Traditional spatial smoothing model
Using the design-based approach, district-level prevalence estimates of overweight can be obtained directly from the available samples in each district. However, in districts not included in NHMS 2015, no estimates can be obtained. In addition, estimates with large variances are inevitable in districts with sparse data. Therefore, we employed a fully Bayesian hierarchical modelling framework that allows spatial smoothing to obtain prevalence estimates in unsampled districts and to produce more reliable estimates with smaller variances.
We can assume a Bernoulli model for the binary response variable of overweight (\(}}_}}}=1\) if overweight versus \(}}_}}}=0\) if non-overweight) for an individual child \(}\) (\(}\) = 1, …, 6301) in administrative district \(}\) (\(}\) = 1, …, 144) as follows:
$$}}_}}\boldsymbol}\sim \boldsymbol}}}}}}}}}(}}_}}})$$
(1)
$$\mathbf\mathbf\mathbf\mathbf\mathbf(}}_}}})=\boldsymbol+_}}}}_}}}}_}}}+}}_}}+}}_}}$$
(2)
In this model, \(}}_}}}\) is the probability of the \(}\) th child in the \(}\) th district being overweight. The logit link function was applied to link the probability with the potential district-level covariates \(}}_}}\) with associated parameters \(}.\) The intercept \(\boldsymbol\) represents the overall risk of being overweight.
This model-based approach allows for incorporation of random effects to account for the spatial correlation between districts, while the unstructured random effects allow each district to vary independently of its adjoining neighbours. We applied the Besag, York, and Mollié model, which partitions the random effects at the district level into unstructured (\(}}_}}\)) and spatially structured (\(}}_}}\)) effects [7]. We incorporated the ICAR prior in the spatially structured random effects, which has the following conditional distribution:
$$}}_}}|}}_}\right)}\sim }\left(\frac_}}^}}}}}_}}}^}}}}}_}}^}}}}_}}^}}}}}_}}}^}}}},\frac}_}}^}}}}}_}}}^}}}}\right),$$
(3)
where \(}\) denotes the normal distribution, and \(}}_}}\mathbf}}\) is a neighbourhood weight. We denote this as \(}}_}}\sim }}}(},})\), with \(}=}}_}}\mathbf}})\). This ICAR prior allows us to borrow information between neighbouring areas, yielding a smoothed prevalence map. A scaled version of \(}\) is recommended such that \(}\) can be interpreted as the marginal precision [19].
Accounting for the study design
In order to reduce bias due to non-random sampling and non-response, sampling weight was accounted for in all analyses. First, we computed the design-based Horvitz-Thompson estimator [20], \(}}}_}}\), which is the district-specific prevalence of overweight, using the observations in each district:
$$}}}_}\boldsymbol}=\frac}}}}_}}\boldsymbol}}}_}}\boldsymbol}}}}_}}}}$$
(4)
where \(}}_}}}\) is the sampling weight of individual child \(}\) in district \(}\). This estimator takes into account the design of the study. We then obtain an area-level summary by applying the empirical logistic transformation of \(}}}_}}\), as described by Mercer et al. [5] in a study comparing different weighting methods when using spatial smoothing in small-area estimations (i.e. \(}}_}}}^}=}}}\left[\frac}}}_}}}}}}_}}}\right]\)) [5]. We then model this summary data as:
$$}_}}^ |\user2_}} \user2\sim \user2\left( \left[ }_}} }}}_}} }}} \right],\frac}(\left( }_}} } \right)}}}_^ \left( }_}} } \right)^ }}} \right)$$
(5)
where \(}}}(}}}_}})\) is the variance of the Horvitz-Thompson estimator \(}}}_}}\) and \(}}_}}\) from the previous section, which takes into account the study design in both the estimator and its variance.
Bayesian inference
We performed the Bayesian analysis using an integrated nested Laplace approximation (INLA) program in R software [21]. The deterministic algorithm approach for Bayesian inference in INLA has been proven to reduce the computing time and provides accurate results [22, 23]. In Bayesian inference, prior distributions for parameters to be estimated were specified before modelling was commenced. In R-INLA, the default Gaussian prior with mean and precision equal to 0 was specified for the intercept of the model, α. For the fixed effects, Gaussian priors with mean equal to 0 and precision equal to 0.001 were assigned.
We specified the unstructured random effect as a normal distribution with a standardized mean of zero. A gamma distribution (0.5, 0.005) was specified for the hyperpriors for the precision of random effects. We report the covariate effects using the mean and 95% credible intervals, which represent the range of values that contains the true value with a probability of 95%.
To evaluate the model fit, the deviance information criterion (DIC) and Watanabe information criterion (WAIC) were used [24, 25]. Lower DIC or WAIC values signify better model fit. Once the best-fit model was identified, it was used to produce prevalence estimates for each district. District-level covariates were then introduced to the model individually. The model was built using a forward stepwise regression approach, and its performance was again assessed using the DIC and WAIC values.
Proposed spatial models for disconnected regions
The Bayesian hierarchical spatial model uses neighbourhood weights that are traditionally defined as \(}}_}}\mathbf}}=1\) when areas \(}\) and \(}\mathbf}\) share a boundary and as \(}}_}}\mathbf}}=0\) otherwise [26]. This definition defines a graph as a compilation of nodes and edges representing the respective districts and the set of neighbours for each district. Most often in disease mapping, we assume that the graph is a connected graph, meaning that all the nodes connect to at least one other node. However, disconnected graphs can arise when there is an island with no neighbour or when the study region is split, resulting in separate subgraphs [8].
Analysis involving disconnected subgraphs is not as straightforward as the analysis for a connected graph and is very rarely discussed. Hodges et al. [27] discuss the theory of setting disconnected subgraphs [27], while Freni-Sterrantino et al. [8] give some recommendations in INLA [8]. We give an overview of techniques available in INLA for producing district-level prevalence estimates for disconnected regions. The focus is on the setting of disconnected regions that consist of multiple areas \(}\) (thus, there are no singletons).
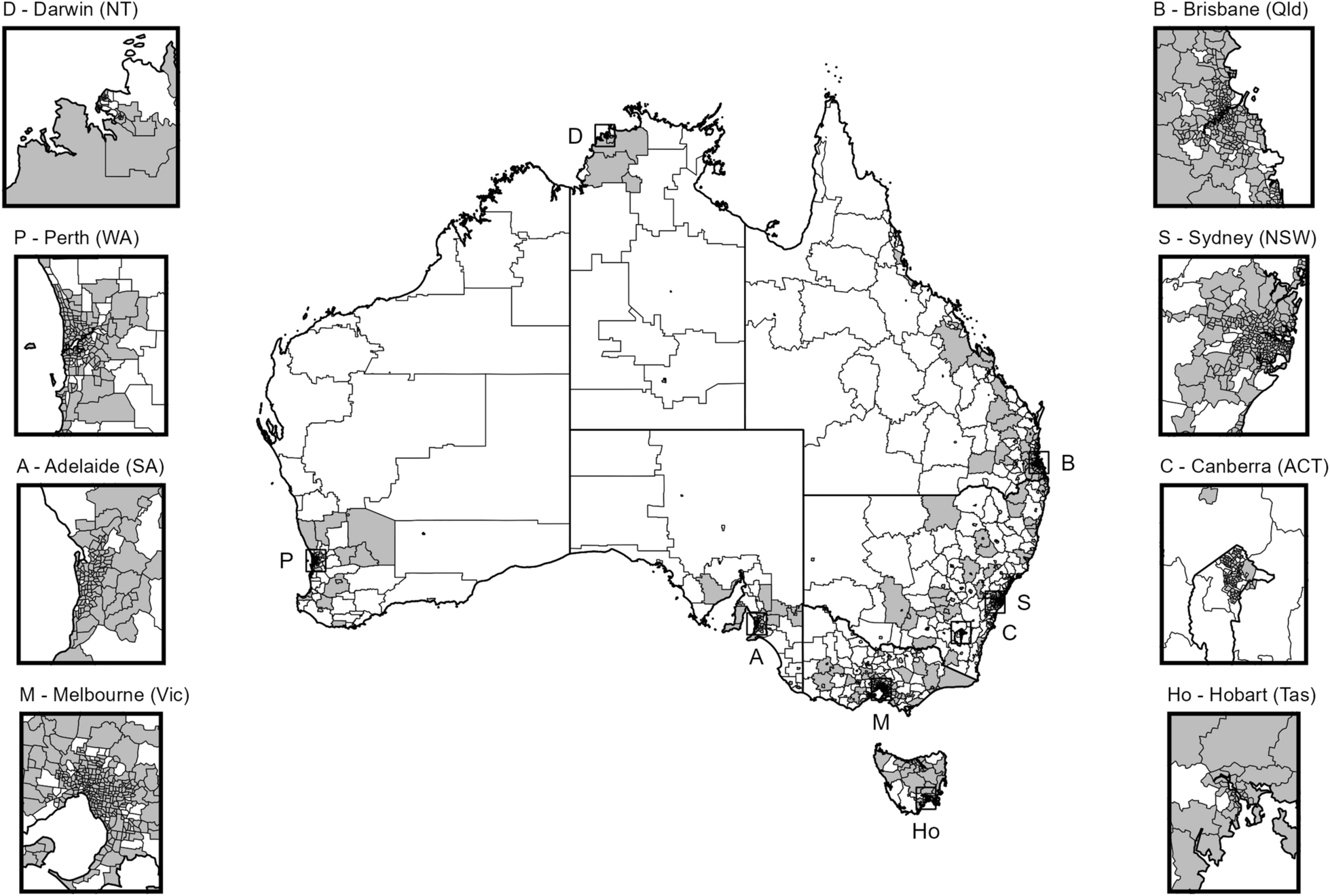
We assume that the total study region with areas \(}\) (e.g., districts) is split up into disconnected regions \(}\). In the application presented in this paper, the South China Sea separates the region of Malaysia into two disconnected regions (Peninsular Malaysia and Borneo).
Model I: single sum-to-zero constraint
The ICAR distribution has an improper distribution, and the standard method to deal with this is by adding a sum-to-zero constraint—i.e., the sum of all random effects is equal to zero. This is the standard method used in disease mapping with a connected graph. In the case of disconnected regions, this assumption can still be made. Using this assumption, the overall mean of the random effects across the whole study area is zero. The spatial random effects for area \(}\) in region \(}\), \(}}_}(})}\), can be interpreted as the area-specific deviation from the overall risk.
$$}}}}}(}}_}}(})})=\boldsymbol+}}_}\boldsymbol}+\boldsymbol}}_}(})}$$
(6)
$$}}_}(})\boldsymbol}\sim }}}(},})$$
(7)
$$_}}_}\in }}}}_}(})}=0.$$
(8)
By setting the option adjust.for.con.comp = FALSE, INLA interprets this as a sum-to-zero constraint for the union of the subgraphs. This is specified in INLA as:
formula = y ~ 1 + f(struct, model='besag', graph=W.graph, adjust.for.con.comp = FALSE, scale.model = TRUE) + f(unstruct, model ='iid')
In this formulation, “struct” and “unstruct” correspond to a vector (1, …, N) with a number of areas N, and “W.graph” is the neighbourhood structure. The specification scale.model = TRUE defines a scaled version of the random effects such that the variance parameter can be interpreted as a marginal variance.
Model II: sum-to-zero constraints for each region
When specifying the graph for the ICAR prior in INLA, INLA interprets this as a sum-to-zero constraint for each subgraph by default, imposing a separate sum-to-zero constraint of the random effects for each region \(}\).
$$}}}}}(}}_}}(})})=\boldsymbol+}}_}\boldsymbol}+\boldsymbol}}_}(})}$$
(9)
$$}}_}(})\boldsymbol}\sim }}}(},})$$
(10)
$$\forall }:\boldsymbol_}\in }}}}_}(})}=0$$
(11)
This model assumes a common intercept for all disconnected regions, so the overall risk in the separate regions is the same. The spatial random effects \(}}_}(})}\) in this case need to be interpreted as the area-specific deviation from the overall risk, which varies around zero in each disconnected region.
This default setting is equivalent to setting the option adjust.for.con.comp = TRUE in INLA, such that a separate sum-to-zero constraint of the random effects is applied for each region.
formula = y ~ 1 + f(struct, model = 'besag', graph = W.graph, adjust.for.con.comp = TRUE, scale.model = TRUE) + f(unstruct, model ='iid')
In this case, scaling is done with respect to each subgraph.
Model III: sum-to-zero constraint and intercept for each region
A more flexible model assigns one intercept to each region in addition to using a sum-to-zero constraint for each connected region. By adding an intercept for each region, we infer that the baseline prevalence is different in the disconnected regions.
$$}}}}}(}}_}}(})})=}_}}+}}_}\boldsymbol}+\boldsymbol}}_}(})}$$
(12)
$$}}_}(})\boldsymbol}\sim }}}(},})$$
(13)
$$\forall }:\boldsymbol_}\in }}}}_}(})}=0$$
(14)
The spatial random effects \(}}_}(})}\) can be interpreted as the area-specific deviation from the region-specific risk in this case. The intercepts for the disconnected regions need to be explicitly specified in INLA:
formula = y ~ -1 + region + f(struct, model='besag', graph=W.graph, adjust.for.con.comp = TRUE, scale.model = TRUE) + f(unstruct, model ='iid')
Model IV: split random effects model
Models 1–3 assume one random effects distribution for all areas in the region, with the random effects variance corresponding to the variation of the random effects over all areas in all the disconnected regions. As the disconnected regions can be quite different in terms of demographics, socioeconomics, infrastructure, and development, we can also assume that the variation in these regions is different. A separate analysis could be conducted for the two regions, but this would be restrictive in the model comparison (e.g., the use of DIC or WAIC for model comparison would not be possible in this case). Therefore, a split random effect is proposed so that use of DIC and WAIC are still possible to assess the model fit.
$$}}}}}\left(}}_}}\left(}\right)}\right)=}_}}+}}_}\boldsymbol}+\boldsymbol}}_}\left(}\right)}$$
(15)
$$}: }}_}(})\boldsymbol}\sim }}}\left(}}_}},}}_}}\right)$$
(16)
$$\forall }:\boldsymbol_}\in }}}}_}(})}=0$$
(17)
This model assumes separate ICAR random effects for the disconnected regions, so each subgraph has its own spatial variance. These random effects are defined in the subgraph \(}}_}}\) for a sub-region \(}\) and have a separate spatial precision. This can be specified in INLA as follows:
formula = y ~ -1 + region + f(struct1, model = 'besag', graph = W.graph1, scale.model = TRUE) + f(unstruct1, model = 'iid') + f(struct2, model = 'besag', graph = W.graph2, scale.model = TRUE) + f(unstruct2, model = 'iid')
In this specification, “struct1” and “unstruct1” correspond to a vector (11, …, N1), where N1 is the number of areas in region 1, and “W.graph1” is the neighbourhood structure amongst these areas. “struct2”, “unstruct2”, and “W.graph2” correspond to similar properties for region 2.






留言 (0)