
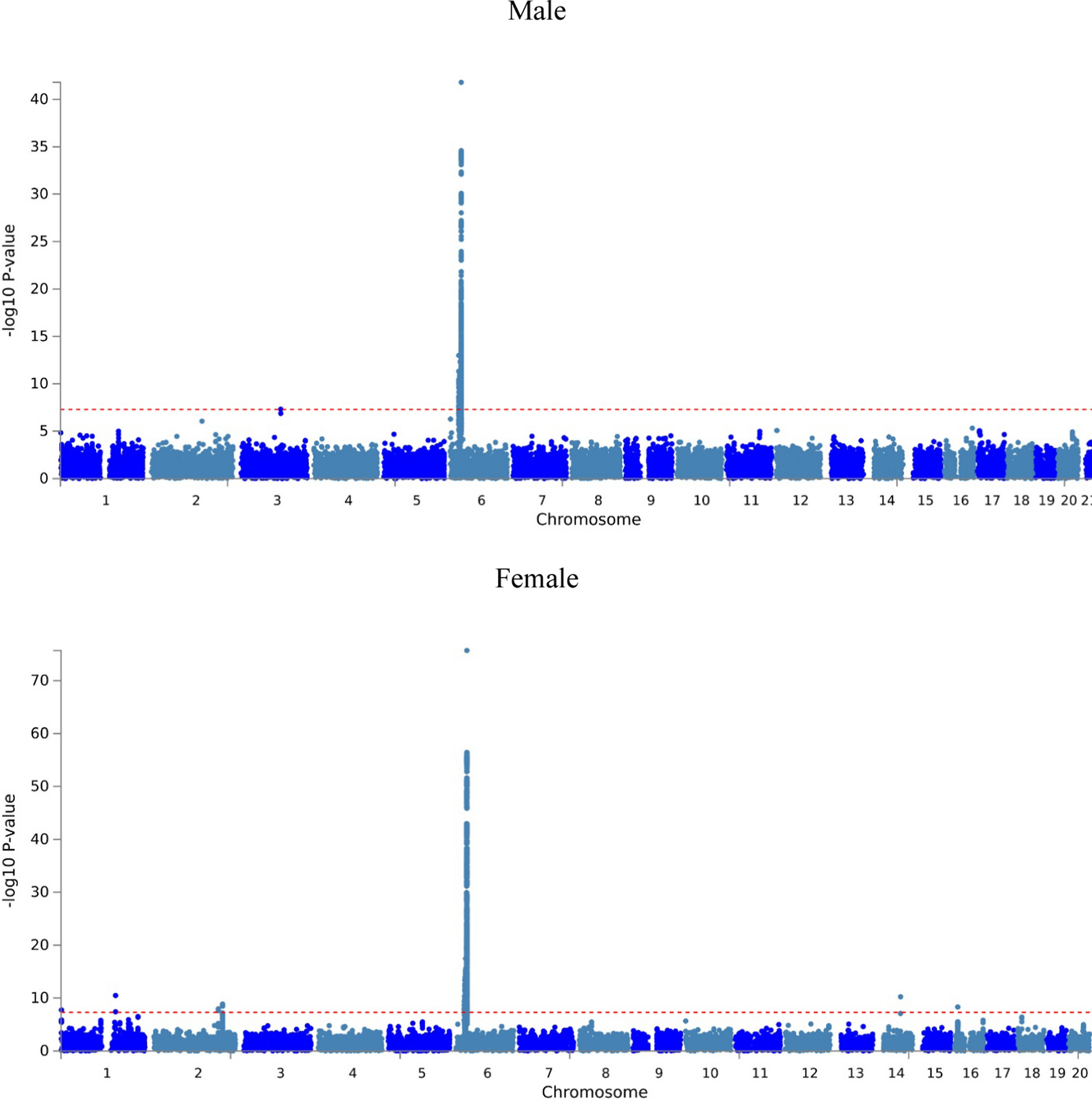
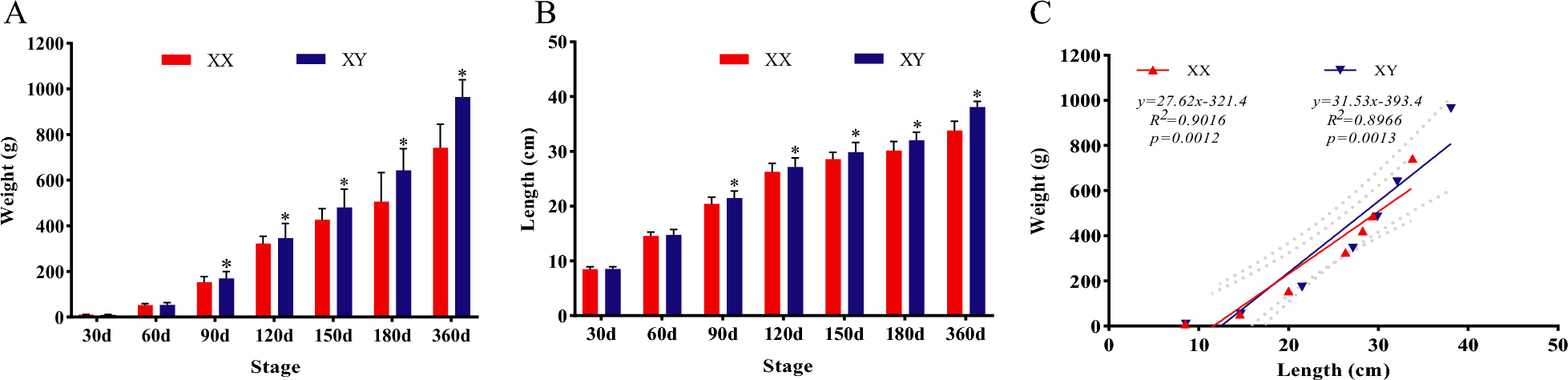
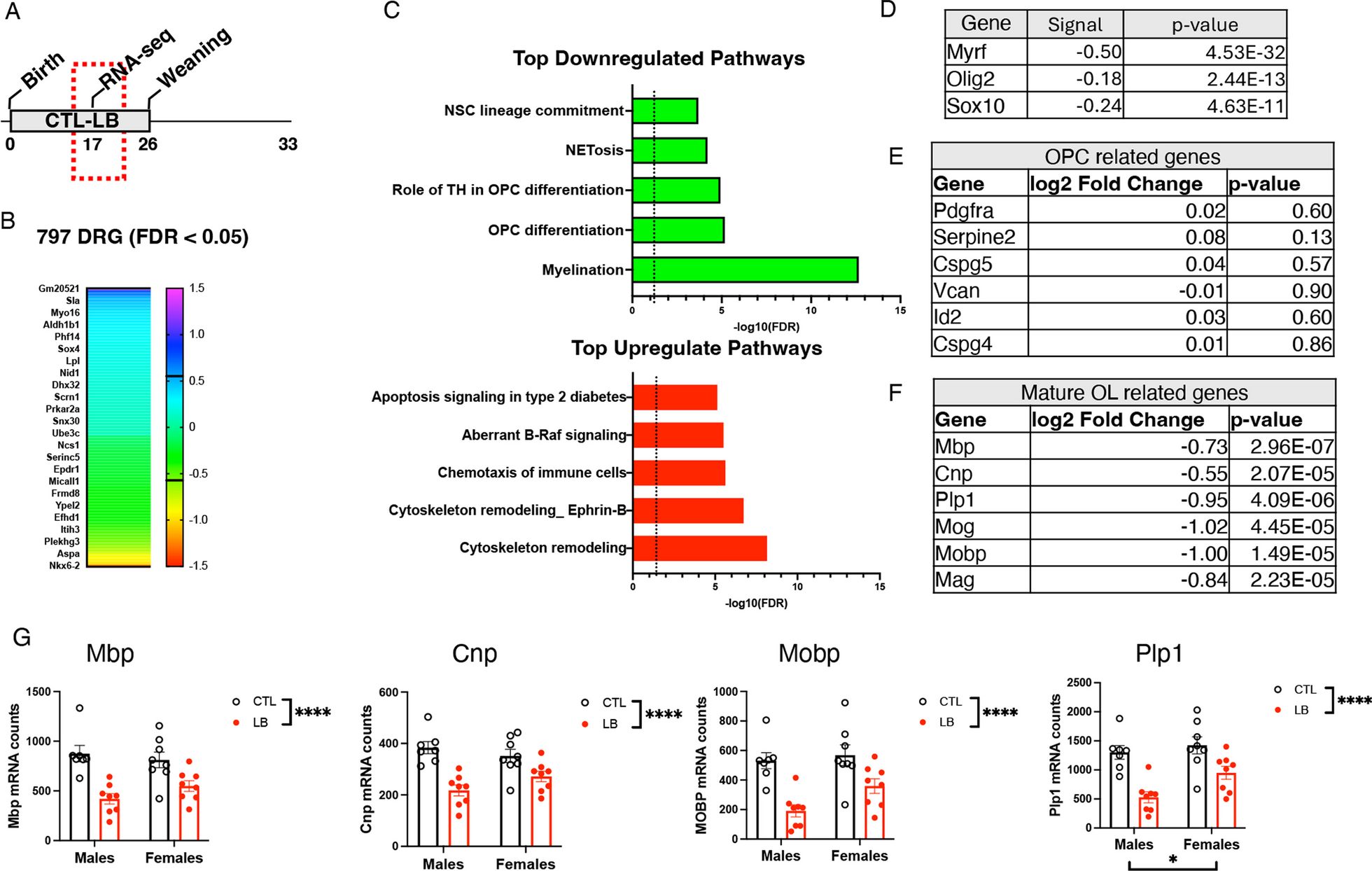
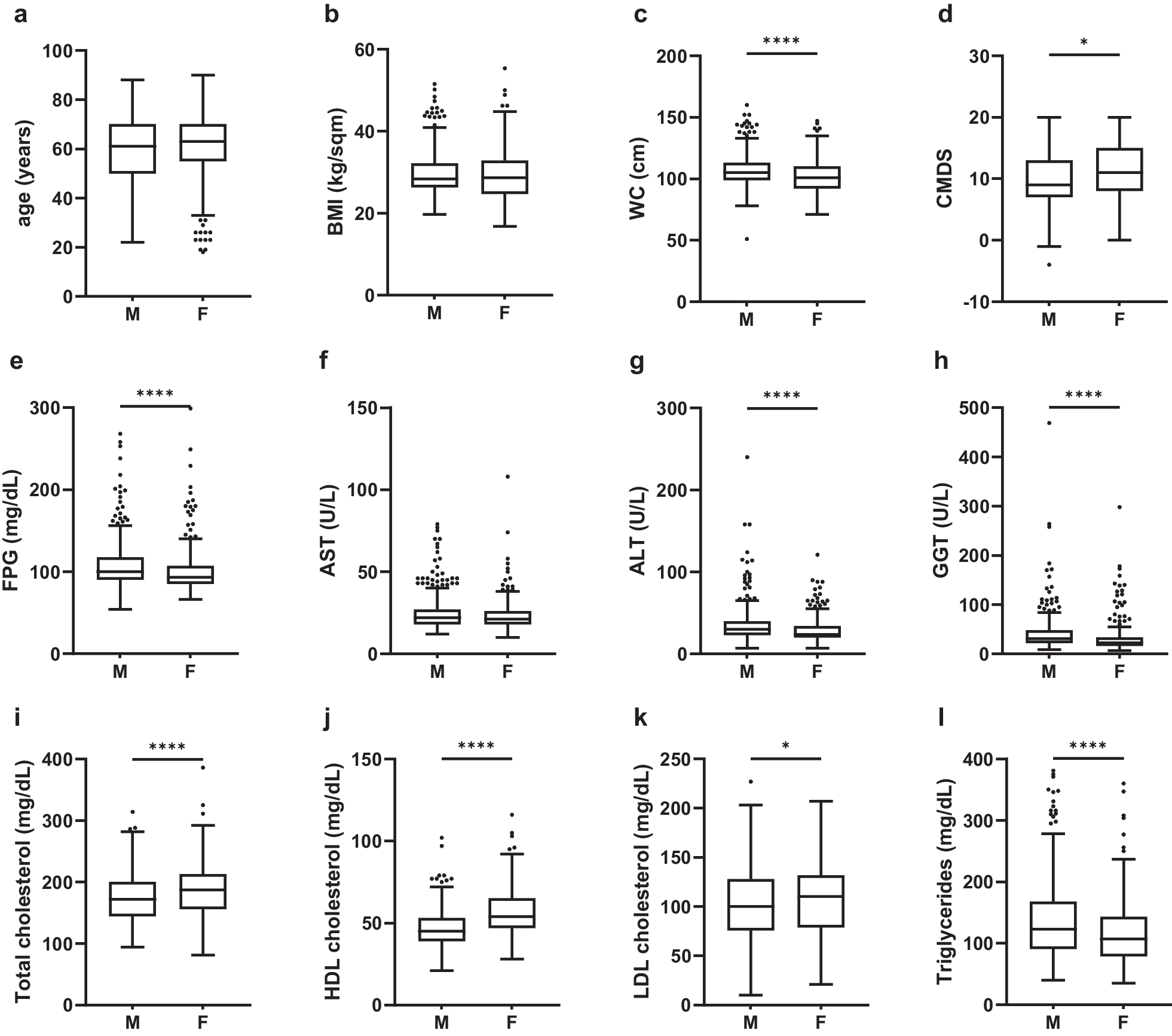
Remember me


Males exhibited larger raw GMvol than females in the 18 areas comprised in the SENT_CORE network (Fig. 2). Thus, the males’ distributions of the robust z-scores of these raw volumes were significantly shifted towards higher values (median shift = 0.78z, p < 0.001 in all cases; Additional file 1: Table S1B), so in all these brain areas the majority of males had GMvol scores that were larger than the females’ median (Cohen’s U3 range = 65.31–92.52%) and the males and females’ distributions exhibited generally “low” levels of overlap (median = 49.21%; see Fig. 2 and Additional file 1: Table S1C). Moreover, statistically significant and, in most cases, “large” M > F differences were found at all decile values of these 18 distributions (range \(\widehat\)= 0.27–1.20, median \(\widehat\)= 0.80, p < 0.01 in all cases; Fig. 2 and Additional file 1: Table S1D). Accordingly, the probability that a randomly picked male would exhibit a larger GMvol score than a female (PS-M) was found to be larger than its counterpart (PS-F) in each and every brain area, hence resulting in Cliff’s delta values spanning between 0.22 (T2_3) and 0.62 (STS2) with a median value of 0.47 (p < 0.001 in all cases; Fig. 2 and Additional file 1: Table S1E). In contrast, across all the brain areas considered, females and males seemed to exhibit a similar shape and spread as no statistically significant differences in their respective skewness, kurtosis, or IQR estimates were found (Additional file 1: Table S1F).
Fig. 2.
Univariate sex differences and similarities in the raw dataset. Panels depict the distributions of females (red) and males (blue) z-scores and report the percent of mutual overlap and the estimated Cohen’s U3 values in each of the 18 brain areas included in the SENT_CORE network. Under these density-based depictions: the tenths (deciles) of the same distributions of males (top) and females (bottom) are displayed as colored rectangles, whereas black solid segments are used to denote statistically significant differences in the values of the deciles that define these tenths. At the top of the panels, the probability of superiority of males (blue) and females (red) and the corresponding Cliff’s delta statistic are reported (including the associated p-value only in those cases in which it remained statistically significant after multiple comparisons correction) (M = males, F = females, PS = probability of superiority, O = overlap)
Taken together, these results indicate that males and females exhibit widespread and “large” differences in their respective amounts of raw GMvol in the 18 areas of the SENT_CORE network. However, as summarized in Table 2, the sizes of the observed sex differences in local GMvol were highly correlated with the variance accounted for by TIV in each of these 18 brain areas (see R2 and other regression outputs in Additional file 1: Table S1G), hence indicating that differences in raw GMvol are largely dependent on gross morphology differences between females and males.
Table 2 Influence of TIV in the observed differences and similarities in the raw and in the PCP datasetsControlling for TIV-related variation resulted in a suppression of most, but not all, of the previously observed sex differences in local GMvol. Thus, in the PCP dataset (Fig. 3), the robust z-scores’ distributions of females and males were very much alike and WMW tests revealed statistically significant differences after p-values correction in just 2 brain areas (T2_3 and F2_2), in both of which females exhibited slightly larger scores than males (estimated shifts: 0.28 and 0. 25z, respectively; p < 0.05 in both cases; Additional file 1: Table S2B). Accordingly, Cohen’s U3 values were close to the 50% in all brain regions and all the females and males’ distributions exhibited a “large” degree of mutual overlap (median = 87.42%, see Fig. 3 and Additional file 1: Table S2C). As a result, few statistically significant differences were found when comparing the deciles of these distributions (Fig. 3, Additional file 1: Table S2D). These differences were again “small” in size and their direction varied for different brain areas. Thus, F > M differences were predominant and specifically found in all deciles’ values of T2_3, in the D2-D9 values of F2_2, and the D3 value of SMA2 (range \(\widehat\)= − 0.2, − 0.39; median = − 0.28), whereas M > F differences where only found for the D9 (\(\widehat\)= 0.39) and the D2 (\(\widehat\)= 0.27) values of STS1 and STS2, respectively (Fig. 3, Additional file 1: Table S2D). Accordingly, in most areas the probability that a randomly picked female (PS-F) would exhibit a larger GMvol score than a male was similar to its counterpart PS-M in most brain areas, and, once again, only in T2_3 and F2_2 the difference between PS-M and PS-F achieved statistical significance (Cliff’s delta = 0.16 and 0.14, respectively; p < 0.05; Fig. 3, Additional file 1: Table S2E). Finally, no statistically significant sex differences in shape (skewness and kurtosis) nor spread were observed in any brain region (Additional file 1: Table S2F).
Fig. 3
Univariate sex differences and similarities in the PCP dataset. Panels depict the distributions of females (red) and males (blue) z-scores and report the percent of mutual overlap and the estimated Cohen’s U3 values in each of the 18 brain areas included in the SENT_CORE network. Under these density-based depictions, the tenths of the same distributions of males (top) and females (bottom) are displayed as colored rectangles, whereas black solid segments are used to denote statistically significant differences in the values of their deciles. At the top of the panels, the probability of superiority of males (blue) and females (red) and the corresponding Cliff’s delta statistic are reported (including the associated p-value in those cases in which it remained statistically significant after multiple comparisons correction) (M = males, F = females, PS = probability of superiority, O = overlap)
Taken together these results suggest that, when the contribution of gross morphology differences between females and males to local brain volumes is ruled out, females and males are very similar regarding their GMvol in the majority of the brain regions of the SENT_CORE network. Thus, only in two brain areas (T2_3 and F2_2) “small” but consistent F > M differences were confirmed through distinct statistical approaches. As could be expected, the size of these differences was uncorrelated with TIV (Table 2) and TIV did not explain any variance in these brain sites (Additional file 1: Table S2E).
Multivariate sex differences and similaritiesEstimating multivariate sex differences and similarities from classification probabilitiesTo evaluate the possible multivariate sex differences and similarities in the SENT_CORE network as a whole in the raw and PCP datasets, the information of its 18 brain regional components was condensed into a unidimensional metric space defined by the classification probabilities (Pclass scores) provided by two independent logistic regression models. The reference category of each model was chosen according to the direction of the observed univariate differences of each dataset, so higher Pclass scores were associated with larger amounts of raw or TIV-adjusted GMvol, respectively (see details in Sect. 2.3.2). The fitted LR models identified a statistically significant relationship between the predictors and sex categories in both the raw (χ2(16.36) = 324.34, p < 0.001) and the PCP (χ2(14.12) = 59.48, p < 0.001) datasets. The discrimination indexes associated with these LR models indicated that multivariate sex differences would probably be “large” in the raw dataset (R2 = 0.55, C = 0.89, Dxy = 0.79) but “small” in the PCP dataset (R2 = 0.11, C = 0.68, Dxy = 0.37). This initial inference was confirmed by all subsequent analyses.
Figure 4A displays the distributions of the males and females’ pclass-scores obtained when using the raw amounts of GMvol. Both males and females exhibited highly skewed and opposing distributions (skewnessM = − 0.99, skewnessF = 1.01, p < 0.001), with most of the females accumulating near the lower bound of the Pclass continuum, and most of the males accumulating near the upper bound. These distributions did not seem to differ in kurtosis (kurtosisM = 3.17, kurtosisF = 3.10, p = 0.905) or spread (IQRM = 0.35, IQRF = 0.32, p = 0.417) but they clearly did in location, hence exhibiting a “small” degree of mutual overlap (25.13%). Thus, the probability that a randomly chosen male would have a Pclass score higher than that of randomly chosen female was “large” (PS-M = 0.89) and significantly higher than its counterpart (PS-F = 0.11; Cliff’s delta = 0.78, p < 0.001; Additional file 1: Table S3A).
Fig. 4
Multivariate sex differences and similarities estimated from Pclass scores in the raw and PCP datasets. A and E Scaled density function for the males (blue) and females’ (red) distributions of the Pclass scores in the raw and PCP datasets. Within each panel, the percent of overlap (O) as well as the probabilities of superiority for males and females (PS) as well as the p-value associated and an R2 effect size index derived from the comparison of these PS values using Cliff’s delta are provided. Panels B and F Cumulative density functions (CDF) of Pclass scores of males (blue) and females (red), along with the tenths of these distributions (colored rectangles), the decile values (vertical lines). The size of the estimated sex differences in these deciles is also included (see further details of these comparisons in Additional file 1: Table S3C). C and G Scaled density functions of all the pairwise differences between females and males. Within each density plot, two different areas are colored according to the direction of these differences (F > M, red; M > F, blue) and, at the top of the panel, the percent of pairwise differences favoring the reference sex category (males in the raw dataset, females in the PCP dataset) as well as its 95% CI are included. Each of these two panels also includes the CDFs of pairwise differences’ distributions (black line), the tenths of these distributions (colored rectangles) and the size of the estimated deciles’ differences. D and H Scatterplots depicting the bivariate relationship (quantified by a robust analog of Pearson’s r correlation index) between the Pclass and TIV scores (M = males, F = females)
In contrast, when Pclass scores were calculated from TIV-adjusted GMvol estimates (PCP dataset; Fig. 4E), the males and females’ Pclass-scores were much more symmetrically distributed (skewnessM = − 0.16, skewnessF = 0.16, p = 0.298), and both of them occupied the most central regions of the Pclass continuum without apparent differences in kurtosis (kurtosisM = 2.77, kurtosisF = 2.61, p = 0.508), or spread (IQRM = 0.16, IQRF = 0.16, p = 0.744) and showing just slight differences in location. Consequently, both distributions exhibited a substantial degree of overlap (60.03%) between them, and the PS of the reference sex category (in this case, the females) was significantly different but not much larger than that of the alternative sex category (PS-F = 0.68, PS-M = 0.32; Cliff’s delta = 0.36, p < 0.001; Additional file 1: Table S3A).
To delve deeper into the characterization of these multivariate sex differences, Fig. 4B displays the empirical cumulative distribution functions (CDFs) of the males’ and females’ Pclass-scores obtained in the raw dataset, along with their respective decile values. This figure makes it possible to compare females and males in three complementary ways (see Sect. 2.3.2), leading to the following main observations: 1) 80.61% of females and 82.93% of males were below and above the 0.5 cutoff value classically used in classification studies, then resulting in a classification accuracy of 81.77%; 2) 96.26% of males had Pclass scores that were higher than or equal to the median Pclass score of the females (Cohen’s U3; Additional file 1: Table S3B); 3) Statistically significant M > F differences were found at all decile values (range \(\widehat\)= 0.32–0.6, p < 0.001 in all cases; Additional file 1: Table S3C). Accordingly, when all M-F pairwise differences were calculated (Fig. 4C), M > F differences were far more frequent (89%) and expectable (86–92%) than F > M differences and, in the majority of the cases, these observed differences were “moderate” to “large” in size (e.g., 50% of the differences had a size equal of larger than 50% of the maximum possible). However, individual Pclass scores were highly correlated to TIV (rho = 0.80, p < 0.001; Fig. 4D), hence suggesting that sex differences estimated from these Pclass scores could be largely driven by the differences between males and females in TIV values.
In contrast, as shown in panels F-G of Fig. 4, the same comparisons indicated that when TIV-related variation was statistically controlled (see Panel H of the same figure), multivariate sex differences were much smaller. More specifically: (1) the percent of correctly classified cases dropped to 63.09%; 2) Cohen’s U3 and Cliff delta values were substantially smaller than those observed in the raw dataset (75.51% vs. 96.26% and 0.36 vs. 0.78, respectively; Additional file 1: Table S3A, B); (3) although statistically significant F > M differences were observed in all decile values of the Pclass distribution, the size of these differences” ranged between 0.07 and 0.09 (p < 0.001 in all cases; Additional file 1: Table S3C). As a result, the distribution of all pairwise differences between females and males was quite symmetrical and centered close to the zero value (0.08), hence indicating that F > M differences were just slightly more frequent (68%) and expectable (64–72%) than M > F differences. Moreover, most of the observed pairwise differences were “small” in size (e.g., 80% of the observed differences had a size that was equal to or less than 20% of the maximum possible).
Taken together, these results indicate that, when the SENT_CORE network is taken as a whole, males have larger amounts of raw GMvol than females but also that, as already observed when the 18 brain areas composing this network were analyzed separately, these volumetric measures (and, therefore, their mutual differences) are largely driven by the existing M > F differences in TIV. In fact, when statistically controlling for TIV-variation, larger relative amounts of GMvol in females should be expected although the observed multivariate differences should be much smaller.
Validating and interpreting the multivariate sex differences and similarities estimated from classification probabilitiesTo validate and gain additional insight on the multivariate sex differences in the SENT_CORE network estimated from Pclass scores, additional analyses were conducted. Firstly, multivariate sex differences and similarities were re-assessed using a very different statistical approach sustained on a projection pursuit method that unambiguously assesses the direction of these differences and allow estimating their size with the same indexes used for Pclass scores (see details in Sect. 2.3.2 and [60]). The results of this re-assessment are summarized in Fig. 5 and, as it can be readily observed, they confirmed the correctness of the direction imposed to those obtained from Pclass scores and provided very similar estimates in terms of size (see Table 3). Moreover, individual scores based on projected distances calculated from raw, but not from PCP-adjusted, GMvol showed a similar dependency on TIV values than Pclass scores (r = 0.87, p < 0.01 and r < 0.01, p > 0.970, respectively; Fig. 5C, D). Additionally, in both the raw and the PCP datasets, individual projected distances were significantly correlated with individual Pclass scores (r = 0.85, p < 0.01 and r = 0.84, p < 0.01, respectively; Fig. 5E, F). Taken together, these results suggest that, despite their different mathematical foundations, Pclass scores and projected distances capture the same multivariate reality and provide nearly identical estimates of the multivariate sex differences and similarities in the SENT_CORE network.
Fig. 5
Multivariate sex differences and similarities estimated from projected distances in the raw and PCP datasets. A and E Scaled density function for the males (blue) and females’ (red) distributions of the projected distances’ scores in the raw and PCP datasets. Within each panel, the percent of overlap (O) as well as the probabilities of superiority for males and females (PS) as well as the p-value associated and an R2 effect size index derived from the comparison of these PS values using Cliff’s delta are provided. C and D Scatterplots of the bivariate relationships (quantified by a robust analog of the correlation coefficient Pearson’s r) between the projected distances and TIV scores in the raw and PCP datasets. E and F Scatterplots of the bivariate relationships (quantified by a robust analog of the correlation coefficient Pearson’s r) between the projected distances and Pclass scores in the raw and PCP datasets (M = males, F = females)
Table 3 Comparison of the multivariate sex differences estimated from Pclass scores and projected distancesSecondly, to obtain further insight on the structure of the multivariate sex differences estimated from Pclass scores, the nomograms of the LR models fitted in the raw and PCP datasets were built up (Fig. 6A, B). These nomograms illustrate the relative contribution of each brain area to the final model (length and maximum of points assigned to each scale), but also how the scores of males and females (as represented by their medians) in each of these weighted dimensions were additively integrated into overall scores that non-linearly project into the Pclass continuum. Of note, the relative importance of these 18 brain areas for the final LR models (quantified in terms of the regression coefficient values) exhibited a similar ordering than that of their univariate sex differences (assessed in terms of medians’ difference, Cliff’s delta, or Cohen’s U3), hence resulting in direct and statistically significant correlations between both sets of observations (rho = 0.7, 0.67, 0.68 and rho = 0.84, 0.86, 0.82 in the raw and in the PCP dataset, respectively; see Fig. 6C and Additional file 1: Fig. S1).
Fig. 6.
Structure of the LR models fitted in the raw and PCP datasets. A and B Nomograms illustrating the relative contribution of each component to the SENT_CORE network to the Pclass scores yielded by the LR models fitted in the raw (reference sex category: males) and in the PCP (reference sex category: females) datasets. The values of three discrimination indexes (R2, C index, and Somers’ D) of each of these two models are reported within the plots. Although nomograms are ordinarily used to predict individual classification probabilities, in this case, the males (blue) and females (red) medians are used to represent how the scores of these groups in each feature were scored (i.e., points; orange numbers), additively integrated in composites (“total points”), and non-linearly project to the Pclass continuum on which the multivariate sex differences and similarities displayed in Fig. 4 were estimated. Note that to enhance readability: (1) brain features are decreasingly sorted according to their contribution to the model; (2) instead of including a points’ axis, the points achievable (orange numbers) in each scale are represented back-to-back to the features’ values (black numbers); (3) the marks of some scales have been suppressed; and, (4) to highlight them, the scales of those features achieving statistical significance are depicted with thicker lines. C Ordinal relationship (quantified through the Spearman’s rho correlation index) between the regression coefficient values and the size of the univariate differences (medians’ difference) in the raw (left) and PCP (right) datasets. Note that the sign of this association is largely arbitrary as it arises from the different sex category used as reference in the raw and PCP models. D Ordinal relationship (quantified through the Spearman’s rho correlation index) between the coefficient values of the LR models fitted in the raw and PCP datasets. To ease the visualization of the relationships depicted in panels C and D, trend lines obtained through gam-smoothing (and their 95% interval; yellow shade) have been added
Figure 6 also allows noticing that, although the multivariate sex differences observed in the raw dataset are much larger than those observed in the PCP dataset, the nomograms obtained in these two datasets were remarkably similar (although the direction of their axes are reversed due to the use of different sex categories as reference in the LR models). Indeed, the values of the regression coefficients of these two LR models exhibited a very similar ordering (\(\left|rho\right|\)= 0.93, p < 0.001; panel D). This suggest that statistically controlling TIV-variation affects the size of the multivariate sex differences in GMVOL at the SENT_CORE network, but it does not artefactually alter their structure. This conclusion was confirmed after rebuilding the same models but adding TIV as an additional predictor. Thus, as shown in panels A and B of Fig. 7, the nomograms obtained were virtually identical and their regression coefficients showed an almost perfect correlation between them (\(\left|rho\right|\)>0.99, p < 0.001). Furthermore, the ordering of the regression coefficients corresponding to the components of the SENT_CORE network in these two last LR models was also very similar to that observed in the other two previously fitted LR models (\(\left|rho\right|\)> 0.92 in all cases; Fig. 7C).
Fig. 7.
Structure of the LR models after including TIV as an additional predictor. A, B Nomograms illustrating the relative contribution of TIV and each of the features included in the raw and PCP datasets to the Pclass scores. The values of three discrimination indexes (R2, C index, and Somers’ D) of each of these two models are reported within the plots. C Ordinal relationships (quantified through the absolute value Spearman’s rho correlation index) between the coefficient values of the four LR models fitted in this study and depicted in A and B of Figs. 6 and 7). Note that these associations were calculated excluding the coefficient value associated to TIV (which is only included in two of these four LR models) and that, because the sign of these associations is arbitrary (i.e., it arises from the different sex category used as reference in the distinct LR models), absolute rho values are reported. D Values of the regression coefficients in each of the four LR models fitted in the present study. Highlighted in green are those coefficients reaching statistical significance (p < 0.05) in each model (see details in Additional file 1: Table S3D). E UpSet plot illustrating the intersections between the predictors reaching statistical significance in the fitted LR models. In this plot: (1) the color of the line-joined circles denotes whether the features listed in each column reached statistical significance (green) or not (white) in a particular model, thus identifying which models are part of each intersection; (2) the height of the bars of bars on the top illustrates the number of features included in each intersection (the cardinality of each intersection); (3) the color of the bars denotes the number of models that included the listed features as significant predictors. Thus, for example, the first intersection includes three brain features that reached statistical significance as predictors in all four models, the second one includes two brain features that reached statistical significance in the PCP, raw + TIV, and PCP + TIV models (but not in the raw model), and so on
Finally, given the structural similarities of these four LR models, we conducted an assessment across models aimed to identify which components of the SENT_CORE networks more consistently contributed to the multivariate effects observed in this network. From the nomograms of these models (and even better so from the heatmap panel D of Fig. 7), it can also be readily observed that three brain features achieved statistical significance as predictors in all LR models, whereas others solely achieved significance in some of them, and yet other seven features did not exhibit a significant predictive value in any model. Thus, after conducting an intersection analysis of the coefficients reaching statistical significance in these four LR models (Fig. 7E), it can be suggested that T2_3, STS1, STS2 but also F2_2, T1_4, and F3O1 were the areas of the SENT_CORE network that more consistently contribute to the multivariate separation between males and females when considering this network as a whole.
Comments (0)