. In this study, the maximum likelihood estimation, one of the most widely used ability estimation method, was used to conduct ability estimation.
Stopping criteria
Generally speaking, the stopping criteria of CAT involves fixed length and standard error of measurement (SEM). The measurement accuracy may vary among subjects with different fixed lengths, and the fixed SEM can best reflect the core idea of CAT. In this study, the SEM of ≤ 0.30 was determined as our stopping criteria, which meant that the test was terminated if the pre-specified value of SEM was met or the item bank was exhausted [10].
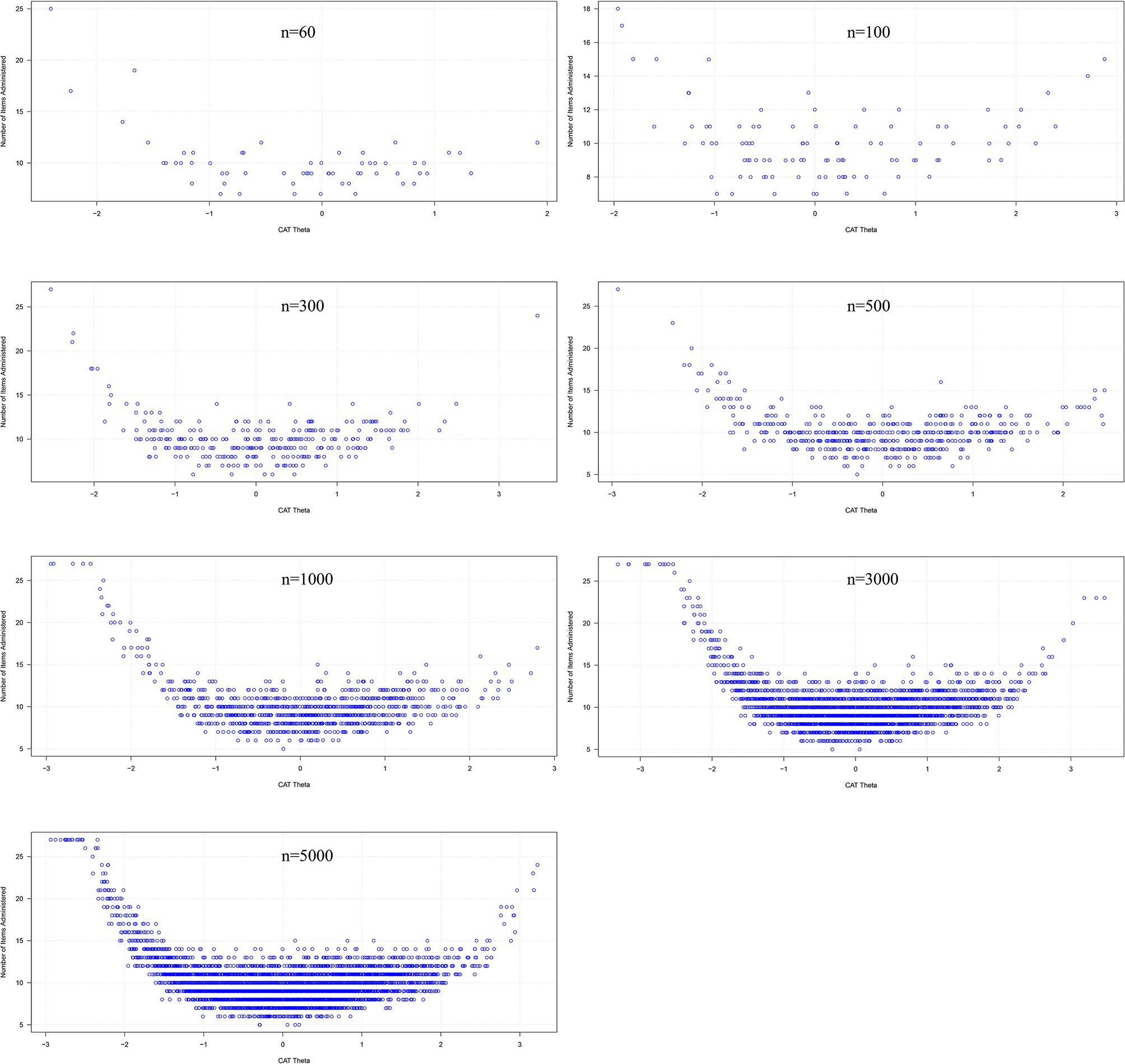
Simulation test
The CAT simulation was performed to determine the appropriate sample size for the validation of the CAT based on the true participants’ responses data from the phase of validation of the paper-and-pencil version of mCOPD-PRO [9]. R commands for the simulated data of different sample sizes (60 cases, 100 cases, 300 cases, 500 cases, 1000 cases, 3000 cases, and 5000 cases, respectively) were generated using Firestar version 1.5.1, and then ran in R version 3.5.1. The CAT simulation settings for Firestar version 1.5.1 were as follows: (1) for the IRT model, graded response model was used; (2) for the item selection method, random and MFI methods were used respectively; (3) for the stopping criteria, the maximum SEM was 0.30; and (4) for the simulated data, the mean was specified as zero with the standard deviation of one.
Validating the CAT
There is no consensus regarding the validation of CAT for PRO instruments. In our study, the reliability was estimated based on IRT method, while the content and criterion validity were evaluated referring to classical test theory method. It was assumed that the response to each item of the CAT was consistent with that of the paper-and-pencil version of mCOPD-PRO in the phase of validation [9]. However, the number of items selected by the CAT might be less than that of the paper-and-pencil version of mCOPD-PRO.
Reliability
The measurement reliability (r) was calculated through the SEM of the CAT. The relationship between SEM and measurement reliability (r) is inversely proportional function (assuming that the mean ability of the subjects is zero and the standard deviation is one). The formula: SEM = (1-r)1/2; that is, the measurement reliability (r) = 1-SEM2 [10, 24].
Content validity
The content validity of the CAT was assessed based on the content validity of the paper-and-pencil version of mCOPD-PRO in the phase of validation [9].
Criterion validity
The COPD assessment test and modified Medical Research Council dyspnea scale (mMRC) recommended by the Global Strategy for the Diagnosis, Management, and Prevention of Chronic Obstructive Pulmonary Disease were both used as gold standard [1, 30, 31]. The criterion validity was evaluated using correlation coefficient between the test result theta of the CAT and COPD assessment test and mMRC scores. The correlation coefficient of ≥ 0.40 was considered acceptable [9].
Statistical analysis
Continuous data were expressed as the mean ± standard deviation or median (interquartile range), while categorical data were presented as frequencies (percentages). The confirmatory factor analysis was conducted using LISREL version 8.70 (Scientific Software International, Inc., Chicago, IL, USA). The local independence and monotonicity were tested using “TestAnaAPP” and “mokken” packages in R (The R Foundation, Vienna, Austria), respectively. The IRT analysis was performed using MULTILOG version 7.03 (Scientific Software International, Inc., Chicago, IL, USA), and the CAT simulation was conducted using Firestar version 1.5.1 (Northwestern University Feinberg School of Medicine, Chicago, IL, USA) and R version 3.5.1 (The R Foundation, Vienna, Austria). Additionally, descriptive statistics, exploratory factor analysis, calculation of measurement reliability (r), correlation analysis, and independent sample t-test were conducted using SPSS version 22.0 (IBM Corporation, Armonk, NY, USA).



Comments (0)