
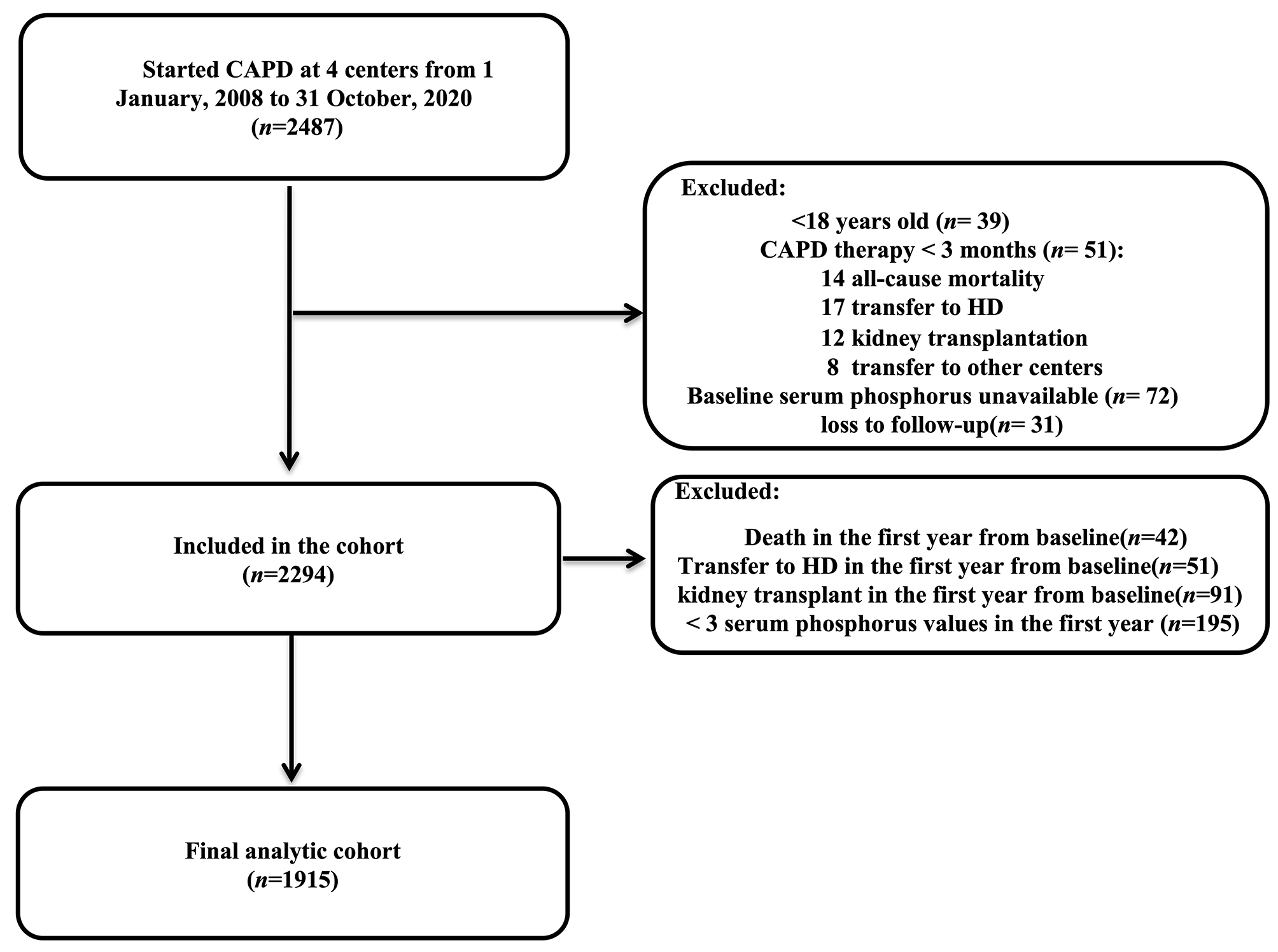
記住我





In the present analysis, the following steps were taken to estimate the potential relationship between treatment compliance and the lifetime cost of KF:
1) Two hypothetical cohorts ─ Good Compliance and Poor Compliance ─ were defined based on an assumed mean age-at-KF for a representative patient in each respective cohort. The age-at-KF assumptions were based on real-world evidence [13, 17] and clinical expert opinion.
2) For each cohort, the age-at-KF value was used to estimate a composite compliance score (CCS), which in turn was used to estimate an annual compliance score (ACS) – both estimations were based on the model derived by Nesterova et al. (2015) [13].
3) For each cohort, a mean age-at-death was estimated, based on real-world evidence [8] and clinical expert opinion.
4) (A) A survival to kidney failure (SKF) curve was developed to reflect the mean age-at-KF for each cohort. (B) Also, an overall survival (OS) curve was developed to reflect mean age-at-death for each cohort.
5) Using partitioned survival analysis, the years spent in a ‘post-KF’ state (the difference between mean age-at-death and mean age-at-KF), for each cohort, were calculated.
6) The lifetime cost of KF was estimated - by multiplying the number of years spent in post KF by the annual cost of KF.
7) The lifetime cost was adjusted to account for an annual discount rate – to produce discounted lifetime costs of KF for each cohort. This concept of ‘discounting’ is described in a section below.
8) The difference in discounted lifetime KF costs between both cohorts is calculated. Of note, results reflect mean (or per-patient) costs.
The steps outlined above are explained in more detail in the following sections.
Clinical inputs: estimating mean age-at-KF and mean age-at-death (steps 1–3)The present analysis utilises the study by Nesterova et al. (2015) investigating the relationship between treatment compliance and age-at-KF (in years) using 30 years of clinical follow-up data for 53 patients with NC followed from birth in the United States [13]. In their study, compliance was defined as a composite score taking into consideration both a patient’s duration of treatment prior to KF (in years) and their annual compliance score (ACS). A patient’s ACS was indexed on a patient’s mean leucocyte cystine level within that annum (henceforth: annual LCL) (Table 1) [13]. A patient’s CCS, therefore, is the sum of a patient’s ACSs over their duration of treatment prior to KF. Nesterova et al. (2015) estimated a linear model with the equation ? = 0.30? + 8.82; \(^\) = 0.61 (henceforth, Nesterova’s equation), where ? is a patient’s CCS, and ? is their age-at-KF [13].
Table 1 Compliance index based on patients cystine level, Nesterova et al. (2015)Clinical inputs: estimating mean age-at-KF and mean age-at-death (steps 1–3)Building on Nesterova et al. (2015) [13], the present analysis focuses on patients monitored from birth, starting oral cysteamine treatment at an early age (i.e., before 5 years of age). Of note, Nesterova et al. (2015) [13] do not make explicit the mean age of treatment initiation in their study sample; our assumption of an early age is based on clinical expert advice and the consistency of outcomes with similar studies (Brodin-Sartorius et al. (2012) [8], Emma et al. (2021) [17]) which consider an ‘early treatment’ sample. Importantly, clinical experts interviewed also suggested that such patients best represent the patient population in the UK.
Two hypothetical cohorts – ‘Good Compliance’ and ‘Poor Compliance’ – were defined, and Nesterova’s equation [13] was used to estimate treatment specific CCSs for patients by assuming a mean age-at-KF for each cohort and substituting them into the equation.
Estimating mean age-at-KFThe Poor Compliance cohort was intentionally defined to reflect the patients assessed by Nesterova et al. (2015) [13]. Patients in this study were reported as having a mean LCLFootnote 1 of 2.35 (± 0.26) nmols half-cystine/mg protein (henceforth: nmols). Given the definition of optimal cystine control in the literature (a leukocyte cystine level < 1 nmol) [23], and feedback from clinical experts, these patients were deemed to sufficiently reflect a ‘poor compliance’ cohort. Thus, the aim was to model a Poor Compliance cohort that reflected the real world in terms of compliance and, consequently, to use a mean age-at-KF result that was externally valid − indeed, identical to the result reported by Nesterova et al. (2015) [13]. Therefore, the mean CCS applied to the Poor Compliance cohort was calculated based on the reported mean age-at-KF in Nesterova et al. (2015) − a mean age-at-KF of 15.40 years, implying a mean CCS of 21.93 using their equation [13] (Table 2). This CCS also implies a mean ACS of 1.42 (as \(1.42\times 15.40=21.93\)). In the index (henceforth, Nesterova’s index) provided by Nesterova et al. (2015) (Table 1), an ACS of 1 corresponds to an annual LCL ≥ 2 and < 3; an ACS of 2 corresponds to an annual LCL ≥ 1 and < 2 [13]. Therefore, given the definition of optimal cystine control mentioned above, a mean ACS of 1.42 plausibly reflects a Poor Compliance cohort. Of note, while the mean ACS expresses the average ACS over all the years of a patient’s life until age-at-KF, to judge compliance levels it is more accurate to consider the ACS over the expected treatment period. Based on clinical expert guidance and published literature [17] we assumed that the average age of treatment initiation is ~ 2 years old. Applying this assumption to our previous calculation entails an ACS of 0 over these first 2 years. Thus, the mean ACS over the remaining 13.4 years (the assumed treatment period) is 1.64 (as \(1.64\times 13.40=21.93\)). This compliance level also plausibly reflects a Poor Compliance cohort. The representative patient in the Poor Compliance cohort was assumed to have this ACS, 1.62, and a treatment duration of 13.4. However, the choice of ACS and treatment duration ultimately do not affect the base case results of this analysis – it is the CCS (which can be obtained with various ACS and treatment duration combinations)Footnote 2 that can be employed to generate the same CCS. Similarly, for the purpose of drawing conclusions, regarding the relationship between compliance and the cost KF, the CCS is sufficient and is the parameter that was ultimately used as a standard for comparison.
Table 2 Cohort DefinitionsFor the Good Compliance cohort, a mean age-at-KF of 23 years was assumed. Clinical experts suggested that a good level of compliance (i.e., a mean ACS between 2 and 3) would likely result in an age-at-KF value within a range of 18–30 years − particularly given the assumption of early treatment initiation (i.e., < 5 years of age). This is corroborated by the literature. For example, considering the top 10% of CCSs (i.e., the most compliant patients) assessed in Nesterova et al. (2015), the mean age-at-KF observed was approximately 23 years [13]. Although Nesterova et al. (2015) do not make explicit the age at treatment initiation for these patients, it is likely these patients started treatment early; recent data from Emma et al. (2021) make clear that age at renal failure (defined as stage 5 chronic kidney disease) is significantly associated with age at treatment initiation [17, 24]. Furthermore, Emma et al. (2021) also shows a median age of approximately 18 years before renal failure for patients with a mean leucocyte cystine level between 1.2 and 1.8 nmols, irrespective of age at initiation or treatment duration [17]. Given the ‘age-at-KF’ range (18–30 years) proposed, the lower/upper bounds of the range were tested in scenario analyses. Using Nesterova’s equation [13] a mean age-at-KF of 23 years resulted in a CCS of 47.27, and a mean ACS of 2.06 (as \(2.06\times 23=47.27\)). As with the Poor Compliance cohort, assuming patients start treatment after 2 years, the mean ACS over the assumed treatment period (21 years) is 2.25 (as \(2.25\times 21=47.27\)). In both cases, the mean ACS plausibly reflects a Good Compliance cohort. The representative patient in the Good Compliance cohort was assumed to have this ACS, 2.25, and a treatment duration of 21 years. Furthermore, in some sensitivity analyses the age-at-KF was analysed as a function of these parameters (ACS and treatment duration) - using Nesterova’s equation [13]. As a result, we could test the sensitivity of results to changes in ACS or treatment duration – indeed we did test the results against alternate ACS assumptions, and indirectly tested the results against alternate treatment duration assumptions by testing alternate age-at-KF assumptions.
In summary, a mean age-at-KF of 23.00 years and 15.40 years was assumed for the Good Compliance and Poor Compliance cohort, respectively (Table 2). Substituting these values into the Nesterova’s Eq. (2015) [13], the resulting mean CCSs were 47.27 in Good Compliance and 21.93 in Poor Compliance (Table 2). The ACSs derived based on the CCSs corroborated the assumption that 23.00 years and 15.40 years were plausible estimates of age-at-KF for patients in Good Compliance and Poor Compliance respectively.
Estimating mean age-at-deathIt was also necessary to estimate the mean age-at-death for both cohorts – in order to estimate the difference between the mean age-at-death and mean age-at-KF (that is, time spent in a ‘post KF’ state). Ideally, mean age-at-death would have been assumed based on literature regarding the relationship between compliance and age-at-death – as was done for the assumptions of mean age-at-KF. However, an extensive literature search was conducted and found no direct evidence of a relationship between compliance and mean age-at-death. Instead, for both cohorts, mean age-at-death was based on clinical expert guidance regarding the use of mortality data provided in Brodin-Sartorius [8]. The methodology is discussed in more details below. The resulting mean age-at-death was 48.77 years in the Poor Compliance cohort, and 56.37 years in the Good Compliance cohort (Table 2).
Clinical inputs: Estimating time spent in the Post KF state and associated costs (steps 4–8)For each cohort, the aim was to use the mean age-at-KF and mean age-at-death values to estimate the time spent in a ‘post KF’ state. The number of years spent in this state would be multiplied by an annual cost of KF to estimate a lifetime KF cost (per-patient). Importantly, ‘discounting’ would be applied in this process to establish a discounted lifetime KF cost for each cohort. Discounting in health economic analysis is a standard technique that aims to reflect the idea that costs and/or health outcomes predicted to occur in the future are usually valued less than present costs and/or health outcomes [25]. It is important to account for discounting particularly when comparing interventions and/or cohorts for which associated costs and/or health outcomes occur at differential times ─ as is the case in the present analysis. Discounting is usually included by estimating the costs (and/or health benefits) incurred in each year (or other defined time interval), over a given time horizon, for a cohort of patients. A discounting factor is applied to each value in the series and aggregated to a give a ‘present value’ of the entire series. The discount factor increases over time, based on an underlying discount rate. National Institute of Health and Care Excellence (NICE) guidelines recommend that costs and health outcomes should be discounted at 3.5% per year [26]. So, for example, £100 incurred in Year 2 would have a present value of £96.62. For Year 11, the present values would be £70.89 [25]. Therefore, in the present analysis, for each cohort, the aim was to estimate the mean lifetime KF cost as the present value of the sum of a series of annual costs incurred in the post KF state ─ accounting for differences in the timings of costs.
Partitioned survival model (PSM): structureFig. 1
Three primary health states of partitioned survival model. KF: Kidney Failure
Therefore, for each cohort, a partitioned survival model was developed in Microsoft Excel® to model the discounted lifetime costs of KF associated with each cohort. The model included three mutually exclusive health states − ‘KF free’, ‘post-KF’, and death (Fig. 1). One-year cycle lengths, and a ‘lifetime’ time horizon (100 years) were assumed. For each cohort, state membership in any given year was determined by two independently modelled, non-mutually exclusive, survival curves – a survival to kidney-failure (SKF) curve, and overall survival (OS) curve. Patients were assumed to enter the model at birth and, in each year, the probability of reaching KF, or death respectively, for a patient was applied based on the probabilities for an individual of that age. These probabilities (and thus, survival curves) were cohort specific. That is, the SKF curve for each cohort reflected the corresponding, assumed, mean age-at-KF (henceforth, time-to-KF). Similarly, the OS curves reflected the mean age-at-death (henceforth, time-to-death) estimates. The modelled SKF curves were based upon on survival probabilities taken from real world data regarding the time-to-KF for patients with NC [8]. The survival probabilities do not account for other causes of KF (including co-existing diseases) or patients with a subsequent failure [8]. Thus, membership in the post-KF in this analysis was determined by initial KF caused by NC. However, in the present analysis the SKF curves were adjusted by background mortality risks (derived from the modelled OS curves), and the modelled OS curves reflected all-cause mortality for a NC population [8]. Thus, membership in the state of death could account for other causes. Furthermore, in this analysis, only selected direct costs associated with the ‘post-KF’ state were considered: specifically, the costs of providing dialysis and/or kidney transplants (and transplant maintenance) in secondary care. Hospital care related adverse event costs were not explicitly accounted for in this analysis but were partially implicitly incorporated. The discounted lifetime cost of KF accrued over the time spent in the post-KF state was calculated. PSMs are useful for accounting for the differences in underlying probability distributions and this helps to accurately account for discounted costs. In other words, it is inaccurate to simply count the series of discounted annual costs starting from the time at which the mean time-to-KF occurs and counting though the mean number of years spent in the post-KF state. Instead, the method employed through PSMs is to count a series of discounted costs starting from the start of the time horizon (at t = 0) through to the end of the time horizon, accounting for the probability of membership in the ‘KF free’ state, and the probability of membership in the post-KF state. This effectively produces a discounted lifetime cost that is the mean of all possible discounted lifetime costs in a cohort, rather than producing a discounted lifetime cost that is simply a function of the mean time-to-KF and mean time spent in the post-KF state. Costs were valued at 2019 prices based on the latest available National Schedule of National Health Service (NHS) Costs (2019/2020) [27]. Costs were discounted at 3.5%/year in line with guidance from NICE [26]. Half-cycle correctionsFootnote 3 were applied to reduce the potential for bias in the cost estimates [28]. For both cohorts, total and disaggregated, per-patient discounted lifetime costs were calculated, and the cost impact associated with ‘good’ compliance evaluated. Furthermore, the resulting relationship between compliance and cost impact was calculated and expressed as a rate.
PSM: Reference survival curvesFor each cohort, both survival curves modelled (the SKF and OS curve) were generated by modifying a reference SKF curve, and reference OS curve, respectively. The reference curves represent observed survival patterns in the real world; they were derived from a long-term retrospective study (Brodin-Sartorius et al. (2012)) of clinical outcomes in a cohort of adult NC patients (n = 86, 51% male) in France [8]. In this study, patients were followed from diagnosis (mean age, 2.2 years) until adulthood (mean age at last follow up, 26.7 years) [8]. The study provided SKF and OS, Kaplan-Meier (KM) curves stratified by three subgroups: patients who began oral cysteamine treatment before the age of 5 (the ‘under 5’ group), those who began treatment after the age of 5 (the ‘over 5’ group), and those who had received no treatment until they had reached KF (the ‘no treatment’ group) [8]. Only the KM curves representing the ‘under 5’ subgroup (n = 40), were used to generate the reference curves applied, in the base case analysis of the present study. This is consistent with the assumption that this population represents most patients in the UK.
To model survival over the (lifetime) time horizon in the present analysis ─ beyond the study duration in Brodin Sartorius et al. (2012) [8] ─ a statistical analysis was performed to find a parametric function that best fit the KM data. As individual patient data (IPD) were not available for analysis, pseudo IPD were derived from the KM curves – by digitising the curves and applying the Guyot algorithm [29]. In line with NICE guidance, parametric survival curves (exponential, Weibull, log-normal, log-logistic, Gompertz, gamma, and generalised gamma distributions) were fitted to the pseudo IPD and then extrapolated over the model’s time horizon [30]. Following visual inspection and statistical testing (Akaike information criterion, Bayesian information criterion) the parametric distribution selected for both curves was the log-normal distribution (Supplementary Figs. 1–3; Supplementary Tables 1–3).
However, for OS, although the log-normal extrapolation had the best statistical fit, there was high uncertainty regarding extrapolations due to a significant loss to follow up after 20 years of age (i.e., death is an event that manifests later in the NC disease process). Therefore, model results were tested against all OS extrapolations to observe the sensitivity of results against these assumptions. In addition, data from the ‘over 5’ subgroup was used in a scenario analysis, for which the log-normal distribution was also deemed best-fitting. All curves chosen were validated by clinical experts.
The chosen parametric extrapolations were applied in this analysis with the assumption that risk (of KF and death) estimates are independent of each other. Therefore, for both cohorts, the resulting modelled SKF curve was adjusted by the mortality risks provided by the modelled OS curve.
PSM: Modelled SKF curvesIn the base case, for both cohorts, the reference SKF curve was modified to reflect the assumed mean time-to-KF values [13] ─ the resulting curves are henceforth referred to as the ‘modelled’ survival curves. This was achieved by deriving the hazard ratio (HR) necessary to produce the assumed mean time-to-KF, and adjusting the hazard rate in the survival function equation for the reference SKF by this HR. Table 3 provides the HRs applied and corresponding resulting mean time-to-KF values. The resulting (modelled) curves were validated by clinical experts.
Table 3 Parameters defining reference (log-normal) curves, and associated statisticsOf note, the reference SKF curve, derived from the study by Brodin-Sartorius et al. (2012) [8], was also suitable for representing disease progression for Poor Compliance patients; the data informing the reference curve represents patients in whom 71.8% had a mean leukocyte cystine level > 2 nmols (2 ≤ 34.6% < 3 nmols) [8]. However, the mean time-to-KF data provided by Nesterova et al. (2015) is also correlated with observed compliance, and forms the basis of the linear model applied in the current analysis [13]. For this reason, the modelled Poor Compliance SKF curve reflected the data provided in Nesterova et al. (2015) [13]. However, the reference SKF curve was used to validate the modelled SKF curve in a scenario analysis.
PSM: Modelled OS curvesIn the Poor Compliance cohort, the reference OS curve derived from Brodin-Sartorius et al. (2012) was used to model disease progression (i.e., the HR was assumed to be 1) [8]. The resulting mean time-to-death was 48.77 (as stated in a previous section). This was considered a reasonable approach because the data informing the reference OS curve represents a population who meet the definition of ‘poor compliance’ in this analysis ─ both the reference SKF curve OS curves are informed by the same population [8]. Furthermore, the resulting mean time-to-death was validated by clinical experts as being clinically plausible. In the Good Compliance cohort, the modelled curve was generated by applying a HR (Table 3) to the reference curve that would result in the difference between mean time-to-death for the Good Compliance and Poor Compliance cohorts being equal to the difference in mean time-to-KF for both cohorts. This resulted in a mean time-to-death of 56.37 (the value stated previously). Clinical experts consulted suggested that this assumption aligned with their observations in the clinical setting and supported the argument that the beneficial impact of compliance in terms of delayed SKF should also be reflected in OS. However, given the uncertainty, sensitivity analyses were conducted to validate the modelled Good Compliance OS curve ─ by making both conservative and optimistic assumptions regarding the curve.
Cost inputsThe cost of KF was applied in terms of an annual cost. This annual cost was generated through a micro-costing approach in which specific costs were applied to the different stages of a KF model: (a) the waiting list for a transplant; (b) undergoing first transplant; (c) the period between first transplant and transplant failure; (d) undergoing second transplant (the representative patient was assumed to undergo 2 transplants; clinical experts suggested that this is the median number of transplants over a patient’s lifetime); and (e) the period between the second transplant and transplant failure. The specific costs applied were: (a) the monthly cost of dialysis, (b) the initial (first year) annual cost of a transplant, and (c) the subsequent (year 2 and onwards) monthly costs of maintenance post-transplant. It was assumed that these costs would be incurred, in the relevant stages, in the ‘post KF’ state. Therefore, for each cohort, the number of months spent in the ‘post KF’ state was calculated (33.37 years) and used to generate a survival curve, with an assumed exponential distribution, representing patient progression through this state. Estimates of the expected time on the transplant waiting list (9.04 months), and time to transplant rejection/failure (20.62 years) (Table 4) in the real world were applied to these curves to evaluate the mean number of months spent in each of the KF model stages (Table 5). These duration values were multiplied by the relevant unit costs described above to arrive at a mean total cost of KF. These costs were converted into an annual cost of £10,329.65 for patients in both cohorts (Tables 4 and 5).
Table 4 Resource Inputs and Cost Inputs for post KF management (micro-costing)Table 5 Results of micro costing calculations*The expected time on the transplant waiting list was a weighted average with weights corresponding to the prevalent proportion of paediatric (16 years old and under) patients receiving a transplant from a living donor (37.66%) or deceased donor (62.34%) in the UK – these proportions were derived from the UK Renal Registry 23rd annual report, published in 2021 [31]Footnote 4. Based on clinical expert guidance and data provided by the NHS [32], the corresponding wating times were 0 months for patients with a living donor (as these transplants are generally conducted pre-emptively) and 24 months for patients with a deceased donor, resulting in a weighted average waiting time of 9.04 months (Table 4). Similarly, the expected time to transplant rejection/failure was a weighted average (20.62 years) calculated based on the same weights (37.66% for deceased donors, and 62.34% for deceased living donor), corresponding to graft failure times of 17.50 years and 22.50 years for deceased and living donors respectively (Table 4).
Table 6 Discounted lifetime kidney failure costsTo generate the unit costs of transplants, data were derived from a study by Kent et al. (2015) [27]. This is a study of the annual costs of hospital care for patients with chronic kidney disease in the UK using prospective data from the Study of Heart and Renal Protection trial (n = 7246) [34]. The study provided an estimate of annual direct healthcare costs (hospital admissions and outpatient/day-case attendances) in the first year, post kidney transplant, and for subsequent years of kidney transplant care. Of note, hospital care related adverse events were incorporated into the costs provided by Kent et al. (2015) but disaggregated costs were not provided. These figures were provided in 2010/11 prices and inflated to 2019/20 prices using the hospital & community health services index, and the NHS cost inflation index, provided by the Personal Social Services Research Unit in the UK. In the current analysis, the annual cost for subsequent years was converted into months, whereas all patients undergoing a transplant were assumed to incur the full annual cost in the first year, post-transplant, given that this encompassed the cost of a transplant.
The cost of dialysis was split into two elements: the cost of haemodialysis and cost of peritoneal dialysis. Both were calculated using weighted averages of paediatric and adult dialysis annual costs from the National Schedule of NHS Costs 2019/20 [33] (Supplementary Tables 4–5). They were converted to monthly costs based on the assumption that haemodialysis is required three times per week whilst peritoneal dialysis is conducted daily (Table4) – both assumptions were verified by clinical experts. To develop a mean monthly cost relevant to the UK setting, the distribution of patients across the two modalities was estimated. UK-specific data regarding the prevalence of patients on dialysis and the breakdown by modality were sourced from the UK Renal Registry 23rd annual report [
留言 (0)