
Remember me







There are no known public sources for CDISC Standard for Exchange of Nonclinical Data (SEND) data, so organizations will likely need to build internal databases or external sharing arrangements with CRO’s to store data for local operations [23].
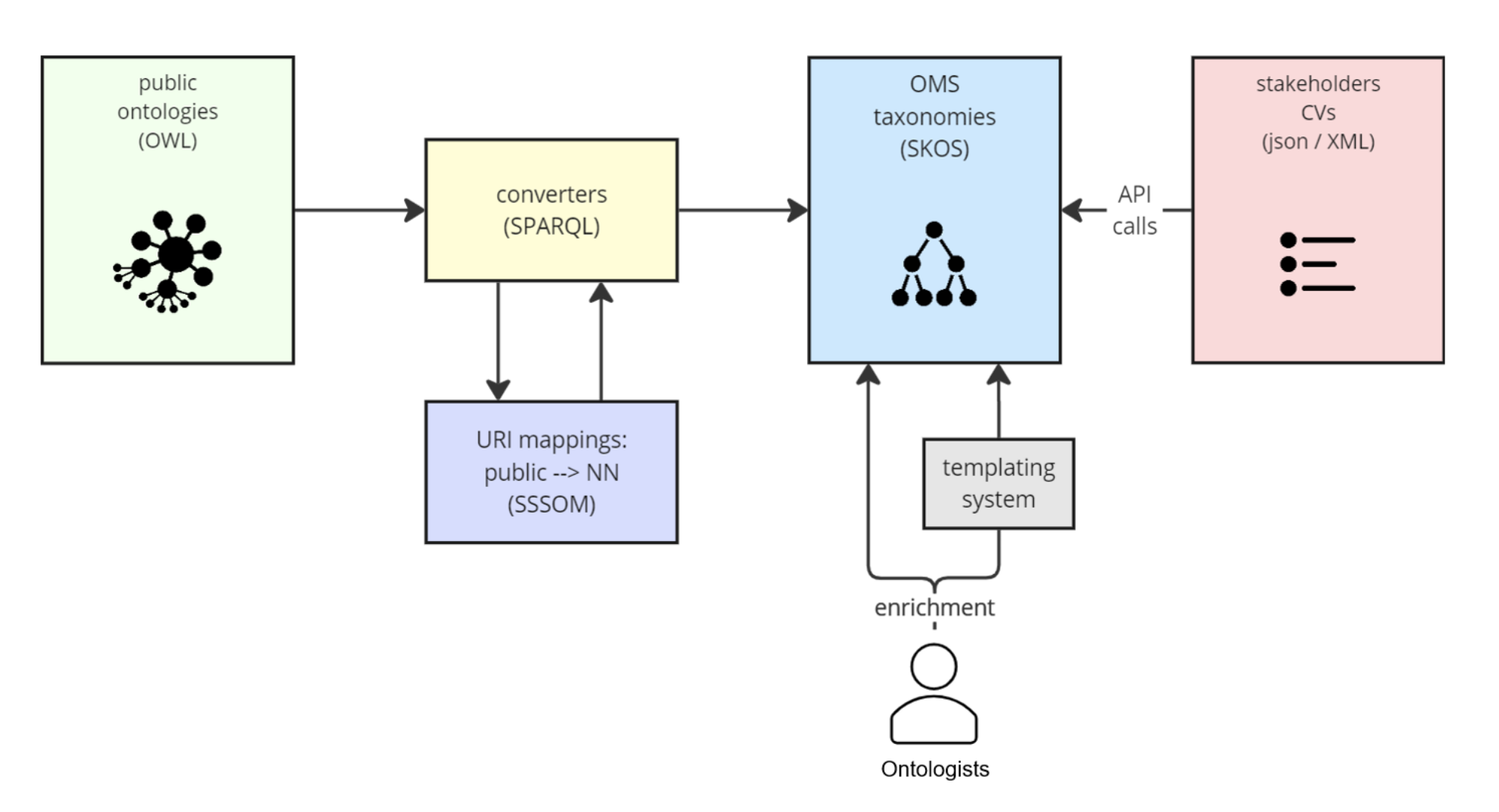
Due to a lack of unambiguous standardization within and across systems used in the Pre-Clinical eco-system as illustrated in the representative example in Fig. 4, data integration historically has been and often remains a manual task [24]. Data processing is often executed iteratively whereas data is generated continuously at varying scales of biological complexity. Moreover, Pre-Clinical data is often stored in an unstructured manner in siloed systems that are not properly connected to the rest of the eco-system [25].
Fig. 4
Representative Model of a Pre-Clinical eco-system
Assay data classification based on PK and PD classes incorporated into BAO will help to standardize Pre-Clinical (In vivo, Ex vivo, and In vitro) internal and external data sources according to the FAIR principles (Findability, Accessibility, Interoperability, and Reusability) [3]. This approach explores a framework for development of end point specific results (e.g., histopathology findings, assay measurements) assembled in a user-defined subset of studies for cross study analysis.
If all Pre-Clinical data can be stored consistently using semantically rich domain-based ontologies along with contextual metadata as a data set, seamless flow of data across the integrated eco-system will provide an opportunity to apply large scale data analytic approaches [26, 27] for cross study analysis in a cohesive manner.
In the following paragraphs four practical Use Cases are described that showcase the usefulness of standardized assay metadata.
ADME and PD assay Registration with metadata assignment based on standard bioassay ontology BAO (SANOFI)Sanofi’s assay data model was redesigned based on the new ADME and PD standard assay ontology, which was defined and integrated into BAO by the Pistoia SEED Project Team. Now all ADME and PD assay metadata are standardized and aligned with a minimum set of ontology classes from BAO (Fig. 5).
Fig. 5
Sanofi’s Assay Data Model
It is planned to use SciBite’s CENtree Ontology Management Platform [28] to feed BAO classes via API into an application for assay registration. The objective is to register all assays with a standardized set of mandatory metadata according to the FAIR principles; particularly this will improve
Findability to support Project progression
Interoperability with internal and external data (coming for instance from a CRO)
Reusability for data analytics and data science applications.
Semantic tagging of unstructured lab reports based on BAO to identify and extract standardized metadata for assay registration in central repository (SANOFI)Ontologies managed in CENtree are planned to be used as source vocabularies in SciBite’s TERMite Text Analytics and Semantic Enrichment platform [29] that can, in turn, be used for automatic annotation of unstructured data with the same ontologies used for structured data. For example, a Lab Report describing an ADME assay will be uploaded into an eLN with embedded semantic enrichment function and automatically annotated with the ADME/PD classes from BAO. The annotation will be used to automatically assign BAO classes as metadata to the assay. The ultimate goal is to extract as many metadata as possible from unstructured reports which will be facilitated by adding reasonable synonyms to the BAO classes in in CENtree and TERMite (Fig. 6).
Fig. 6
SEED eLN unstructured data annotation workflow
Semantic tagging of unstructured content to enable identification and selection of data for submission reports for module 4 of an eCTD (Pfizer)Another Use Case relying on BAO classes is pursued by Pfizer to support regulatory study report creation. More specifically, the goal is to combine the use cases above, semantically enabling both structured and unstructured data. Tagging unstructured content in the eLN, and application of the consistent ontology standards from the assay registration system into the eLN to benefit identification and selection of data for ADME and PD submission reports supporting Module 4 of an eCTD. ADME and PD experiments and studies available in an eLN or LIMs will be semantically tagged with the BAO class “bioassay type ADME” or “bioassay type PD” in addition to the assay term name and any mapping to CDSIC SEND Study type and/or CTD Safety M4S(R2) Non-clinical study report section (to be added to BAO). This will enable users in part (with addition of data specifying Compound, Species, Route of Admin etc) to search for the specific experiment data using the newfound FAIR data infrastructure to drive advances in automated regulatory study report creation.
Modular design of data capture in the electronic notebook using ontologic terminology to facilitate downstream data consumption (Merck)An additional use case for the subject ontology of this manuscript, as well as other well-formed public ontologies, is to drive the creation of modular and consistent data capture at the point of data creation in the electronic notebook. Modular electronic notebooks typically have an overarching information model that organizes high level experiment concepts in a single meta model. However, often these tools allow individual users / organizations to configure the electronic notebook via templates to consistently structure and contextualize selected content in experiments. There are many scientific workflows across the various scientific domains addressed with an electronic notebook, so driving consistency in data capture to yield the downstream benefits during data consumption (data aggregation, analytics, visualization, data science, etc) can seem daunting. However, if approached in a modular fashion with reusable content across templates where possible, one creates manageable-sized data standardization problems to solve.
To drive standardized data capture in the electronic notebook, Merck is decomposing typical experiment designs across various scientific domains into the frequently reused smaller components that are either generally used across experiments, or typically used within a specific scientific domain. A centralized master conceptual model organizes ontologies across scientific domains into a single context and source of truth across domains to ensure consistent use of the concept. Finally, these ontologies are embedded in the reusable elements in the notebook, which are used to compose the experimental templates used for standardized data capture. The end result should be a better user experience for scientists who can quickly capture data in a more consistent fashion, knowing it will simplify on-demand downstream data mining and analysis for themselves and their colleagues. Product owners / administrators will find the semantically enabled electronic notebook more scalable since content is intentionally reused across templates to drive standardization. Holistically, embedding these ontological terms into electronic notebook data capture links each experiment back to the master conceptual data model, creating the possibility of greater data exploration across not only the notebook but other knowledge assets leveraging the ontologies as well.
Comments (0)