
Remember me

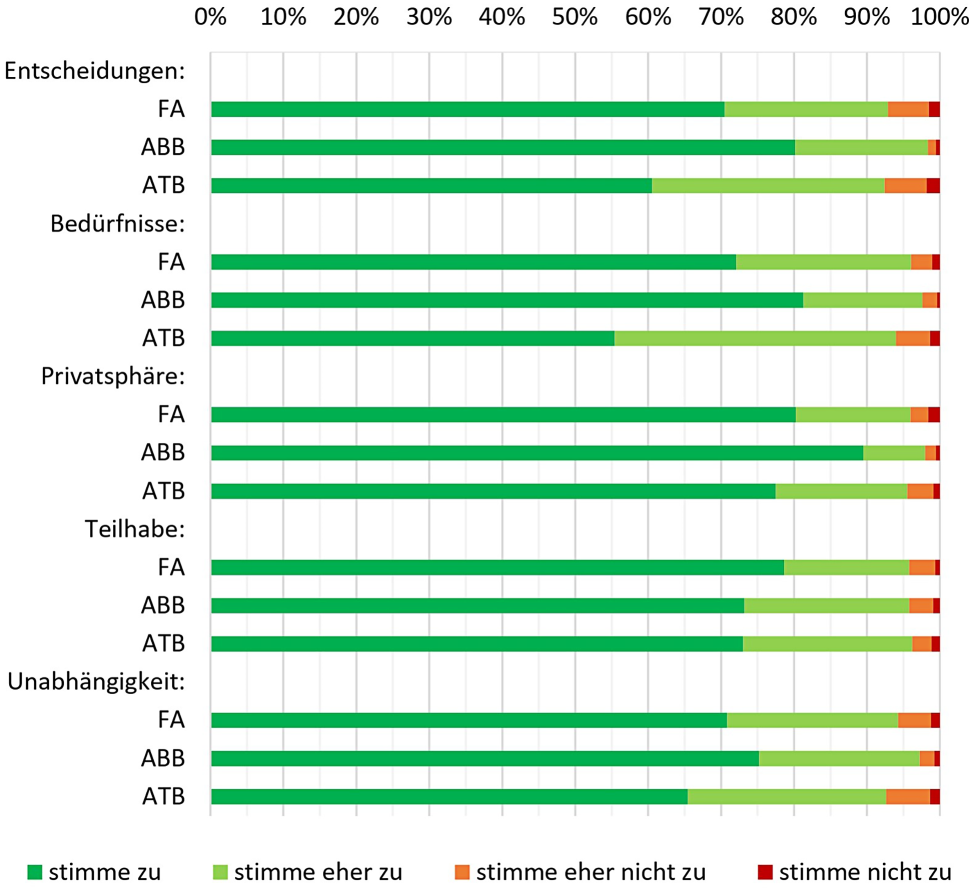
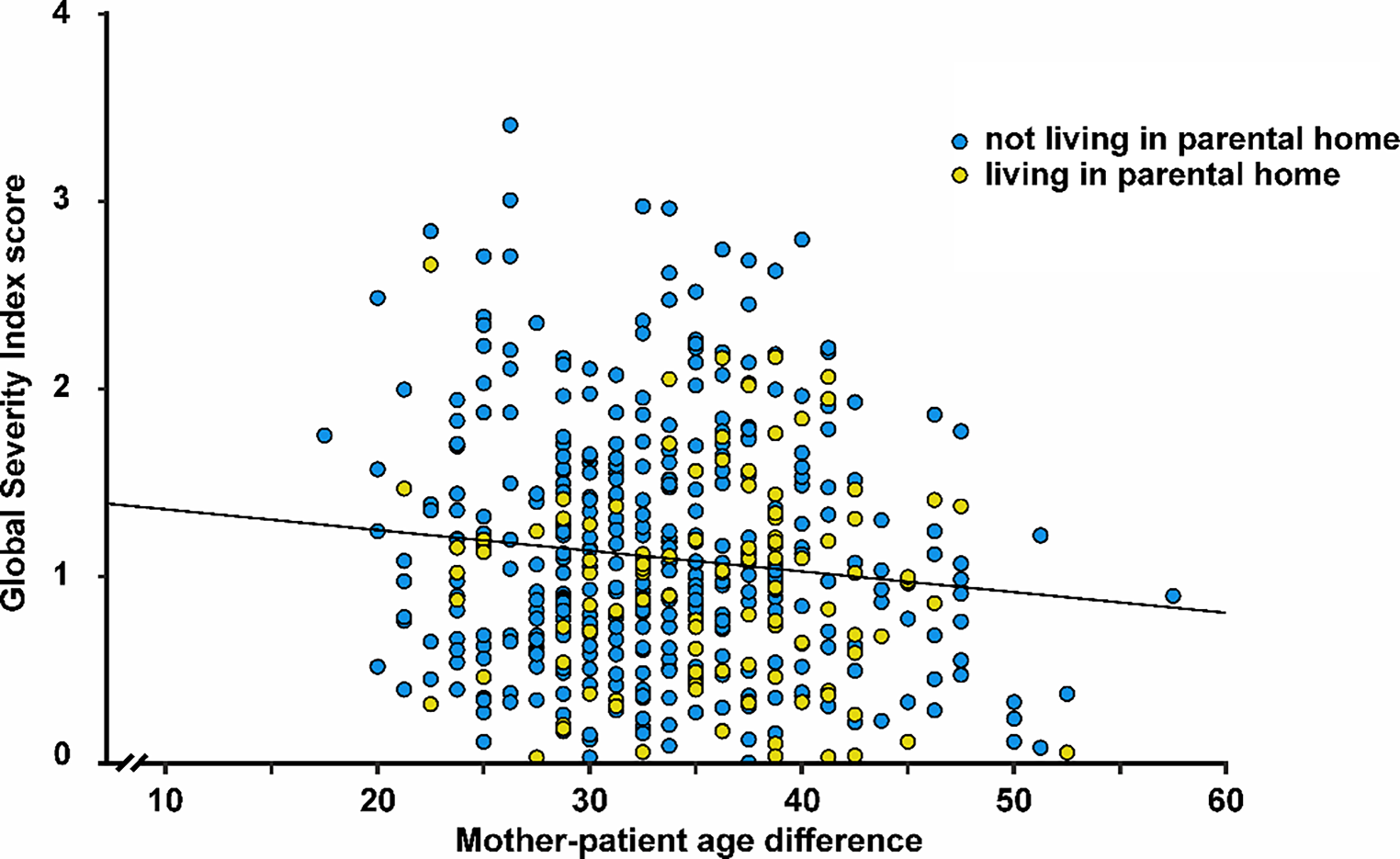


In total, 270 children were examined at the counselling hour, and 37 different L1s were assessed (Fig. 2). The most frequent L1s were (in order of descending frequency): Turkish, Bosnian/Croatian/Serbian, Arabic, Russian, and Romanian. A total of 168 children had one of these five languages as their L1. The most infrequently represented 15 languages were each spoken by only one child. 74% of the children used only one language in addition to their L2 German, 26% multilingual.
Fig. 2
Frequency (in number of children) of different first language (L1) of the children examined at the counselling hour; orange frequency of female children, turquoise frequency of male children. BCS Bosnian/Croatian/Serbian
The gender gap (70% male vs. 30% female children) does not differ between the five most frequent languages (χ2(5) = 7.19, p = 0.207).
The age of the children at their first visit ranged from 1;6 to 19;0 years. An analysis of the three age groups mentioned above showed that 16% of all children were examined at an age younger than 3;6, 61% of children were examined between 3;6 and 7;6, and 23% of children were examined after the age of 7;6.
An analysis of the onset of speech production shows that 46% of all children produced first words at around 12 months of age, 33% of the children started to produce words within their second year of life, and 21% of the children produced their first words after their second birthday.
Having provided some general information about the children examined at the counselling hour, the next section is concerned with the question of LD. Figure 3 shows how many children received the result TD, ICD-10:F80, and CLD, respectively.
Fig. 3
Frequency (in percent) of linguistic evaluation results of the whole group of children examined at the counselling hour; green typically developed (TD), blue language disorder in the framework of ICD-10 : F80 (ICD10_F80), red comorbid language disorder (CLD)
When the composition of these three groups of children is analyzed with respect to the variable L1 (restricting the analysis to the five most frequent L1s listed above), no significant difference in the linguistic evaluation depending on L1 was found (χ2(10) = 6.09, p = 0.808).
Children with primary diseaseChildren with a previously determined primary disease represented 53% of all children. Of these children 90% were linguistically evaluated with a CLD, and 10% received the result TD. Table 5 shows these results split by the different categories of primary diseases. In all groups, the number of children with CLD was higher than the number of children with TD. The highest number of children with CLD was found for ASD (100%), and for intellectual disability (97%). The lowest number of children with CLD (61%) was found for somatic diseases.
Table 5 Categorization of children with primary disease according to the group of disease. The absolute number of children within the respective groups, as well as the percentage of children with CLD and TD for each group is givenChildren without primary diseaseChildren without primary disease represented 47% of all children. Of these children, 62% were eventually evaluated as TD and 38% received the result ICD-10:F80. These frequencies of linguistic results differed significantly from the frequencies in children with a primary disease (χ2(2) = 217.5, p < 0.0001).
For 63% of the children without primary disease, no heredity for ICD-10:F80 was indicated, whereas for 28%, a heredity was known. In the remaining 9% of the families, heredity could not be determined.
Parameters influencing the linguistic result of children without primary diseaseIn this section, we test whether and to what extent the sociodemographic parameters L1, number of languages regularly used, gender, heredity, age at first examination (in months), and age at first word production (in months) predict the result of the linguistic evaluation (TD, ICD-10:F80) in children without primary disease. To this aim, logistic regression models with the dependent variable linguistic result were calculated using the function generalized linear models (glm).
In order to analyze the influence of different L1s on the dependent variable linguistic result, a model was built on a reduced dataset which only included the four most commonly used L1s in the present study (Turkish, Bosnian/Croatian/Serbian, Arabic, Russian). This decision was made because all other L1s were each spoken by fewer than 5 children without primary disease. The effect of L1 was evaluated by building a model with L1 and all other parameters as independent variables and comparing the fit of this model to one without the factor L1. Goodness of fit was evaluated using the Akaike information criterion (AIC), which is an estimate of model quality and combines the goodness of the model fit and model complexity to prevent overfitting. Results showed that the L1 did not contribute to predicting the linguistic result (model including L1: AIC = 91.87 vs. model without L1: AIC = 87.62).
Next, the influence of the remaining parameters on linguistic result was analyzed. Since L1 appeared not to predict the outcome, a new model was built on the complete dataset including all L1s and excluding the factor L1. In order to test the contribution of each independent variable on the predictive power of the model, the R function drop1 was used. This function eliminates variables one-by-one and compares the models’ fit using the AIC. Removing the variable number of languages regularly used resulted in a better AIC (model including factor: AIC = 132.05, model without factor: AIC = 130.09). Removing additional variables did not result in further improvements according to the AIC selection criterion. Results of the best fitting model are shown in Table 6. The predictor variables with significant coefficients were heredity, age at first examination, and age at first word production. Children without heredity had 3.5 times higher odds of receiving the result TD than children with a known heredity, all other factors being equal. The older the children were at their first examination, the more likely they were to receive the linguistic result TD. With each one month increase in age, the odds of receiving the result TD increased by 1.0186. For the variable age at first word production, in contrast, increasing age was related to lower chances for TD. Here, with each one month increase in age, the odds for the result TD decreased by 0.917.
Table 6 Results returned by the bivariate logistic regression model that best fit the linguistic results obtained by the multilingual children without primary disease examined at the counselling hour. Linguistic result is the dependent variable (TD vs ICD-10:F80), and gender (female vs. male), heredity (yes, no, unknown), age at first examination (continuous variable, in months), and age at first word production (continuous variable, in months) are independent variables
Comments (0)