
記住我

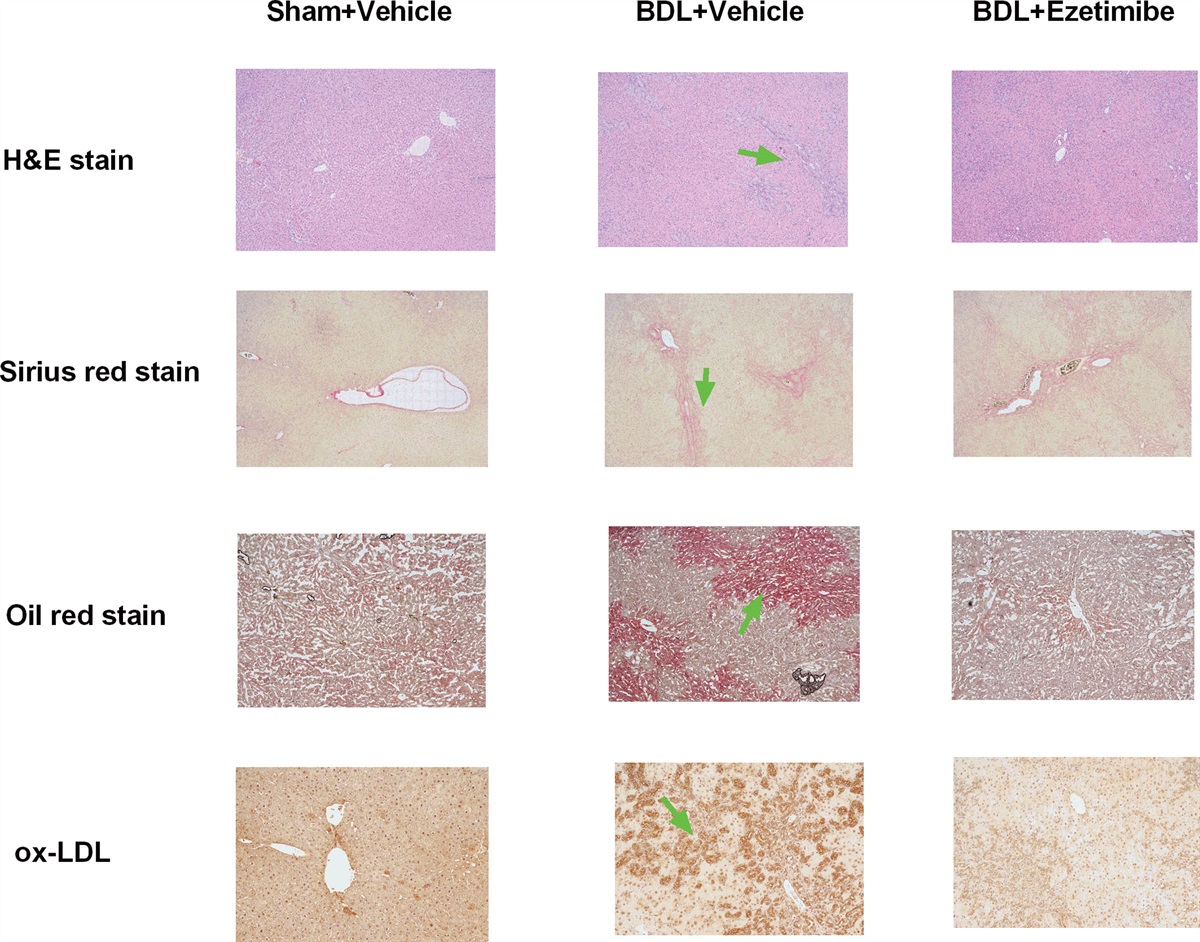



Reduced birth rates and increased life expectancy have driven population aging in the developed world, but these trends in recent years are increasingly apparent in the developing world as well, with the general exception of Africa.1 By 2030, the World Health Organization estimates the global population older than 60 years will be 1.4 billion, a 40% increase from 2019.2 As of 2018, 14.3% of Taiwan’s population was older than 65 years.3 Aging is related to many comorbidities such as cancer, metabolic disease, and cardiovascular disease, making it an imperative concern for governments and healthcare providers.4 One key comorbidity is osteoporosis, a degenerative condition that particularly affects women. The World Health Organization defines osteoporosis as bone mineral density (BMD) more than 2.5 SDs below that of the mean of young adults (T-score ≤ −2.5) based on the dual-energy x-ray absorptiometry measurements.3 Kanis5 reported that the elderly experiences a 10-fold increase in 10-year fracture rate compared with younger individuals. Besides from the pain and suffering osteoporosis directly imposes on sufferers, it also creates a huge financial burden for governments and national health systems. Kemmak et al6 noted that the treatment of osteoporosis-related fractures costs Western countries (Canada, Europe, and United States) an average of USD 5000 to 6500 billion annually, without accounting for costs related to subsequent disability.
Several studies have investigated risk factors for osteoporosis, with a particularly high concentration conducted in Korea,7–10 and most of which treat osteoporosis as a binary variable7,8,11 using logistic regressions to calculate the receiver operation curve. In such calculations, a larger area indicates a higher degree of model accuracy. However, logistic regressions are considerably less informative than multiple linear regressions (MLRs). In assessing the relationship between risk factors and BMD, greater accuracy can be obtained using the T-score of the BMD as an independent variable (y) to provide quantitative observations. Recently, machine learning methods have emerged as a new data analysis method that is competitive with MLR.12,13 Machine learning can capture nonlinear relationships in data and complex interactions among multiple predictors, and therefore, can potentially outperform conventional MLR in disease prediction.14
The present study enrolled 24 412 women in Taiwan older than >55 years, collecting information on 25 BMD-related risk factors, applying traditional MLR and five machine learning methods to investigate the relationships between risk factors and T-score. Our purposes were as follows:
To compare the prediction accuracy between machine learning and traditional MLR. To rank the relative importance of the 25 risk factors. 2. METHODS 2.1. Participant and study designThe data for this study were obtained from the Taiwan MJ cohort, an ongoing prospective cohort of health examinations performed by the MJ Health Screening Centers in Taiwan.15 These health examinations include more than 100 crucial biological indicators, such as anthropometric measurements, blood tests, and imaging tests. In addition, each participant completed a self-administered questionnaire to gather information on personal and family medical history, current health status, lifestyle, physical exercise, sleep habits, and dietary habits.16 The MJ Health Database only comprises individuals who have given informed consent. All or part of the data used in this research were authorized by and received from the MJ Health Research Foundation (Authorization Code MJHRF2020018A). Any interpretations or conclusions described in this article are those of the authors alone and do not represent the views of the MJ Health Research Foundation.17 The study protocol was approved by the Institutional Review Board of the Kaohsiung Armed Forces General Hospital (IRB No. KAFGHIRB 109-041). In total, 68 144 healthy participants were enrolled. After excluding subjects with different causes, 24 412 subjects remained for analysis, as shown in Fig. 1.
 Fig. 1:
Fig. 1: Flowchart of sample selection from the MJ osteoporosis study cohort. MJ = MJ Health Database.
MJ senior medical staff documented each subject’s medical history, including details of their current medications, and conducted a comprehensive physical examination. The waist circumference was measured at the natural waist level in a horizontal position. To calculate the body mass index (BMI), the participant’s weight (in kg) was divided by the square of their height (in meters). The systolic blood pressure (SBP) and diastolic blood pressure (DBP) were measured while the subject was seated using standard mercury sphygmomanometers on their right arm.
The procedures used to collect demographic and biochemical data have been previously documented.18 Participants had fasted for 10 hours before blood draw for biochemical analyses. Within 1 hour of collection, plasma was separated from the blood and kept at 30°C until analysis for fasting plasma glucose (FPG) and lipid profiles. FPG was measured using the glucose oxidase method (YSI 203 glucose analyzer; Yellow Springs Instruments, Yellow Springs, OH). Total cholesterol and triglyceride (TG) levels were measured using the dry multilayer analytical slide method with a Fuji Dri-Chem 3000 analyzer (Fuji Photo Film, Tokyo, Japan). The serum concentrations of high-density lipoprotein cholesterol (HDL-C) and low-density lipoprotein cholesterol (LDL-C) were determined through enzymatic cholesterol assays, following dextran sulfate precipitation. Urine albumin to creatinine ratio (ACR) was determined using turbidimetry and a Beckman Coulter AU 5800 biochemical analyzer.
Table 1 defines the 25 baseline clinical variables used as predictor variables, with T-score used as the dependent (target) variable. The independent variables include sex, age, BMI, duration of diabetes, smoking, alcohol use, FPG, glycated hemoglobin, TG, HDL-C, LDL-C, alanine aminotransferase, creatinine, SBP, and DBP (Table 2). Pearson correlation is used to evaluate the simple correlation between T-score and all other variables. Wilcoxon sign rank test is used to compare the performance of MLR and the other five machine learning methods.
Table 1 - Participant demographics Variables Mean ± SD n Age, y 62.5 ± 6.4 24,411 Body mass index, kg/m2 24.3 ± 3.6 24,405 Leukocyte, 103/μL 5.7 ± 1.6 24,402 Hemoglobin, g/dL 13.4 ± 1.0 24,401 Fasting plasma glucose, mg/dL 109.9 ± 29.2 24,402 Serum glutamate oxaloacetic transaminase, IU/L 26.7 ± 24.6 24,392 Serum glutamate pyruvate transaminase, IU/L 27.6 ± 27.5 24,393 Estimated glomerular filtration rate, mL/min/1.73 m2 73.3 ± 13.5 11,664 Uric acid, mg/dL 5.3 ± 1.3 24,392 Triglycerides, mg/dL 125.6 ± 81.2 24,401 High-density lipoprotein cholesterol, mg/dL 60.4 ± 15.0 24,161 Low-density lipoprotein cholesterol, mg/dL 129.0 ± 33.5 24,150 Plasma calcium concentration, mg/dL 9.4 ± 0.4 22,095 Plasma phosphate concentration, mg/dL 3.8 ± 0.4 22,092 Thyroid stimulating hormone, μIU/mL 2.0 ± 3.9 23,055 C-reactive protein, mg/dL 0.3 ± 0.6 22,817 Sport hour/week, h 3.3 ± 4.1 21,174 Systolic blood pressure, mmHg 130.7 ± 20.3 24,409 Diastolic blood pressure, mmHg 74.6 ± 11.6 24,409 T-score −1.5 ± 1.6 24,411 n (%) N Gender 24,411 Female 24,411 (100) Marriage status 21,889 No 6,916 (31.6) Yes 14,973 (68.4) Education 22,847 Illiterate 3,411 (14.9) Elementary school 9,610 (42.1) Junior high school (vocational) 2,862 (12.5) High school 3,846 (16.8) Junior college 1,442 (6.3) University 1,420 (6.2) Graduate school or above 256 (1.1) Family income 22,495 None 2,943 (13.1) No 5,394 (24.0) Below $12 493 4,843 (21.5) $12 805-$24 986 4,448 (19.8) $25 298-$37 478 2,842 (12.6) $37 790-$49 971 940 (4.2) $50 283-$62 464 481 (2.1) More than $62 776 604 (2.7) Sleeping time/day, h 22,110 0-4 910 (4.1) 4-6 7,543 (34.1) 6-8 12,426 (56.2) More than 8 h 1,231 (5.6) Smoking status 22,518 No 21,431 (95.17) Yes 1,087 (4.8) Drinking 20,874 No 19,909 (95.4) Yes 965 (4.6)*p < 0.05,
** p < 0.01,
***p < 0.005.
BMD = bone mineral density; BMI = body mass index; CRP = C-reactive protein; DBP = diastolic blood pressure; eGFR = estimated glomerular filtration rate; FPG = fasting plasma glucose; GOT = serum glutamate transaminase; GPT = serum glutamate pyruvate transaminase; HB = hemoglobin; HDL-C = high-density lipoprotein cholesterol; LDL-C = low-density lipoprotein cholesterol; SBP = systolic blood pressure; TG = triglyceride; TSH = thyroid stimulating hormone; UA = uric acid.
This study proposes a predictive scheme for T-score using five machine learning methods, including classification and regression tree (CART), Naïve Bayes (NB), random forest (RF), stochastic gradient boosting (SGB), and eXtreme gradient boosting (XGBoost). These methods were selected as they have been used in different healthcare applications and do not require any prior assumptions about data distribution.19–28 To evaluate the efficacy of our proposed scheme, we used MLR as a benchmark for comparison. We also identify the importance of various risk factors for predicting T-score.
The first method, CART, is a tree-structure method,29 comprising root nodes, branches, and leaf nodes that grow recursively based on the tree structures from the root nodes and split at each node using the Gini index to produce branches and leaf nodes. The pruning node in the overgrown tree generates different decision rules to create an optimal tree size using the cost-complexity criterion, resulting in a complete tree structure.30,31
NB, another machine learning model used in this study, is widely used for classification tasks. This algorithm can sort objects according to specific characteristics and variables based on the Bayes theorem, estimating the values of dependent variable (y).32
The third method in this study is RF, an ensemble learning decision tree algorithm that combines bootstrap resampling and bagging.33 RF works by randomly generating many different and unpruned CART decision trees, where the decrease in Gini impurity is used as the splitting criterion. All the trees generated are combined into a forest and then averaged or voted to generate output probabilities and a final model that provides a robust prediction.34
The fourth method is SGB, a tree-based gradient boosting learning algorithm that uses a combination of bagging and boosting techniques to address the overfitting problem of traditional decision trees.35,36 SGB generates many stochastic weak learner trees through multiple iterations. Each tree focuses on correcting or explaining the errors of the tree generated in the previous iteration, using the residual of the previous iteration tree as input for the newly generated tree. This iterative process is repeated until the convergence condition or the maximum number of iterations is reached. Finally, the cumulative results of many trees are used to determine the final robust model.
XGBoost is an optimized extension of SGB that utilises gradient boosting technology.37 The algorithm trains many weak models sequentially and ensembles them to achieve better prediction performance. XGBoost uses Taylor binomial expansion to approximate the objective function and generate arbitrary differentiable loss functions to accelerate model convergence.38 It also applies a regularized boosting technique to penalize model complexity and prevent overfitting, which helps to improve model accuracy.39
Fig. 2 depicts the proposed scheme for prediction and variable identification, which incorporates four different machine learning methods. Initially, patient data were collected and used to prepare the dataset, which was then randomly split into a training dataset and a testing dataset on an 80/20 ratio. Hyperparameters for each machine learning method were tuned using a 10-fold cross-validation technique. The training dataset was further divided into a training dataset for model building and a validation dataset for model validation, using grid search to explore all possible hyperparameter combinations. The best model for each machine learning method was selected based on the lowest root mean square error for the validation dataset, and the variable importance ranking information was obtained for CART, NB, RF, SGB, and XGBoost.
 Fig. 2:
Fig. 2: Proposed Mach-L prediction scheme. CART = classification and regression tree; CV = cross-validation; ML = machine learning; NB = Naïve Bayes; SGB = stochastic gradient boosting; XGBoost = eXtreme gradient boosting.
During the testing phase, the performance of the best machine learning models was evaluated using the testing dataset. Because the target variable in this study is a numerical variable, the model performance was compared using different metrics, including symmetric mean absolute percentage error, relative absolute error, root relative squared error, and root mean squared error. The values for these metrics are listed in Table 3. The machine learning methods and MLR were compared using the Wilcoxon signed rank test because only 10 values were derived from each method so they are nonparametric variables.
Table 3 - Equation of performance metrics Metrics Description Calculation SMAPE Symmetric mean absolute percentage errorSMAPE=1n∑ni=1yi−y^i(yi+y^i)/2×100
RAE Relative absolute errorRAE=∑i=1n(yi−y^i)2∑i=1n(yi)2
RRSE Root relative squared errorRRSE=∑i=1n(yi−y^i)2∑i=1n(yi−y^i)2
RMSE Root mean squared errorRMSE=1n∑ni=1(yi−y^i)2
n = number of instances; yi = actual value;y^i
= predicted value.To ensure a more reliable and stable comparison, the training and testing processes were repeated 10 times. The performance metrics of these five machine learning models were then averaged to compare with the performance of the benchmark MLR model. The same training and testing datasets were used for both the machine learning methods and the MLR model. A model with an average metric lower than that of the MLR model was considered a more convincing model.
Because all the machine learning methods used can rank the importance of each predictor variable, we defined the priority demonstrated in each model ranked 1 as the most critical risk factor and 25 as the last selected risk factor. The machine learning methods used in this study may produce different rankings of variable importance due to their unique modeling characteristics. To increase the stability and reliability of our findings, we integrated the variable importance rankings of the pricier machine learning models. In the final stage of our proposed scheme, we summarize and discuss our significant findings based on the pricier machine learning models and identify the most important variables.
The study was conducted using R software, version 4.0.5, and RStudio, version 1.1.453, with the required packages installed.40,41 The RF, SGB, CART, and XGBoost methods were, respectively, implemented using the “randomForest” R package, version 4.6-1442; “gbm” R package, version 2.1.843; “rpart” R package, version 4.1-1544; and “XGBoost” R package, version 1.5.0.2.45 The “caret” R package, version 6.0-90, was used to determine the best hyperparameters for the developed CART, RF, SGB, and XGBoost methods.46 MLR was implemented using the “stats” R package, version 4.0.5, with the default settings.
3. RESULTSA total of 24 412 participants were enrolled in the study, with demographic data summarized in Table 1 (mean ± SD). The results of Pearson correlation are presented in Table 2, showing that BMI, uric acid (UA), plasma calcium level, income, HDL-C, GPT, FPG, hemoglobin, TG, TSH, plasma phosphate level, and sport were positively correlated to T-score, whereas negative correlations were found for leukocyte and age.
Table 4 compares traditional MLR and the four machine learning methods in terms of T-score prediction performance. Using Wilcoxon signed rank test, all four machine learning methods significantly outperformed MLR in terms of prediction error and were all convincing machine learning models.
Table 4 - The average performance of CART, SGB, XGBoost compared to MLR by Wilcoxon signed rank test SMAPE RAE RRSE RMSE Linear 1.077 ± 0.009 1.131 ± 0.007 1.138 ± 0.005 1.785 ± 0.018 CART* 1.025 ± 0.009 1.099 ± 0.004 1.11 ± 0.004 1.74 ± 0.014 NB* 1.077 ± 0.009 1.131 ± 0.007 1.138 ± 0.005 1.785 ± 0.018 RF* 1.078 ± 0.007 1.127 ± 0.007 1.135 ± 0.007 1.779 ± 0.018 SGB* 1.065 ± 0.008 1.12 ± 0.006 1.128 ± 0.006 1.769 ± 0.018 XGboost* 1.068 ± 0.009 1.121 ± 0.006 1.129 ± 0.005 1.771 ± 0.017*p < 0.05 compared to linear.
CART = classification and regression tree; MAPE = mean absolute percentage error; MLR = multiple linear regression; NB = Naïve Bayes; RAE = relative absolute error; RF = random forest; RMSE = root mean squared error; RRSE = root relative squared error; SGB = stochastic gradient boosting; SMAPE = symmetric mean absolute percentage error; XGBoost = eXtreme gradient boosting.
Tables 5 and 6 present the average importance ranking of each factor generated by the CART, SGB, NB, RF, and XGBoost methods. The different machine learning methods generated different relative importance rankings for each factor. The shade of gray indicates the importance of risk factors, with darker shades indicating a more important risk factor. For instance, in the RF method, the most important factors were baseline BMI, age, and UA. To fully integrate the importance rankings of each factor in all the five machine learning methods, the average importance ranking of each risk factor was obtained by averaging the ranking values of each variable in each method (the right-hand column). Fig. 3 showed that age was the most important factor to determine T-score, followed by estimated glomerular filtration rate (eGFR), BMI, UA, education level, and family income in Chinese women older than 55 years.
Table 5 - The results of Wilcoxon signed rank test between four machine learning methods and MLR MLR CART RF SGB XGBoost SMAPE 2.521 (0.01)** −0.771 (0.44) 2.521 (0.01)** 2.521 (0.01)** RAE 2.521 (0.01)** 2.38 (0.01)** 2.521 (0.01)** 2.521 (0.01)** RRSE 2.521 (0.01)** 2.1 (0.03)** 2.521 (0.01)** 2.521 (0.01)** RMSE 2.521 (0.01)** 1.96 (0.04)** 2.521 (0.01)** 2.521 (0.01)**The results of the negative binomial (NB) model were not displayed, as the performances were presented as numeric values within parentheses, with the corresponding p-values.
**p < 0.05.
CART = classification and regression tree; MLR = multiple linear regression; RAE = relative absolute error; RF = random forest; RMSE = root mean squared error; RRSE = root relative squared error; SGB = stochastic gradient boosting; SMAPE = symmetric mean absolute percentage error; XGBoost = eXtreme gradient boosting.
留言 (0)