


Remember me
According to the global cancer burden data released by the International Agency for Research on Cancer of the World Health Organization in 2020, colorectal cancer has become the third most common cancer and the second most deadly cancer worldwide, following only lung cancer and liver cancer, with an increasing incidence among young and middle-aged populations (Xi and Xu, 2021). Surgery is the primary approach for curative treatment of colorectal cancer, involving tumor resection, ligation of local blood vessels, and lymph node dissection. The inferior mesenteric artery (IMA) is a key site for lymph node metastasis and the target vessel for ligation (Yada et al., 1997). Preoperative knowing the arterial branching helps surgeons create surgical plans for the safe and effective ligation of arteries and lymph node clearing.
Over the years, convolutional neural networks (CNNs) have greatly contributed to the field of computer vision, owing to their excellent feature extraction and expression capabilities. They have been widely used for tasks such as classification, segmentation, object detection, and registration. In 2015, the success of the Unet (Ronneberger et al., 2015) established the important position of CNNs in medical image analysis, and many variants based on Unet have been subsequently proposed, which have achieved impressive results in 2D medical image analysis. In 2017, 3D Unet (Çiçek et al., 2016) was introduced for the processing of 3D medical images, which further propelled the development of CNNs in 3D medical imaging tasks. Many automatic segmentation algorithms have been proposed based on these models, involving organs (Garcia-Uceda Juarez et al., 2019; Chen et al., 2020), tissues (Chen et al., 2017), tumors (Feng et al., 2020; Liu et al., 2015), and many other targets. Given the remarkable performance of CNNs in pixel (voxel) segmentation tasks, it has also been widely used for vessel segmentation (Zhao et al., 2022; Pan et al., 2022; Li et al., 2022). However, for some small vessels, the segmented results are often not accurate enough.
Many attempts have been made to expand the receptive field of convolutional networks to capture more global information. Wu et al. (2019) proposed a dilated convolution which can expand the receptive field, and achieved excellent performance in multiple segmentation tasks. Zhao et al. (2017) designed a multi-scale feature pyramid to aggregate more global information. Peng et al. (2017) applied a large kernel to capture global relationships. Although these methods have improved the modeling of contextual relationships to some extent, these models are still limited by the restricted receptive field of convolutional architectures.Compared with convolutional networks, the transformer relaxes the local inductive bias, enhances the interaction between non-local regions, and allows for effective learning of long-range information. Given the outstanding performance of the transformer, many methods have attempted to introduce it into the field of medical image processing. Dosovitskiy et al. (2020) proposed Vision Transformer (ViT), which was the first attempt to use the transformer for vision tasks. Liu et al. (2021) proposed a hierarchical architecture that uses movable windows to allow attention to be local and across-window connections to improve computational efficiency, making it highly compatible with various visual tasks. Some recent methods have attempted to combine CNN and transformer to improve model performance (Chen et al., 2021; Xie et al., 2021; Wang et al., 2021). However, these networks still rely heavily on convolutional layers, and the transformer is only embedded as a separate module to compensate for the lack of long-range relationships in the features extracted by the convolution. Specifically, they are often arranged after the convolutional feature extraction module in each layer or part of the feature compact layer. When the feature is feeded into the transformer, it is usually a limited feature that has undergone convolutional operations. We believe that it is usually limited to compensate for global dependencies based on this foundation, and the performance potential of the transformer is not fully exploited.
Due to the lack of inductive bias of transformers for images, transformer-based models require training on large-scale datasets or extensive pre-training to perform effectively (Dosovitskiy et al., 2020). This poses a problem when using Transformers for small scale dataset, which is a common problem in medical imaging. To address this, we propose a Triple-Axial Gated Transformer (TAGT) that runs the transformer from three directions: height, width, and depth, greatly enhancing the sensitivity of positional information, making the model more versatile and not restricted by massive amounts of data.
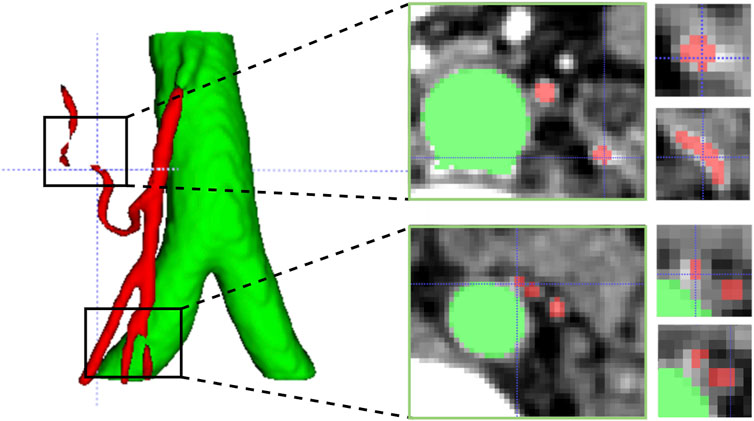
In addition, vascular images often exhibit sparse, elongated tubular structures. Due to uneven noise, low contrast, and the complex topology of blood vessels, existing methods for vessel segmentation typically suffer from the following problems: over-segmentation or mis-segmentation, poor vascular continuity, and poor capturing of microvessels. Therefore, 3D elongated tubular vessel segmentation remains a topic worthy of joint research. We attribute the above problems to the insensitivity to vessel edge structures. In Figure 1, we show an example of the IMA vessel prediction results, and even an error of a few pixels can have a huge impact on the continuity of vessels. Inspired by self-attention, we designed a vessel edge-sensitive module that enhances the capturing ability of vessel edges by increasing the weight of edge voxels in the vessel volume image.
FIGURE 1. Challenges in segmenting tubular vessels. The first column highlights two instances of vascular rupture identified in the 3D predictive model. The second column displays cross-sectional slices corresponding to the aforementioned ruptures. The third column presents magnified images of two adjacent microvessels extracted from the vicinity of the corresponding slices.
CNNs possess translational invariance but lack global feature comprehension. On the other hand, transformers excel at capturing global context, but their lack of translational invariance demands ample training data. Thus, their advantages complement each other. In existing architectural paradigms, some fusion architectures, predominantly relying on convolutional layers, tend to replace convolutions with transformers in a few compact layers. However, we posit that in limited convolutional features, leveraging transformers to capture global features may not fully exploit the advantages of transformers. In contrast to existing architectures, our approach involves constructing parallel branches for CNNs and transformers, aiming to maximize the utilization of their respective strengths.
In this paper, we explore a parallel encoding architecture that tightly integrates transformers with convolutional networks to address automatic segmentation of the inferior mesenteric artery in the abdomen. Our contributions can be summarized as follows:
1. We propose a parallel connection approach for integrating CNN and transformer, retaining the inductive bias of convolutions and the ability of transformers to model long-range dependencies. The architecture follows the classic encoder-decoder structure.
2. We extend the axial attention mechanism to the 3D domain, computing attention along the width, height, and depth directions. This efficient learning of positional information enhances the model’s ability to focus on fine details in small regions, addressing the issue of transformers struggling to learn image position encoding on small datasets and improving the model’s robustness for tasks with limited data.
3. We introduce a vessel edge feature capture (EFC) module which enhances the weight of vessel edge voxels to improve vessel boundary extraction and enhance vessel continuity, especially for capturing fine vessel boundaries.
4. We design a deep feature fusion block (FFB) to allocate weights between high-level features generated by the decoder and low-level features from skip connections. This selective feature fusion retains prominent features relevant to vessel structures.
1.1 Prior work and challengesWe built our Parallel Encoding Net (PE-Net) based on the latest successful foundations of convolutional neural networks and transformers. In this section, we briefly review the relevant methods and expand on two subfields: convolutional segmentation networks and semantic segmentation using transformers.
1.1.1 Semantic segmentation using ConvsNetCNNs have achieved tremendous success in various visual tasks such as segmentation, classification, registration, and object detection. Among them, the fully convolutional network (FCN) has become the mainstream network for semantic segmentation and has inspired many deeper and larger networks. In particular, the U-Net (Ronneberger et al., 2015) architecture, which uses a decoding-encoding structure with skip connections, has become the mainstream architecture for medical image segmentation. Many U-Net variants, such as U-Net++ (Zhou et al., 2018) and Res-UNet (Zhang et al., 2018), have further improved the performance of image segmentation. The W-UNET (Hong et al., 2019) improves segmentation performance by stacking multiple decoding-encoding modules, while the 3D Unet and V-Net (Milletari et al., 2016) further extend these high-quality features to the segmentation of 3D images. nnUnet (Isensee et al., 2021) is a significant breakthrough in the field of medical image segmentation using the U-Net architecture, which adapts training parameters to perform well in both 2D and 3D tasks and ranks first in the top ten tasks without changing the network structure.
Despite the success of these convolutional networks, the locality of the convolutional layers in CNNs limits their ability to learn distant spatial correlations. The convolution operation used in these models captures texture features by collecting local information from neighboring pixels. To aggregate feature filter responses at the global scale, many solutions have been proposed, which can be broadly classified into using dilated convolutions (Wu et al., 2019), increasing kernel size (Chen et al., 2017), adopting feature pyramid pooling (Chen et al., 2017; Zhao et al., 2017), and non-local operations (Wang et al., 2018). Although these methods have been shown to improve performance, such improvements are limited and cannot completely solve this problem.
1.1.2 Semantic segmentation using transformerIn recent years, a large number of excellent transformer-based methods have emerged in the field of image processing. Transformer-based visual models can be further divided into two types: one is the method constructed mainly with convolutional layers, and the other is the method using transformer as the main architecture. TransUnet (Chen et al., 2021) is proposed as the first attempt to introduce the transformer into the field of medical image segmentation. The core idea is to embed transformer blocks between the CNN encoder and decoder to capture long-range dependencies. The idea of embedding several layers of transformers in a convolutional network has attracted a lot of followers. TransBTS (20) extends the transformer to 3D medical image processing tasks, modeling the remote dependencies in depth and spatial dimensions. Its structure is similar to TransUnet, placing transformers at the bottom of the U-shaped network. Wang et al. (2022) proposed a hybrid framework, using convolution as a shallow feature extractor in the first three layers and performing transformers in the last two layers. UTNET (Hatamizadeh et al., 2020) replaces a group of convolutions in the encoding and decoding layers of the U-shaped network with transformer blocks. Cotr (Xie et al., 2021) proposes a mixed architecture to efficiently bridge CNN and transformer and introduces a deformable attention mechanism to reduce the computational complexity for incorporating more transformer layers. However, these methods typically treat the transformer as a module embedded or replaced within a few layers of convolutional networks, without fully overcoming the inherent limitations of feature extraction with convolutions. This has prompted researchers to explore solutions based on the transformer architecture.
Some researchers lead the way in using transformer as a feature extractor. Zheng et al. (2021) deploy a pure transformer network to encode images as a series of patches, without using any convolutions or downsampling operations, and utilize each layer of the transformer for context modeling. Swin Transformer (Liu et al., 2021) is proposed to apply the inductive bias of CNN to the transformer architecture, allowing window movement and computing local attention in each small block window for global interaction. Zhou et al. (2021) integrated the advantages of the nnUnet architecture and employed Swin Transformer in both the encoder and decoder, achieving impressive performance. Nonetheless, as the transformer architecture relies on attention mechanisms to capture holistic information, its inherent lack of translational invariance often demands an extensive volume of training data or pre-trained models. This predicament renders it arduous to cater to the demands of small training datasets. Tragakis et al. (2023) introduced a novel fully convolutional transformer that integrates the characteristics of convolution with the ability of transformers to capture long-range dependencies, eliminating the need for any pretrained models. Building upon the Swin Transformer, Liu et al. (2023) devised a convolutional multi-head self-attention block. This design incorporates convolutional projection and window shift mechanisms, simultaneously offering local context and inductive bias. The deep fusion of convolution and transformer, leveraging the strengths of each, serves as inspiration for the design of our model.
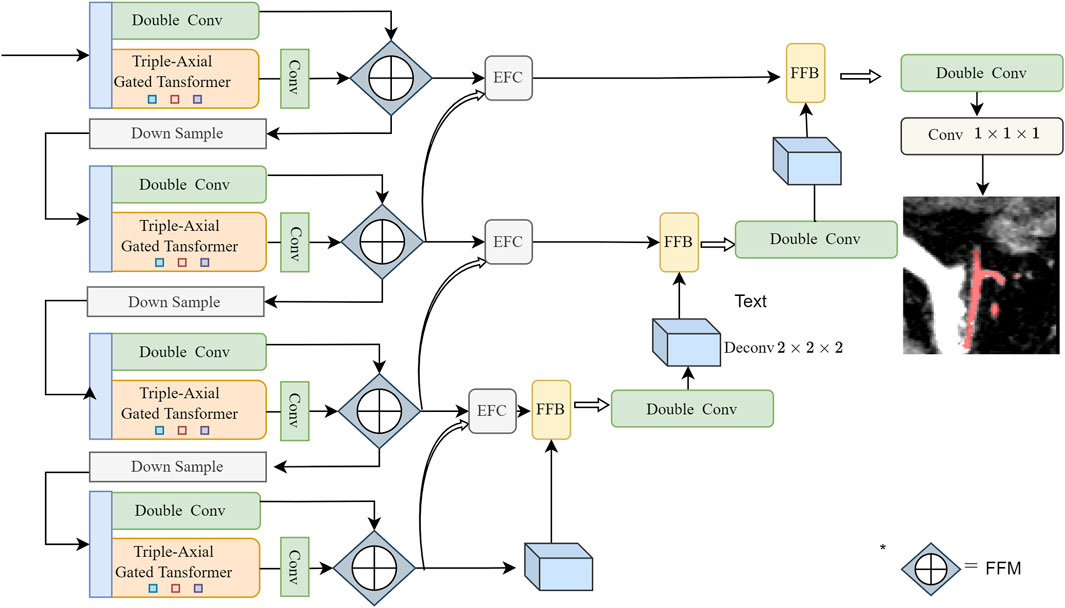
2 Methods2.1 Network architectureInspired by the great success of 3D Unet (Çiçek et al., 2016) and Swin Transformer (Liu et al., 2021), we propose a novel parallel network that combines transformer with CNN. The overall framework of our proposed network is illustrated in Figure 2. Our network consists of a contracting path (encoder), an expanding path (decoder), and skip connections.
FIGURE 2. Overview of the structure of the proposed PE-Net: Two encoding layers consisting of CNN and TAGT, a skip connection layer consisting of EFC and FFB, and one decoding layer. The parallelly encoded features are fused using the Channel Attention-based method, as introduced in our previous work (Zhang et al., 2023)—a block named Feature Fusion Module (FFM). Before the operation, the features generated by TAGT are broadcasted to align their channel dimensions with the convolutional features.
Encoder: During the encoding process, we design two parallel branches. One branch follows the classic double-convolution encoder, while the other branch employs a transformer encoder based on axial attention. The features extracted from these two branches are fused in the channel dimension using the Feature Fusion Module (FFM), as introduced in our previous work.
Decoder: The decoder is responsible for progressively upsampling the extracted features from the encoder to the input image resolution. It consists of four layers, each composed of double convolutions, and upsampling is achieved through transpose convolutions.
Skip connections: The skip connection path comprises EFC and FFB. These modules respectively guide feature extraction from vessel boundaries and vessel regions to obtain more detailed vessel structure information.
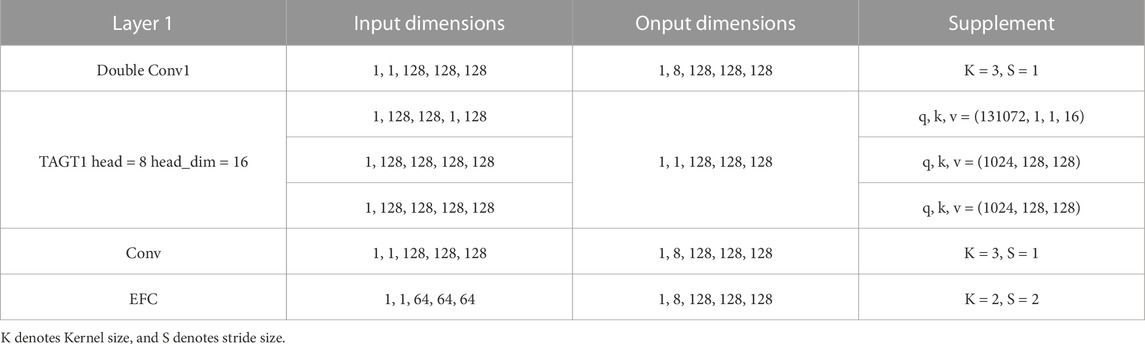
At the network’s final layer, a 1 × 1 × 1 convolution followed by the softmax function is applied to generate segmentation probability maps. As an example, Table 1 shows the variations of parameters for each module in the first layer of the network, while further details for each module are described in the following Section.
TABLE 1. Details of the PE-Net architecture.
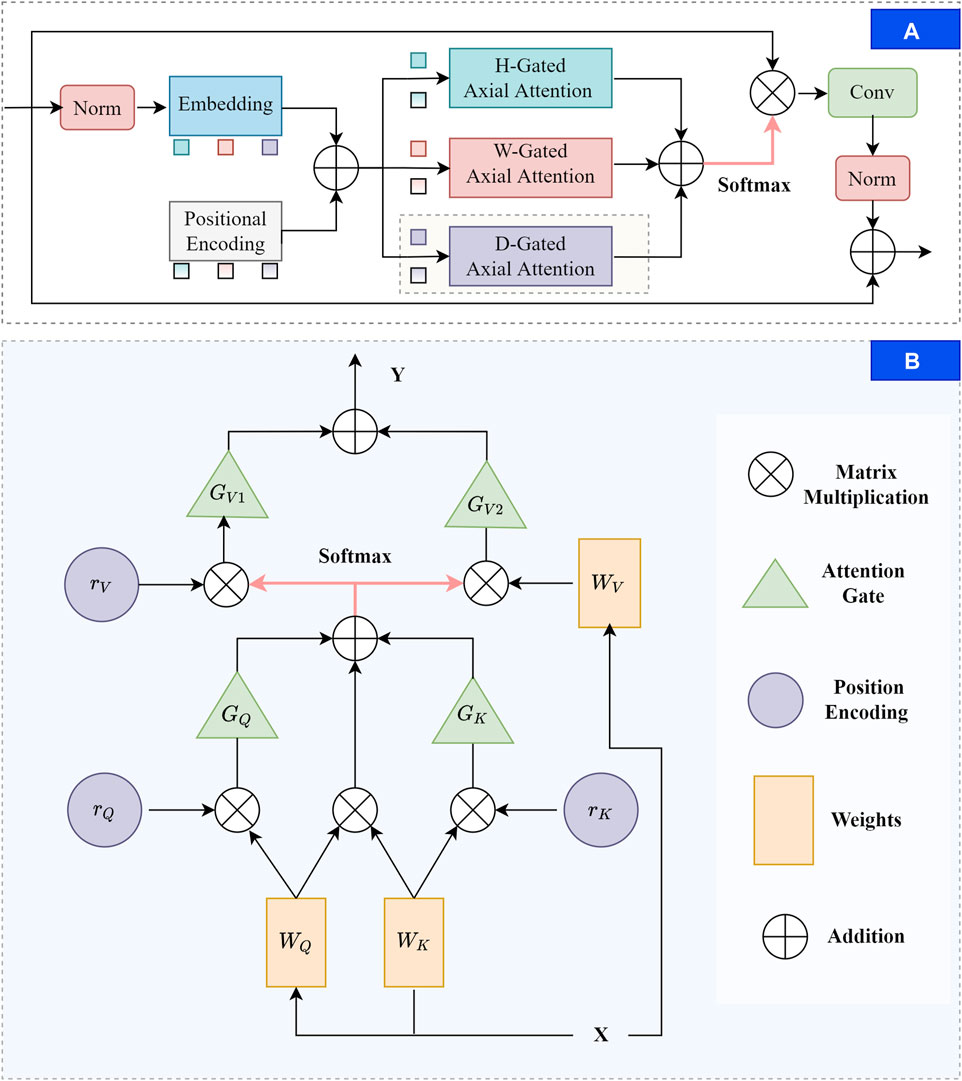
2.2 TAGTTAGT decomposes the transformer into three self-attention modules, breaking down the feature extraction process into three 1D operations along the depth, width, and height axes. It computes attention maps from these three operations and then combines them through summation and sigmoid to generate position weight maps. Building upon the conventional attention mechanism’s ability to consider query position deviations, Wang et al. (2020) advocates enhancing the model’s sensitivity to positional information by introducing relative positional bias terms for keys and values. Additionally, they attempt to perform attention calculations along the height and width axes, reducing parameter computation while ensuring the ability to capture long-range dependencies. Valanarasu et al. (2021) further introduces a gating mechanism for affinity calculations to further enhance the axial attention’s performance on small datasets. However, these efforts have been limited to 2D images. In this paper, we extend the axial attention to a 3D perspective by introducing computations along the depth direction. The overall structure of TAGT is illustrated in Figure 3. Below, we will provide a explanation of the derivation process of TAGT.
FIGURE 3. The diagram of the TAGT. (A) TAGT layer. Firstly, feature embedding and positional encoding are applied to the normalized features. Subsequently, corresponding features and position encoding are selectively chosen from the height, width, and depth axes for gated axial attention calculations. The results of the triple axial calculations are element-wise added, and the fused features undergo matrix multiplication with the original image to form the output. Convolution and normalization are applied, and a skip connection is added to stabilize training. (B) Three-dimensional gated axial attention layer, providing a detailed computational process for the shaded portion in (A).
For a given input feature X∈RC×D×W×H with channel C, depth D, height H, and width W. We first conducted data normalization to reduce the memory consumption of the model, accelerate model convergence, and improve training speed. Secondly, we used embedding layers to map features into vectors, including query vector q, key vector k, value vectorv. We use matrices for batch computation, the definitions of the three matrices are described in Eqs 1–3:
where v(X),q(X),k(X)∈RZ×N and N = D × W × H, Z is the embedding demention, Wv, Wq, Wk are learnable parameters. In the conventional process of three-dimensional attention calculation, the output y of the self-attention layer can be described as yi,j,t=∑d=1D∑h=1H∑w=1Wσqi,j,tTkd,h,wvd,h,w. Here, qi,j,t, ki,j,t, vi,j,t denote query, key and value at any location, i ∈ , j ∈ , t ∈ .
In TAGT, we transform the mapped vectors into four-dimensional features RZ×D×W×H. Afterward, the transformed 4-dimensional features were added with corresponding positional encodings to form the ultimate input vector. This input vector underwent attention computations across the width, height, and depth dimensions. The attention update of a transformer with a triple-axis feature extraction module on the depth axis is shown in Eq. 4:
yi,j,t=∑d=1Dσqi,j,tTkd,j,t+qi,j,tTrd,j,tq+kd,j,tTrd,j,tk×vd,j,t+rd,j,tν(4)where σ is function softmax qi,j, ki,j, vi,j, represents vector q, vector k, and vectorv at any position, rq,rk,rv∈RD×D are relative position coding which are learnable.
We achieve the final extractor by adding attention gates to every item in Eq. 4 except the first item, the update on the depth axis can be described in Eq. 5.
yi,j,t=∑d=1Dσqi,j,tTkd,j,t+Gqqi,j,tTrd,j,tq+Gkkd,j,tTrd,j,tk×Gv1vd,j,t+Gv2rd,j,tν(5)where the new added Gq, Gk, Gv1, Gv2 are all learnable parameters in network.
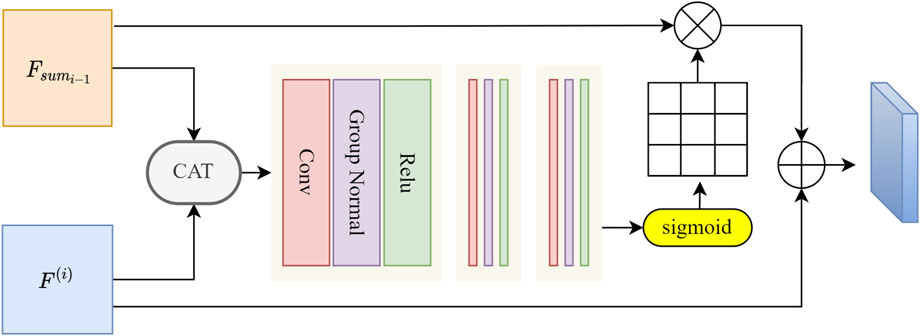
2.3 Vessel edge feature catcherContinuous downsampling often leads to the loss of some details in the model, leading to the prediction of vascular edges often not being accurate enough. Xia et al. (2022) regards the intersection of the foreground and background of different layers as the target edge feature, and the edge weights of foreground vessels in layer (i − 1)th can be obtained by subtracting the background probability map of layer ith from layer (i − 1)th. Hatamizadeh et al. (2020) employed a 1 × 1 × 1 convolution to design the edge gate module and verified its effectiveness in 3D medical image segmentation tasks. Inspired by the aforementioned two approaches, we designed our EFC which utilizes both the current layer itself and neighboring layers to ensure robust edge feature extraction. The detailed architecture of EFC is illustrated in Figure 4.
FIGURE 4. The architecture of EFC. The adjusted features in the encoding layer are denoted as Fi−1 and Fi, utilizing a double-layer path to ensure the extraction of edge features, distinguished by red and blue lines.
EFC discovers edge features through convolution and enhances them by increasing the voxel weights of the edge parts. Path 1 (red) first operates on features Fi generated in each encoding layer, Fi∈RC×D×H×W,i∈2,3,4. We first increased the resolution of Fi to match that of Fi−1. Then, we combined the features into a single channel using a 1 × 1 × 1 convolutional operation, passing them into ReLU to gain attention map σ1. Let σ be the function softmax, then processes can be represented using Eq. 6:
The weights captured in path1 can be described by Eq. 7:
Ai−1=1−σ1Fi=1−11+e−Fi(7)The corresponding edge feature can be captured by matrix multiplication, that is Eq. 8:
In the i − 1st layer, the final combined feature with the inclusion of edge features can be described using Eq. 9:
Fsumi−11=Fi−1+Ei−1(9)In Path 2 (blue), the same operations as in Path 1 are performed on Fi−1, except for the upsampling step, resulting in σ2 = σ(Re(C1(Fi−1))). The final output containing edge features can be represented by Eq. 10:
Fsumi−12=Fi−1*σ2+Fi−1(10)The final blood vessel edge features generated by the dual pathways can be represented by Eq. 11:
Fsumi−1=Fsumi−11+Fsumi−12(11)2.4 Deep feature fusion blockAlthough EFC enhances blood vessel edge information, it also enhances some similar interfering vessels. To address this, we introduce FFB, which filters and retains prominent blood vessel features of IMA. We utilize attention mechanisms to generate refined attention features. Unlike the attention gate, the essence of FFB is a feature fusion module. Building upon the classic CAT operation in U-shaped networks, FFB introduces additional convolutions for feature selection. Therefore, we initially concatenate features along the channel dimension, followed by feature extraction and filtering. Specifically, as shown in Figure 5, we connect the final features Fsumi−1 generated from the skip paths in each layer with the upsampled features F(i), F(i−1)=Fsumi−1⊗Upsample(F(i)).
FIGURE 5. The illustration of the designed FFB. The two sets of features are initially summed along the channel dimension. Subsequently, three convolutional blocks are employed for feature selection, each convolutional block consists of a convolutional layer, a group normalization layer, and a ReLU layer. The corresponding convolutional layer sizes in the three blocks are 3 × 3 × 3, 3 × 3 × 3, and 1 × 1 × 1. Attention weights are computed and allocated using the sigmoid function.
Subsequently, F(i−1) will be fed into three convolutional blocks, which selectively extractuseful vascular structure information from the fused features. This process can be expressed by Eq. 12:
Wx−1=gconvFi−1;θ(12)where gconv represents a set of three convolution operation functions. The variable Fi−1 refers to the integrated feature resulting from the combination of high-level and low-level features. Finally, the parameter θ is associated with the learning process involved in convolution.
In the end, we normalized Wx−1 using the Sigmoid function and generated corresponding attention weights Ax−1. This enables our network to learn to select more discriminative features, thereby achieving more accurate and reliable vascular region segmentation. Such improvements enhance the academic level of our algorithm.
3 Material, experiments and results3.1 DatasetIMA dataset is a self-made dataset that contains 60 anonymous patient upper abdominal vascular images from the Affiliated 2 Hospital of Nantong University in Nantong City, Jiangsu Province, China. The average size of the images was 512 × 512 × 90, with a classic voxel spacing of 1 × 1 × 1, each 3D IMA sample was cropped to 128 × 128 × 128. Three annotators and a professional expert were invited to annotate the vessels in the abdominal vascular images, including the background (label 0), IMA (label 1). The CT scans used in the experiment were obtained from a Siemens dual-source CT scanner (Somatom Force, Siemens Healthcare, Forchheim, Germany). The specific CT acquisition parameters were consistent with our previous work (Zhang et al., 2023).
ASOCA dataset consists of 60 coronary artery images, including 20 samples from patients with coronary heart disease and 20 normal samples, all of which are labeled. The remaining 20 unlabeled samples are used as the test set. These data were obtained from the Grand Challenge (https://asoca.grand-challenge.org/access/). The average scanning resolution is 200 × 512 × 512, but we resampled the dataset to a lower resolution, resulting in an average resolution of 200 × 256 × 256. The labeled dataset was split into training, testing, and validation sets in a ratio of 6:2:2.
3.2 Experimental settingThe platform used in this experiment comes from a deep learning computing platform with two NVIDIA RTX-3090 24 GB graphics cards. The operating system and version were Ubuntu 20.04, while the machine learning environment was configured with Torch 1.7.0 and CUDA 11.1. The program compilation environment was Python 3.6.12. During the training process, a 3-fold cross-validation was employed to partition the dataset. The Adam optimizer (Reddi et al., 2019) was used for network optimization, with an initial learning rate of 0.001 and a weight decay of 10–8. The learning rate was adjusted using CosineAnnealingWarmRestarts with eta_min set to 0.0001, and the total number of epochs was set to 600. The loss function used in this paper is presented in Eq. 13:
LPE−Net=0.6⋅LCE+0.4⋅LWCE+LDICE(13)3.3 Evaluation metricsTo comprehensively assess the segmentation performance of blood vessels and their edges, we utilized voxel-based metrics, including sensitivity (SEN), Dice Similarity Coefficient (DSC), Average Hausdorff Distance (AHD). SEN quantifies the proportion of true positive samples among all predicted results in the sample. A higher SEN corresponds to a higher proportion of true positive pixels, yet it neglects the ability to identify negative instances, rendering it unsuitable as a primary indicator for scoring segmentation performance. DSC utilizes the intersection of the predicted set and the ground truth to comprehensively evaluate sparse vessel segmentation in a large background context. A larger DSC indicates superior segmentation performance. AHD, calculated by measuring the closeness of corresponding points between the predicted and ground truth sets, offers a better assessment of edge accuracy in vessel segmentation. A smaller AHD reflects a smaller distance between the two sets, thus indicating better segmentation performance. DSC is sensitive to the internal filling of masks, while AHD is sensitive to the segmented boundaries. Considering vascular connectivity, we tend to favor models with smaller AHD. In cases where the difference in AHD is not substantial, higher DSC and SEN values also fall within the scope of consideration for the optimal model. The definition of evaluation metrics are illustrated in Eqs 14–16:
DSC=2|L∩P|L∪P=2TP2TP+FN+FP(15)AHD=121Pmaxp∈P,l∈Lmindp,l+1Lmaxl∈L,p∈Pmindp,l(16)where sets P and L represent the predicted set and the label set, respectively, and their corresponding elements are denoted as p and l. TP, FN and FP represent the true positives, false negatives and false positives, respectively.
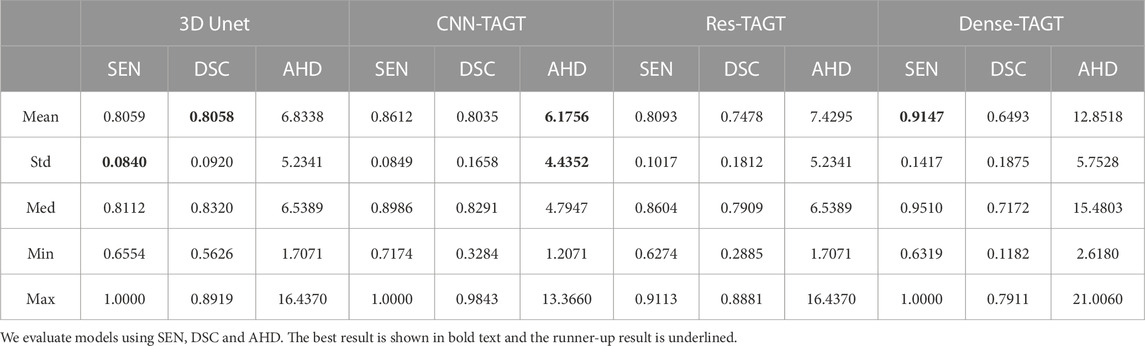
3.4 Experiment and results3.4.1 BackboneOur network entails two parallel encoders. To validate the efficacy of the parallel architecture, we first compare the experimental data between 3D U-Net and the parallel structured 3D Unet+TAGT (CNN-TAGT). Subsequently, in order to determine the optimal convolutional structure within the convolutional branch, we individually assess the impact of substituting the convolutional branch with 3D ResUNet (Res-TAGT) and 3D DenseNet (Dense-TAGT) on segmentation outcomes. The quantified results of these experiments on the IMA dataset are presented in Table 2.
TABLE 2. Quantitative results of the backbone by 3 fold cross-validation for the IMA dataset (20 for trainning).
We first conducted an analysis based on the average values, and further examined the data stability for results with insignificant differences in these averages. From Table 2, it is observed that the top two performers are predominantly the 3D Unet model and the CNN-TAGT model. In terms of AHD, CNN-TAGT achieved the best overall performance, outperforming 3D U-Net by a margin of 7.78%. Although Dense-TAGT exhibited superior sensitivity scores, its AHD was nearly double that of CNN-TAGT’s. This implies that Dense-TAGT possesses strong predictive capabilities for positive samples but also includes a substantial number of false positive results in its segmentation. While maintaining AHD performance, CNN-TAGT outperformed 3D Unet by 5.53% in SEN, with a value of 0.8059. Furthermore, the gap between the maximum and minimum values of SEN is relatively narrow, and the standard deviations are quite close, consistently staying within 0.9. This indicates that the advantage of CNN-TAGT over 3D U-Net is relatively stable. Due to the convolutional bias, the convolution-based 3D Unet model was unable to effectively capture global information and lacked efficient learning of positional information, leading to inevitable instances of mis-segmentation and reduced segmentation performance.
Regarding the DSC scores, the difference between the two models remained insignificant at 0.23%. Although the Res-TAGT model employed residual structures, its overall performance across various metrics was relatively mediocre. This could be attributed to the relatively shallow network architecture, which might not fully exploit the advantages of residual structures. In conclusion, CNN-TAGT exhibited superior and more stable experimental results compared to the other three networks. Through backbone comparative experiments, we determined that a simple double convolution structure is the best match with the transformer.
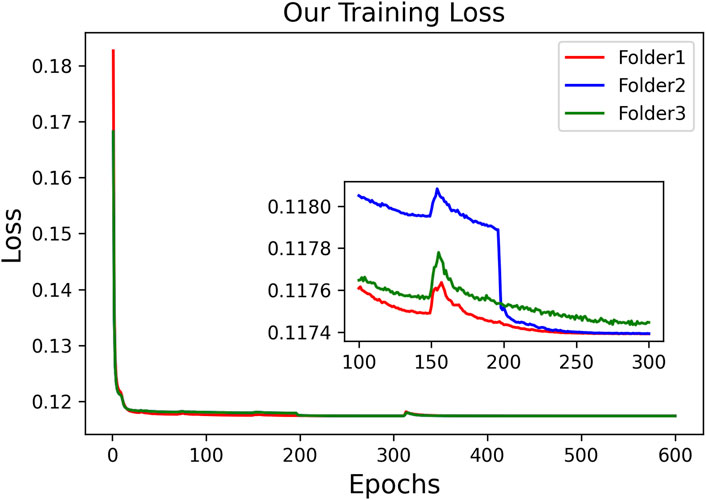
Considering the poor performance of Res-TAGT and Dense-TAGT, we do not present their visualization results. The visualization results of 3D Unet and CNN-TAGT will be shown together in the subsequent ablation experiments. To further validate the stability of our model, we plotted the training curves of CNN-TAGT during the 3-fold cross-validation, as shown in Figure 6. We zoomed in on the curves between 100 and 300 epochs, and it can be observed that all three training runs achieved convergence around 250 epochs.
FIGURE 6. The training loss of CNN-TAGT during the 3-fold cross-validation.
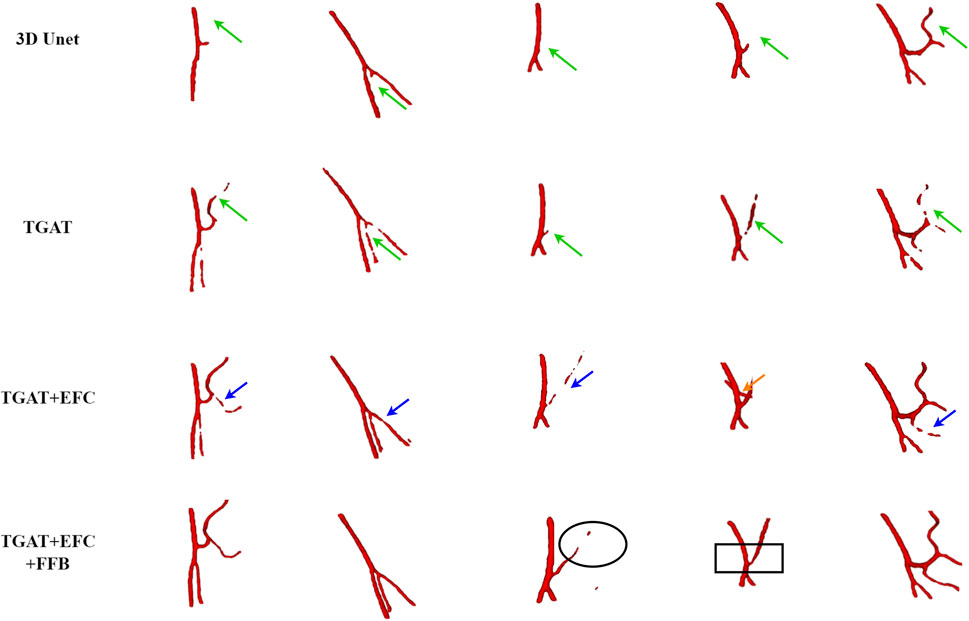
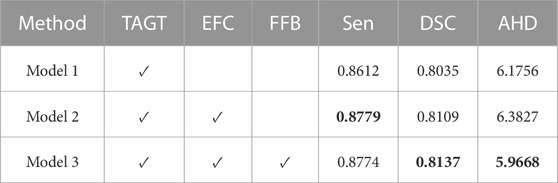
3.4.2 Ablation studiesThe PE-Net proposed in this study incorporates TAGT, EFC, and FFB modules. To confirm the effectiveness of these components, we conducted ablation experiments on each module. EFC and FFB were utilized to optimize the segmentation of small blood vessels, particularly enhancing the discriminative ability at vessel boundaries. Qualitative and quantitative results are presented in Figure 7 and Table 3, respectively. It is worth mentioning that the TAGT model represents the CNN-TAGT model that performed the best in the aforementioned backbone experiments.
FIGURE 7. The visual results of the ablation experiments on the IMA dataset.
TABLE 3. Quantitative results of PE-Net components on the IMA dataset, with the best results highlighted in bold.
As a supplement to the visualization results in the backbone experiments, we added a comparison with 3D Unet in the qualitative results. Observing the first column in Figure 7, we found that due to the inability to capture global information, 3D Unet had more vascular leakage problems. After introducing TAGT, the model detected more vascular details, as shown by the green arrows in the second column. However, due to the lack of precise capture ability for small vessels, the segmented vessels by TAGT appeared in a fragmented and uneven state. This situation was greatly alleviated after introducing the EFC module. The performance of EFC often demonstrated three characteristics: 1) Repairing the fractured vessels in TAGT by enhancing edge features, which can be observed through comparison with TAGT’s results; 2) Capturing more details of small blood vessels relative to TAGT, represented by the blue arrows; 3) Excessive learning of edge features resulted in the missegmentation of adjacent vessels, as shown in case 4 by the orange arrows. In the early models, these adjacent vessels were all classified as foreground vessels.
To address the above issues, we further introduced the FFB module, which accomplished feature selection through channel attention. FFB assigned significant weights to features related to target vascular structures, aiming to improve vascular segmentation and remove interference caused by EFC. The improved results are illustrated in the black boxes, where the vascular structures appeared brighter and smoother, indicating that the output features contained more representative information.
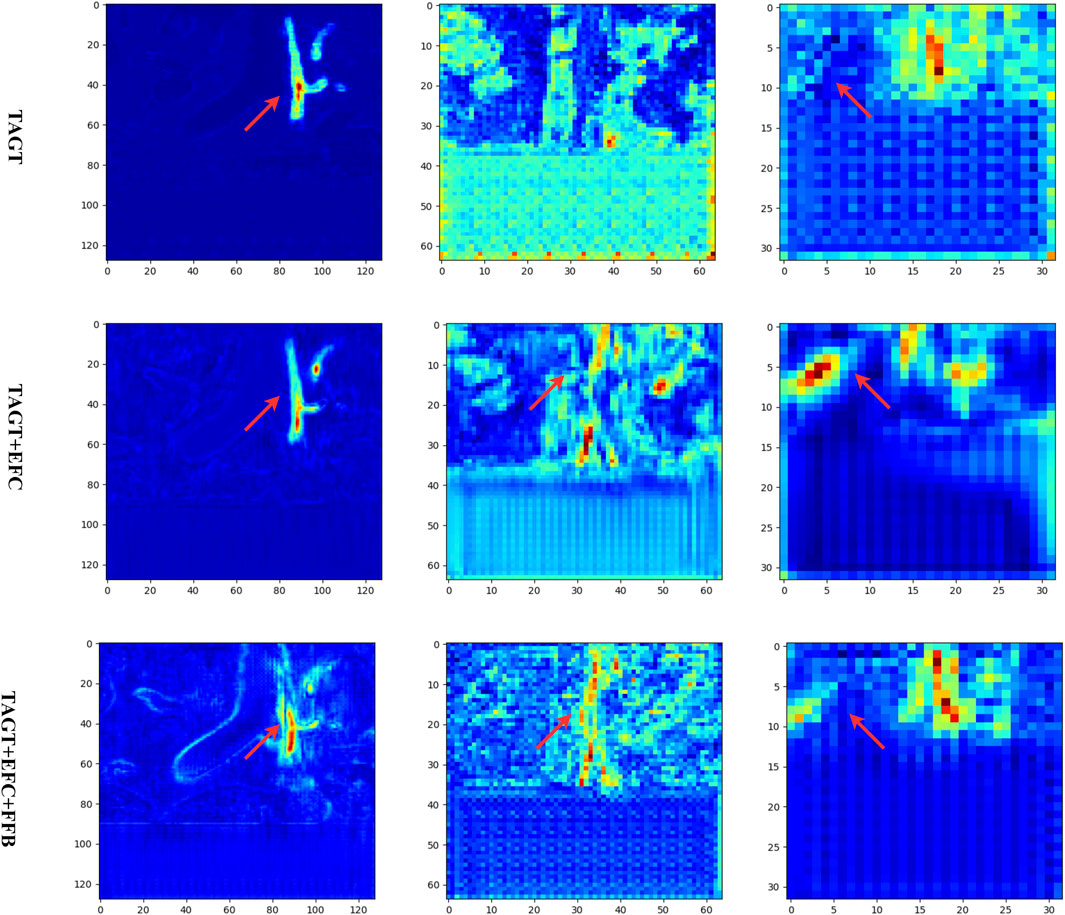
To further validate the effectiveness of each module, in Figure 8, we present the feature maps of various models in the contracting paths at resolutions of 128, 64, and 32. A random coronal slice from the volumetric data was selected, and the feature maps of all channels were averaged and projected. Comparing the first two rows, it was observed that the introduction of EFC resulted in wider blood vessels and more distinct features. The red regions spread both horizontally and vertically. Comparing the second and third rows, the red pixels became more compact, and the FFB module enhanced the connections between vessels while removing interfering vessels to some extent.
FIGURE 8. Feature maps of the ablation models. From left to right, the output feature maps of different models are shown at three encoding layers (with resolutions of 128, 64, and 32, respectively).
The quantitative results in Table 4 validated the above analyses. The comparison between model 1 and model 2 indicated that model2 with EFC achieved a 1.67% and 0.74% improvement in SEN and DSC scores, respectively, while AHD increased by 0.2, confirming the possibility of introducing neighboring vessel interference while capturing more true positive vessels. Comparing model 2 and model 3, the introduction of the FFB module resulted in a significant decrease in AHD, while maintaining almost unchanged SEN, and an increase of 0.28% in DSC score, suggesting that FFB employed a more reasonable fusion method for vascular features. FFB utilized channel attention to assign different weights to low-level and high-level features, selecting hidden features beneficial for vascular segmentation.
TABLE 4. Segmentation performance of different methods on IMA.
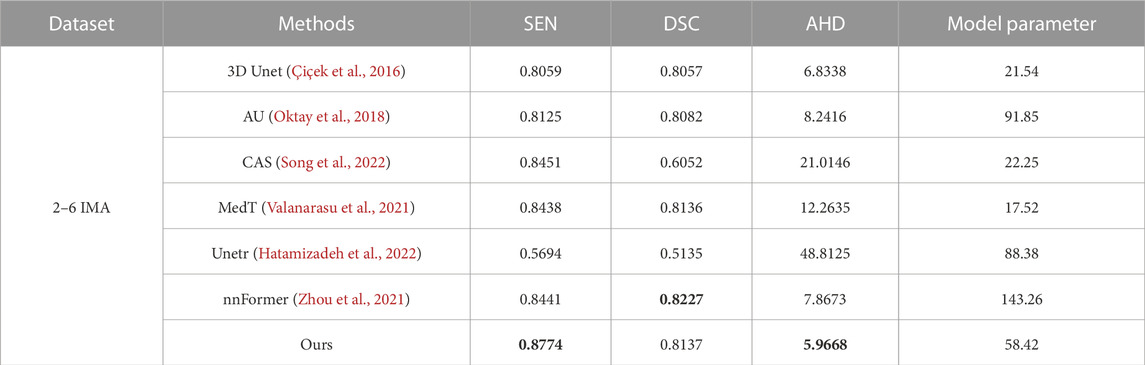
3.4.3 Comparison with state-of-the-art methodsIn this part, we conducted experiments to validate the effectiveness of our proposed method using a self-made dataset. We compared our method with five different approaches, including the convolutional network 3D Unet, Attention Unet (AU) (Oktay et al., 2018), CAS(40), transformer-based method Unetr, MedT and nnFormer. The evaluation was performed on complete volume images rather than using patches to obtain the evaluation results. The qualitative and quantitative results are presented in Table 4 and Figure 9, respectively.
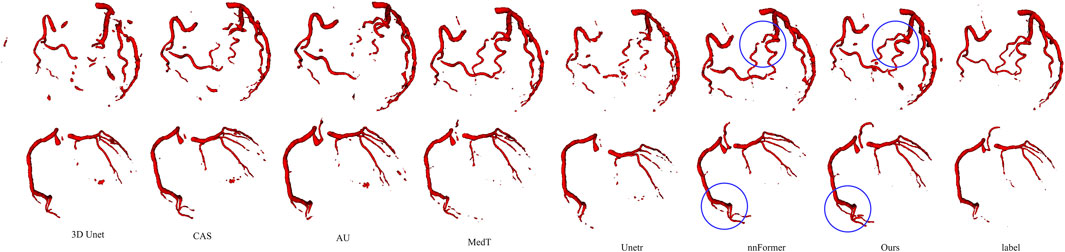
FIGURE 9. Visualization of segmentation results for different baseline models. From left to right, each column represents a case, and from top to bottom, they are CAS, AU, 3D Unet, MedT, Unetr, nnFormer, and our segmentation results, respectively.
Firstly, we compared our model with convolutional models as shown in the first, second, and fifth rows of Figure 9. CAS achieved significant success by utilizing vessel region filtering and efficient feature fusion based on Dense blocks. However, we noticed that its performance on the IMA dataset was not optimistic, as it could not efficiently capture vascular features, even falling behind 3D Unet. CAS could only perform basic segmentation on the main IMA vessels and struggled with smaller branch vessels. We attribute this limitation to its Dense blocks, which contain only three 3 × 3 × 3 convolutions to reduce computational complexity. Consequently, this simple connection fails to fully exploit the advantages of the Dense structure, leading to a lack of capability in capturing complex vascular features. 3D Unet can roughly segment blood vessels’ overall structures, we observed that it missed some vessels in case 1–3, due to the limited receptive field of convolutions, which hindered its ability to explore branch vessels. Built upon the U-Net architecture, the AU introduces attention gates to improve target localization, emphasizing salient foreground features. Although AU demonstrates performance similar to U-Net overall, it does not enhance the continuity of vessels or deep vascular features. Attention gates are more effective in segmenting large organs, like the liver, but their efficacy is constrained in scenarios involving slender and discontinuous vessels, as seen in blood segmentation.
Next, we compared our model with transformer-based models. Unetr (the third row) performed poorly, as expected, as transformers usually require more extensive training data. Additionally, we noted that the original code’s epoch was set to 20,000, while we used only 600 epochs. Transformers introduce a large number of parameters, leading to higher time costs. Meanwhile, we also validated the transformer’s ability to model long-range features. Although Unetr struggled with vascular continuity, it could capture more vascular branches and achieve a preliminary representation of vascular morphology compared to convolutional networks. Assisted by the axial transformer, MedT effectively captures the complete branching of vessels. However, it is evident that within more intricate vascular patterns, the smoothness of blood vessels and the intensity of terminal vessels in MedT are notably inferior. In general, there is a lack of refinement capability for boundaries. nnFormer inherited the advantages of the nnUnet architecture and achieved satisfactory segmentation results. However, due to its limited capability in capturing edge features, we observed varying degrees of vascular discontinuity in cases 3 and 4. In case 3, our segmentation results surpassed nnFormer, while in case 5, nnFormer captured more extensive branch vessels.
Table 4 displays the parameter quantities and quantitative results of each model. It can be observed that our model achieves the best results in terms of AHD while having only half the parameter count of nnFormer. Additionally, our model demonstrates slightly higher or comparable values for SEN and DSC.
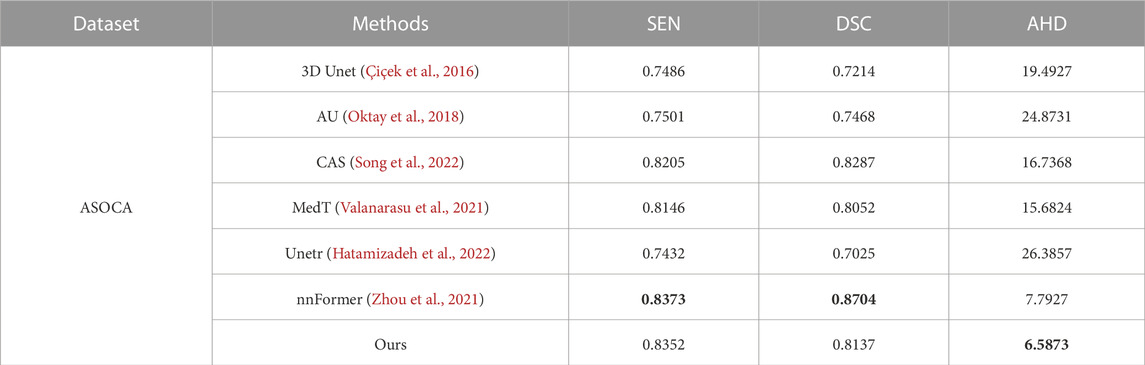
Furthermore, we validated the performance of our model on ASOCA. The quantitative experimental results are presented in Table 5, showing that, compared to nnFormer, SEN achieves a similar score. Although it has a slight disadvantage in terms of DSC, our method obtained the best AHD. Visual results are displayed in Figure 10. The figure illustrates that the convolution-based models 3D U-Net, AU and CAS exhibit varying degrees of under-segmentation in tiny vessels, displaying extensive vascular disconnections. The Unetr performs similarly to its performance on the IMA dataset, failing to segment well-formed branching vascular structures. MedT yields rough vascular edges with a deficiency in refining boundaries, particularly showing a lower continuity in small vessels. In contrast, our model and nnFormer both manage to capture the overall vascular structure and our model particularly excels in learning vascular edge features, resulting in improved segmentation of small vessels with abrupt changes in direction, as highlighted by the blue circles.
TABLE 5. Segmentation performance of different methods on ASOCA.
FIGURE 10. Visualization results of different methods on the ASOCA dataset.
The corresponding experimental results demonstrate that our model possesses more advantages in terms of vascular continuity and branch integrity.
4 Summary and conclusion4.1 Theoretical contributionsThe prior knowledge of the three-dimensional structure of blood vessels has provided significant convenience for disease prevention, diagnosis, and treatment. In recent years, researchers have made significant contributions to the field of three-dimensional medical image processing, with a plethora of segmentation algorithms available for three-dimensional tumors and organs. However, the task of three-dimensional blood vessel segmentation remains highly challenging. Due to the difficulty in capturing features of small vessels and determining vessel edges, issues such as vessel leakage, missegmentation, and numerous vessel discontinuities often arise. The segmentation of 3D slender tubular blood vessels remains a topic worth researching together.
In this paper, we propose a new segmentation approach for three-dimensional segmentation of the inferior mesenteric artery in the abdomen. We designed a parallel architecture combining transformers and convolutions. We extended the gated axial attention mechanism to three dimensions and efficiently learned position deviations using the gating mechanism to enhance the network’s ability to capture features of small vessels, alleviating the transformer’s difficulty in learning image position encoding on small datasets. We designed the EFC to enhance the weight of edge voxels of blood vessels, thus boosting the learning of edge features and improving the continuity of blood vessels. FFB is used for selective feature fusion, retaining features significantly related to vascular structures to further optimize the results after EFC. On one hand, FFB performs deep connections on blood vessel structures further captured by EFC, and on the other hand, it assigns low weights to interfere vessels introduced by EFC, effectively removing them. The experimental outcomes indicate that, in contrast to state-of-the-art models, PE-Net achieves the best experimental results by simultaneously ensuring relatively high values for DSC and SEN, along with a better AHD. This underscores its performance with enhanced vascular continuity. Although our model has achieved good performance in the segmentation of IMA, in some vascular segmentation tasks, we had to lower the resolution to fit within the limited GPU memory. Due to the small size of blood vessel branches at the vascular periphery, directly
Comments (0)