
Remember me
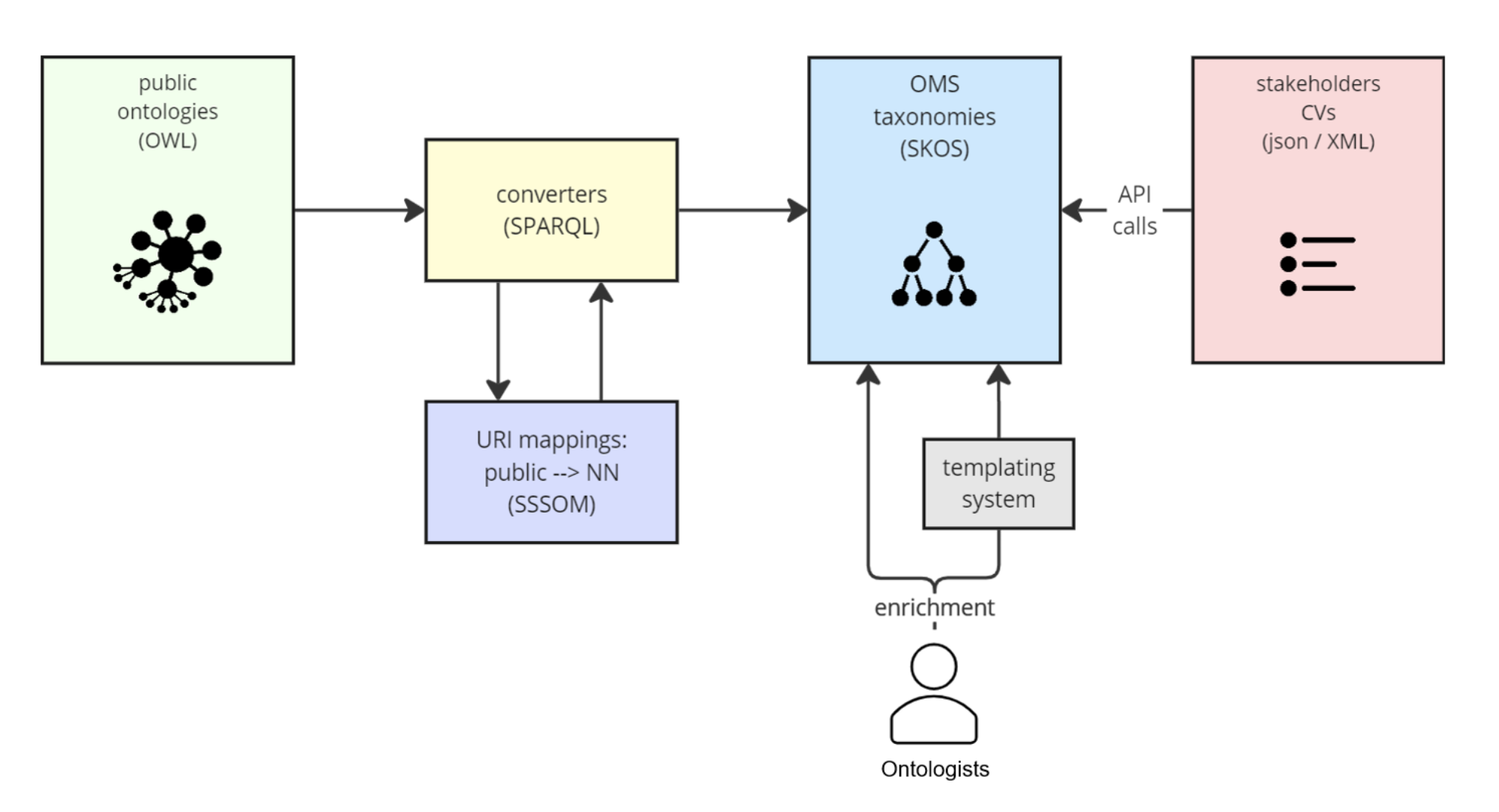







Initially, the SPHN Semantic Interoperability Framework defined semantics in the SPHN Dataset spreadsheet (.xlsx), aligning with international standards and models [15,16,17,18]. The tabular format offers an efficient structure for simple datasets and is understood by diverse experts (e.g. clinicians, data analysts, data engineers) given its wide use across scientific domains for data sharing [19, 20]. However, tables struggle to represent complex relationships and hierarchies and are not easily machine processable. This poses a barrier to both interoperability and automated data reuse making them insufficient to support the goals of SPHN.
To address these limitations, Semantic Web standards were adopted, transforming tabular data into more expressive, machine-readable formats, and enabling integration with other standard terminologies and vocabularies [21].
The Semantic Web is an extension of the World Wide Web to enable machine-readable representation and sharing of data and its semantics across systems. At the core of the Semantic Web are a set of standards and technologies developed by the World Wide Web Consortium (W3C) that provide a formal and structured way of representing knowledge [4]. These standards serve as the foundation for enabling interoperability between systems [22,23,24,25,26].
A fundamental building block of the Semantic Web is RDF [6], a graph-based data model designed to represent knowledge as triples. Each triple consists of the subject, a predicate, and an object which results in a directed graph structure that models information about entities and relationships between entities.
RDF Schema (RDFS, [27]) builds on RDF for describing schemas by defining classes, properties, hierarchical structures and relationships between resources. However, RDFS has limited expressivity when it comes to defining more complex relationships and constraints, which is typical when considering biological, biomedical and clinical knowledge. To address these limitations, the Web Ontology Language (OWL, [28]) was introduced. OWL offers a rich language for defining the meaning of concepts and their relationships, including cardinality and value set restrictions, all of which are useful in the context of SPHN.
Although RDF, RDFS and OWL provide the mechanism for representing knowledge as a schema, they do not ensure that the RDF data conforms to specific constraints or expected structures. This is where the Shapes Constraint Language (SHACL, [7]) comes into play. SHACL provides a way to validate RDF data against a defined set of conditions (i.e. shapes), enabling quality control and conformance of the data.
Another crucial component is the SPARQL Protocol and RDF Query Language (SPARQL [8]), a query language designed for retrieving and manipulating RDF data. It allows users to express complex queries and to query multiple RDF data sources at once.
In SPHN, these technologies formalize the SPHN Dataset into the SPHN RDF Schema, ensuring that the semantics are both machine-readable and compliant with the FAIR principles [5]. Over time, the framework evolved to incorporate additional components like SHACL constraints for facilitating data validation, SPARQL queries for data exploration, and even a Hypertext Markup Language (HTML) documentation for a human-readable version of the semantics. These elements collectively form the SPHN Semantic Interoperability Framework, a package that enables researchers to request and analyze standardized data while allowing data providers to validate and structure their data consistently.
SPHN DatasetAt the heart of this framework lies the SPHN Dataset. All elements of the SPHN RDF Schema are either explicitly defined in the Dataset or derived through well-established conventions and modeling rules, enabling a fully automated transformation. The SPHN Dataset is the main input to the SPHN Schema Forge. It is a structured spreadsheet that provides a detailed description of the semantics defined within the SPHN Semantic Interoperability Framework. It serves as both a reference document for researchers, data providers, clinicians, and other stakeholders, and as primary resource for generating the SPHN RDF Schema.
The SPHN Dataset is developed and maintained by the SPHN Data Coordination Center (SPHN DCC), ensuring that the core semantics are aligned with international standards, consistently versioned, and documented. However, the framework also supports flexibility by allowing individual projects to extend the Dataset to meet their needs.
For validating the framework in real-world settings, SPHN established four large multicentric consortia in key disease areas (Infectious Diseases, Oncology, Pediatrics, and Quality Care), serving as national data streams [29]. These projects can add new concepts, define additional coding systems, or refine value sets to capture study-specific semantics. While this adaptability supports a broad range of use cases, it also introduces complexity for ensuring consistency, traceability, and interoperability across versions and use cases. Hence, strict conventions and guidelines for semantic modeling are defined. The organization of the SPHN Dataset ensures clarity and uniformity, which is crucial for the next step in the process: automatically formalize the Dataset into semantic artifacts.
The SPHN Dataset consists of six distinct tabs:
Guideline: Introduces the Dataset and describes its content including a list of abbreviations, descriptions of the tabs and their respective columns
License: Outlines the licenses applicable to the Dataset and the main resources used
Release Notes: Documents the changes across releases, including a detailed list of newly introduced concepts
Metadata: The metadata for the RDF schema (e.g. prefix, title, description, license)
Coding System and Version: Lists coding systems or standards (e.g. classifications, ontologies) referenced in the Dataset, along with metadata to facilitate their import in the RDF schema and enable the linking to standard codes
Concepts: Lists all concepts and their attributes defined in the Dataset.
Among these, three tabs, ‘Metadata’, ‘Coding System and Version’, and ‘Concepts’ are processed by the SPHN Schema Forge, further described below.
Metadata TabMetadata is a critical component of the FAIR principles which ensures clarity, provenance and proper documentation of data. In the Dataset, the ‘Metadata’ tab serves to annotate the metadata for the RDF schema. It must be properly filled for both the SPHN and project-specific RDF schemas to be properly interpreted during the RDF schema generation. In SPHN, the following metadata elements are required:
Prefix: The namespace prefix for the RDF schema (e.g. sphn)
Title: A short title of the RDF schema (e.g. The SPHN RDF Schema)
Description: A short description of the RDF schema
Version: The version of the current RDF schema (e.g. 2025.1)
Prior version: Any previous version from which the current RDF schema is derived (e.g. 2024.2)
Copyright and license: Information on intellectual property and reuse possibilities of the RDF schema
Canonical and versioned IRIs: The unique and versioned identifiers of the RDF schema.
Coding System and Version TabTo enhance interoperability, SPHN semantics often reference known external standards (e.g. Anatomical Therapeutic Chemical classification (ATC [15]), Systematized Nomenclature of Medicine Clinical Terms (SNOMED CT [17, 30]), International Statistical Classification of Diseases and Related Health Problems 10th Revision German Modification (ICD-10-GM [18])). This tab records which coding systems are used along with the necessary metadata for linking them in RDF. In SPHN, these standards are used to annotate values in particular contexts or to establish a ‘meaning binding’ to the concepts (i.e. the concept’s definition aligns with a specific code). When a meaning binding or value set is defined with a specific terminology in the ‘standard’ columns of the ‘Concept’ tab, the corresponding terminology must be referenced in the ‘Coding System and Version’ tab: a new line should be created with the relevant metadata.
In the 2025.1 version of the SPHN Dataset [31], a total of 38 coding systems are referenced. To fully leverage the linked data principles of the Semantic Web, it is ideal for these terminologies to be provided in RDF format. However, only 18 were either already accessible in RDF from the provider (e.g. Ontology for Biomedical Investigations [32], Evidence and Conclusion Ontology [33], Orphanet Rare Disease Ontology [34]) or transformed into RDF format by the DCC Terminology Service pipeline [21] and then made available. The metadata for these RDF-available standards are processed in the SPHN Schema Forge to ensure that the RDF schema properly links to these external coding systems. More information on how to fill this tab can be found in the SPHN Documentation [35].
If a project requires a standard not listed, they can extend the list by also specifying in which context it is used. However, it is the responsibility of the project to ensure compliance with any licensing requirements and, if necessary, to develop adequate pipelines for transforming the standard into RDF if not already available.
Concepts tabThe ‘Concepts’ tab is central for defining semantics. It consists of a single tab with 23 columns (described in Table 1), which must be accurately filled with the list of relevant concepts to enable the automated transformation of semantics into RDF. Figure 1A presents one example of such concept and its properties with the 'Billed Diagnosis' concept as seen in the SPHN Dataset. Each row represents either a concept (class) or a composedOf (attribute), with each column providing specific information about that concept or attribute. In the case of the 'Billed Diagnosis', we are building a concept to represent data about diagnosis at the time of discharge, used for the billing system at a hospital. The ‘parent’ column indicates that this concept inherits from a more generic concept called ‘Diagnosis’. As a result, it also includes all attributes of ‘Diagnosis’ (represented by the rows where the column “concept or concept compositions or inherited” contains the value ‘inherited’). This follows the inheritance rules applied in SPHN where a ‘child’ concept always inherits all attributes from its ‘parent’ concept.
Table 1 Overview of columns defined in the ‘Concepts’ tab from the SPHN Dataset and their corresponding RDF interpretation by the SPHN Schema ForgeFig. 1
Illustration of the transformation of the 'Billed Diagnosis' concept into its RDF representation. Section A depicts the 'Billed Diagnosis' concept as defined in the SPHN Dataset, while Section B presents its corresponding RDF Turtle representation. Numerical labels in Section A correspond to those in Section B, indicating how specific elements from Section A are interpreted and transformed into their RDF representation
The type of the ‘Billed Diagnosis’ is captured by the attribute ‘code’ where the coding system used should be ICD-10-GM, the time of diagnosis is captured by the attribute ‘record datetime’, the code that specifies the rank of the billed diagnosis is captured by the attribute ‘rank code’ where the code should be from a fixed set of values from SNOMED CT, and the age of the patient at the time of diagnosis is captured by the attribute ‘age’, which refers to another concept called ‘Age’.
The ‘cardinality of composedOf’ column specifies which attributes are required and, in this case, the ‘record datetime’ is the only mandatory one (i.e. with a cardinality of 1:1).
The ‘value set or subset’ column aims to further refine the valid codes by defining specific subsets of codes allowed for use in a given context. Different scenarios are supported for specifying value sets. When only the ‘standard’ column is filled with the name of a terminology, all codes from that terminology are considered valid. A subset of a terminology can be defined using the keyword ‘descendant of’ followed by a code which indicates that all its child codes are valid. If ‘descendant of’ is not specified, only the explicitly enumerated codes are permitted and their child codes are not considered as valid options. Finally, concepts can hold a ‘meaning binding’ to specific codes from given terminologies to reflect that their meaning aligns with the associated code.
All the rules and conventions are thoroughly described in the SPHN Documentation for the SPHN DCC and projects to consult when building their Dataset [35]. Once the Dataset holds the necessary semantics, it can be parsed by the SPHN Schema Forge to build all the necessary semantic artifacts.
MethodologyThe development of the SPHN Schema Forge follows an iterative and user-centric approach inspired by Agile principles, with a strong emphasis on improving user satisfaction. The approach focused on addressing immediate challenges as they emerged and gradually integrating the solutions into the broader SPHN framework.
The SPHN initiative adopted RDF as a standard for data exchange in its three pillars strategy [2]. While powerful RDF tools were available and effective for technical experts, early feedback from stakeholders highlighted the need for more user-friendly solutions and support beyond the RDF schema alone.
Four main needs raised by the stakeholders included:
1.A simplified modeling process of project-specific concepts and attributes as an extension of the SPHN RDF Schema
2.Defined validation constraints to indicate data modelling errors
3.A set of basic and ready-to-use statistical queries for exploring SPHN and project-extended RDF datasets
4.A user-friendly visualization of both, the SPHN and project-extended RDF schema
These requests were received over an extended period, leading to the development of individual standalone solutions. Later in the process, the solutions for statistical queries and user-friendly visualization were merged following a major redesign, as both relied on the same internal model derived from the RDF schema. For each solution, alternatives have been considered, and research of available tools and frameworks was conducted.
Even with the tools available, generating new releases of the SPHN RDF Schema or project extensions remained cumbersome, as all three tools required to be installed and updated individually. To answer the user’s feedback calling for a more streamlined process, the tools were wrapped together into a simple web service resulting in the SPHN Schema Forge.
The SPHN Schema Forge is built upon a set of guiding principles (and assumptions) that ensure effective implementation and usage. These principles provide a baseline for structuring and transforming semantics in a standardized and interoperable manner.
Structured representation: SPHN Schema Forge relies on a well-structured .xlsx file as a starting point, i.e. the SPHN Dataset. This serves as the source of truth for describing all the necessary concepts, attributes and their semantics. It must adhere to a predefined structure to ensure consistency and usability.
Transformation into RDF schema: The semantics defined in the Dataset are systematically parsed and represented as an RDF schema using W3C standards (e.g. RDFS, SKOS [36] and OWL), enabling machine-readable representation of the semantics while preserving the intended meaning of concepts and attributes from the Dataset.
Derivation of SHACL shapes from RDF schema: The RDF schema must capture all the semantics (and hints) required to derive SHACL shapes, via the SPHN SHACLer.
Derivation of Documentation from RDF schema: The RDF schema should also contain all the necessary semantics (and hints) to derive a self-describing HTML documentation, via the SPHN Schema Doc.
Extensibility: SPHN Schema Forge should facilitate extensibility where SPHN-defined concepts can be extended by users with specific use cases.
One thing to note is that the conversion from the Dataset to the RDF schema is a one-way process as shown in Fig. 2. It is not possible to fully reconstruct the original Dataset from the RDF representation because certain information may be consolidated or abstracted during the transformation. This irreversible transformation highlights the need for careful management and preservation of the original Dataset for reference and updates.
Fig. 2
The SPHN Schema Forge pipeline. SPHN Schema Forge integrates the SPHN Dataset2RDF, SPHN SHACLer and the SPHN Schema Doc. This pipeline transforms from an SPHN-compliant Dataset file into multiple outputs by running several tools, including the SPHN Dataset2RDF, SPHN SHACLer and the SPHN Schema Doc. The outputs consist of 1) a RDF Schema used in data pipelines (e.g. Clinical Data Platform), for generating SPHN-compliant data; 2) SHACL validation rules (in RDF Turtle format) to ensure data quality; 3) SPARQL queries for facilitating the query of data for basic statistical insights and; 4) an HTML documentation based on pyLODE, which can be made accessible online to facilitate the onboarding of users to SPHN, as well as projects, and its schema specifications
ImplementationThe SPHN Schema Forge is a freely available web service accessible at [37]. Its source code, deployed via a CI/CD pipeline, is available on GitLab [38] and is provided under the GNU General Public License v3.0 (GPLv3) open-source license. To use the service, users need to provide an .xslx file that complies with the SPHN requirements and click ‘Run’. Upon successful completion, a set of outputs is generated, consisting of an RDF schema file (in RDF Turtle format), a SHACL file (in RDF Turtle format), a set of SPARQL queries (one query per file) and an HTML file.
The SPHN Schema Forge integrates three main tools for generating the various outputs: SPHN Dataset2RDF, SPHN SHACLer, and SPHN Schema Doc (see Fig. 2). The SPHN Dataset2RDF processes the tabular Dataset, while the SPHN SHACLer and SPHN Schema Doc parses the RDF schema generated by the Dataset2RDF. Each tool described below is licensed under GPLv3 license.
SPHN Dataset2RDFThe SPHN Dataset2RDF is the core tool designed to transform an SPHN or project-specific Dataset (in.xlsx format) into its corresponding RDF schema representation. This conversion process follows the SPHN implementation guidelines and standards, ensuring that the resultant RDF schemas are aligned with the semantic interoperability requirements. Based on Python, the SPHN Dataset2RDF makes use of RDFLib [39] for the generation of a valid RDF schema using predicates from RDF, OWL and SKOS for the representation of semantics.
The transformation is achieved as follows: Dataset2RDF parses information provided in each row in the ‘Concepts’ tab and translates the different columns following specific rules to generate an RDF representation. Illustrated with the ‘Billed Diagnosis’ example in Fig. 1, a concept is represented as an owl:Class, with its label defined by rdfs:label and its definition by skos:definition. The cardinalities and restrictions to specific values from either a coding system or a specific set of qualitative values are all represented as owl:Restriction. The list of all columns in the ‘Concepts’ tab parsed by the Dataset2RDF is provided in Table 1.
Projects can use the SPHN Dataset and extend it further with additional concepts (and attributes) according to their use case. To facilitate this approach, we provide the SPHN Dataset Template [40]—a template version of the SPHN Dataset—that can be used as a starting point for projects to define their own concepts. Dataset2RDF supports the parsing of project-specific Dataset but there are some rules and conventions which users must follow to ensure that their semantics are properly defined and thus translated into RDF. For example, a project must indicate their own concepts and attributes by using a project-specific prefix. For the benefit of our users, the full list of conventions is described in the SPHN Documentation [35]. In addition to conventions, there are also a set of well-defined and documented modeling scenarios that are supported by Dataset2RDF. The scenarios serve to highlight the different modeling capabilities based on the expressivity supported by Dataset2RDF. For example, one of the most common modeling scenarios would be the need for a project to extend an existing concept by adding new attributes or modifying the semantics of an existing attribute.
Given the complexity of the content of the SPHN Dataset and the resulting parsing for generating a consistent RDF schema, many checks are implemented to verify that the input file is built correctly. Otherwise, comprehensive errors are provided to the user to resolve the issue originating from their Dataset (see Additional File 1). From a codebase perspective, there are a suite of unit and integration tests that check different modeling scenarios to ensure that the transformations are consistently applied and there are no regressions. The SPHN Dataset2RDF is accessible on GitLab [41].
SPHN SHACLerTo facilitate data validation, the SPHN DCC has developed a way to automatically build quality checks based on SHACL which is a language developed for validating RDF graphs. The SPHN SHACLer, made available on GitLab [42], is a Python script that automatically generates such SHACL shapes from a given RDF schema. It can be seen as an interpreter of the RDF schema within a restricted setting: while ontologies typically adhere to an open world assumption, the SHACLer operates under a closed world assumption. This is especially true for patient data, where each patient entry is considered complete when undergoing validation with the SHACL shapes. The validation is using the entailment of RDFS, which automatically traverses downward hierarchical relations, ensuring that class inheritance is covered.
Several types of SHACL constraints, listed in Table 2, covering different aspects of the data, have been implemented in SPHN. For instance, the cardinality restrictions set in the RDF schema (with owl:minCardinality and owl:maxCardinality) are checked via the constraints sh:minCount and sh:maxCount, respectively.
Table 2 Comprehensive list of constraints used in the SHACLerGenerally, the translation of SPHN RDF Schema to a corresponding SHACL shapes is achieved as follows:
1.Extraction of the root classes and schema(s) prefixes
2.Merging the graphs of the SPHN RDF Schema and a possible project-specific RDF schema
3.Producing the metadata for the SHACL file (e.g. creation date, conformance, license, entailment)
4.Loading the object properties and the restrictions for all classes and expanding them through their sub/super class relationships
5.For classes below the root nodes and not having instances in the RDF Schema, creating a sh:NodeShape with:
a.sh:targetClass to the class from the RDF Schema (explicitly only direct instances of the class)
b.sh:closed which is set to false for SPHN only validation and true when validating against both the SPHN and project-specific schema
c.sh:ignoredProperties which includes at least rdf:type, as it is not explicitly listed in the properties section
d.For each property that originates at this class (either through rdfs:domain or as an explicit restriction on the combination of the class and property):
i.Creating a nested property restriction for this focus class
ii.Collecting possible minimum and maximum cardinality restrictions on the source/property/target combination and adding them to the nested project restriction.
iii.Collecting possible target classes or instances from the SPHN RDF Schema. Hierarchical dependencies do not need to be expanded, as the SHACL validation is specified to be executed using RDFS entailment rules. For example, referring to the SNOMED CT root node http://snomed.info/id/138875005 is sufficient to include all classes from SNOMED CT.
iv.When certain additional hints are given in the schema, such as subclasses are not allowed for certain codes, additional SPARQL constraints are written.
e.For each property chain that originated at this class, creating a nested property chain restriction, as for the normal properties but with incorporating property chains.
6.Each class having instances defined in the schema are value set classes. These value set classes only have instances in the RDF Schema and no further properties originating at this class. For such class a Shape is created, and a reverse instance listing ensures that no value set members are created that are not listed in the schema.
When a data element is not compliant with the schema definitions, the validation with these SHACL shapes would result in an error (sh:Error). Figure 3 provides a correspondence between the RDF schema shown in Fig. 1B and the associated SHACL constraints created:
A NodeShape is created for each class from the SPHN RDF Schema [5].
(A) defines the shape being open allowing additional properties to be present. Since the rdf:type is by default used as predicate, it is explicitly listed in the ignored properties. The reason is that the shape will be defined as being closed when project specific extensions are attached.
(5) enforces the cardinality restriction of sphn:hasCode to be exactly one. In addition, the class is constrained to ICD-10-GM by specifying the ICD-10-GM root node, meaning only instances of this class are valid. Downstream classes don’t need to be included as due to the RDFS entailment.
(6) specifies the optional sphn:hasRecordDateTime with a dateTime datatype.
(7) is the direct interpretation of the corresponding part in the SPHN RDF Schema.
The skos:scopeNote specified at the bottom of the RDF Schema in Fig. 1B, which prevents subclasses of specified codes from being valid, is also parsed by the SHACLer and translated as shown in (B).
(8) shows a concrete example where sphn:hasSubjectAge must lead to another SPHN class sphn:Age. Here, it is not further checked whether the instance also obeys to the semantics specified for the sphn:Age as there will be a NodeShape for this class.
Fig. 3
Excerpt of a SHACL shape generated for the 'Billed Diagnosis' concept based on the content of the SPHN RDF Schema. The numbers assigned to specific SHACL shapes in this figure correspond to those previously highlighted in the RDF schema in Fig. 1B
Additionally, validations are created for certain special properties and under certain conditions. One rule ensures that a hasStartDateTime occurs before or is at least equal to a hasEndDateTime; otherwise, an error is reported. Warnings (sh:Warning) are issued when an instance of a class does not follow the IRI naming convention; or when codes from external terminologies that have undergone a meaning change and are provided in a version where the exact meaning cannot be derived. Finally, codes from external terminologies that have undergone a meaning change and are provided in a version where the exact meaning can be derived, validation rules are generated with a sh:Info severity. This applies for both codes that are still valid in the current release, and codes that are not valid anymore in the current release. We are constantly evaluating whether additional constraints can be derived from the RDF schema to enhance the quality of the data without impeding the raw source of information.
SPHN Schema DocThe SPHN Schema Doc can generate 1) an HTML documentation of the RDF schema for a human readable version of the schema and 2) some statistical SPARQL queries for getting basic information about data conforming to the schema. It is based on pyLODE, a Python-based tool for generating HTML documentation of RDF and OWL ontologies and schemas [43]. The SPHN Schema Doc is accessible on GitLab [44].
Regarding the HTML generation, features have been added to the SPHN Schema Doc to tailor the visual representation to the needs of the SPHN community (e.g. alphabetical ordering of classes and properties, search function panel, table representation of value set restrictions for each class). Additionally, the tool can process images that depict the designed concepts along with direct connections. It integrates the image’s relative paths in the produced HTML at the correct place, so they are rendered correctly in the resulting documentation. These pre-prepared images can be given separately in the SPHN Schema Forge if one would like to render a visualization of their concepts. The HTML for the SPHN RDF Schema is published online at [45].
Regarding the generated SPARQLs, they enable users to retrieve relevant statistics by pasting them in any triple store containing the data (e.g. GraphDB [46], Virtuoso [47], Jena Fuseki [48]). These queries were developed in response to researchers’ requests to gain preliminary insights into their data before refining them into more project- and research-specific oriented queries. Technically, the SPHN Schema Doc uses RDFLib to load the RDF schema into a graph and create dictionaries for each Concept, Datatype, and Object Property, including their restrictions. It applies a depth-first search algorithm to traverse the graph from each concept until reaching either a
Comments (0)