Comparing the assessment results of the two ontologies, GO and EFO, with the list-type dictionary, ICD-11, ontology-based vocabularies follow stricter semantics and therefore fared better in the scoring of FAIR features. One of the reasons is that many ontology-related standards have been established, including formats, such as the Web Ontology Language (OWL), guidelines such as the OBO principles, minimum information standards, such as Minimum Information for Biological and Biomedical Investigations (MIBBI) [35], and mechanisms for cross-references or incorporating external ontologies, such as the Minimum Information to Reference an External Ontology Term (MIREOT) [25]. This is naturally reflected in a higher score for compliance with community standards, which is a core part of FVF, and which improves the interoperability and reusability of a vocabulary. However, being a FAIR ontology does not ensure the quality and usability of an ontology. The scope, popularity, and accuracy of a vocabulary are also factors to consider.
The FVFs we proposed integrate multiple FAIR vocabulary requirements and serve as FAIR vocabulary standards to guide the development and maintenance of vocabularies. Each FVF is associated with indicators, to support its quantifiable and objective assessment against each feature. These indicators can also be plugged into existing or emerging standards in other domains to support the evolving of new vocabularies and suit emerging use cases. For example, in FVF-8: cross-referencing other vocabularies can be linked to the ontology cross-reference standards, such as MIREOT. Because of our expertise and requirements, this manuscript focuses on the biomedical domain; however, we anticipate this framework could be reused elsewhere.
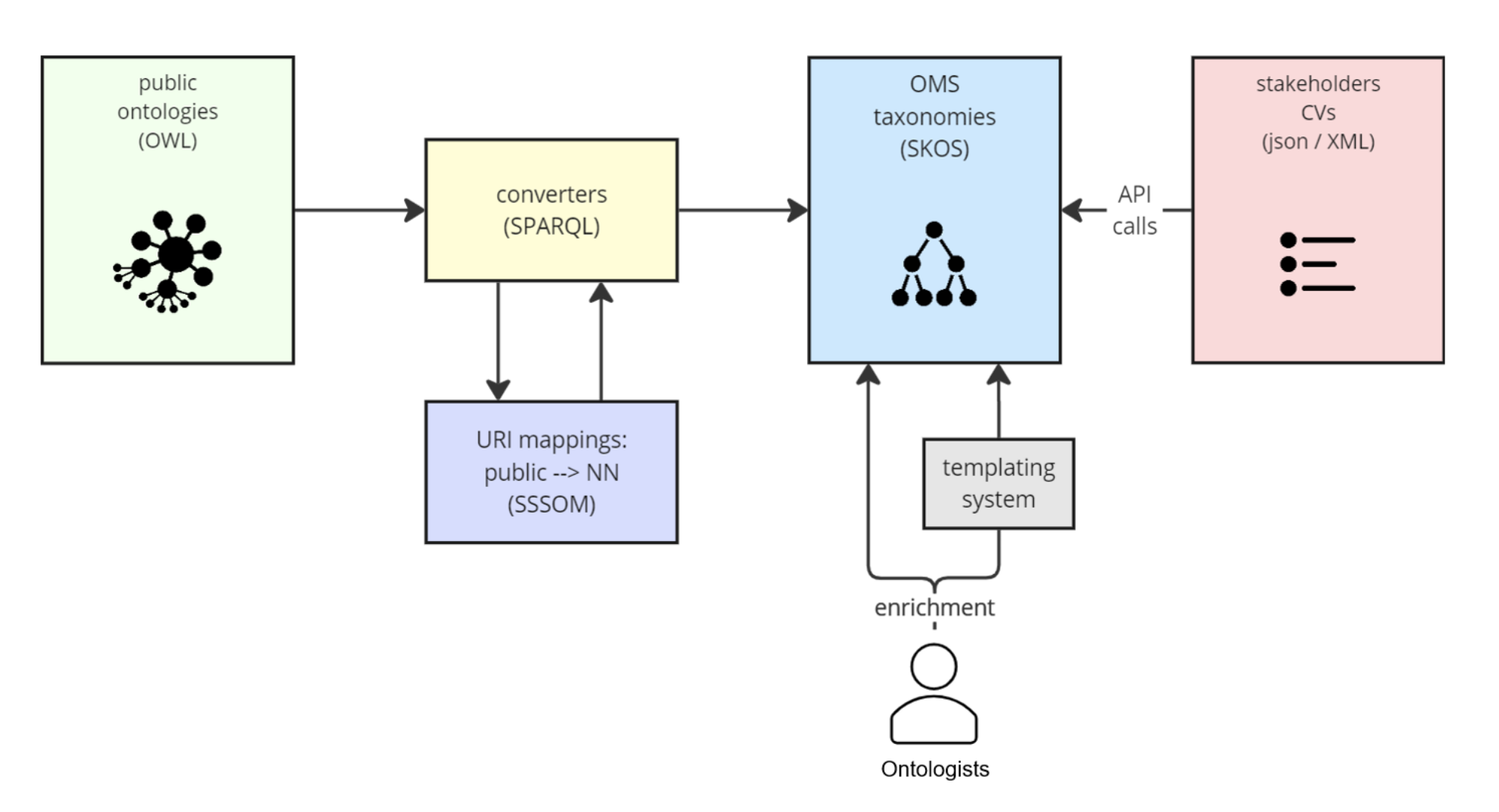
Compared with other FAIR vocabulary requirements, FVFs apply to multiple vocabulary formats, and we demonstrated the potential for using them across other forms of vocabularies with the ICD-11 example. We focused on how FVFs can be applied to ontologies and did not include other types of vocabulary specifications, because an ontology has a clearly defined structure, schema, standards, repositories, and supporting standards.
Integrating the FVF with FAIR indicators makes it possible to assess the FAIR level of vocabularies, identify progressive ontology development use cases, and improve accordingly. We selected the RDA indicators since they have proven to be useful in many datasets, and have been referenced by other assessment approaches in FAIRassist.org; yet, FVFs could alternatively be aligned to other FAIR-principle-based indicators which would similarly reflect the FAIR principles. The RDA indicators are designed to evaluate biomedical datasets, where data refers to outcomes of sequencing or screening experiments, and metadata refers to sample information, experiment designs, etc, which needs to be annotated with controlled vocabularies. In our context, data refers to the vocabulary themselves, and metadata, on the other hand, points to ontology versioning and editing information. When performing an assessment, it is crucial for assessors to agree on the definition of data and metadata.
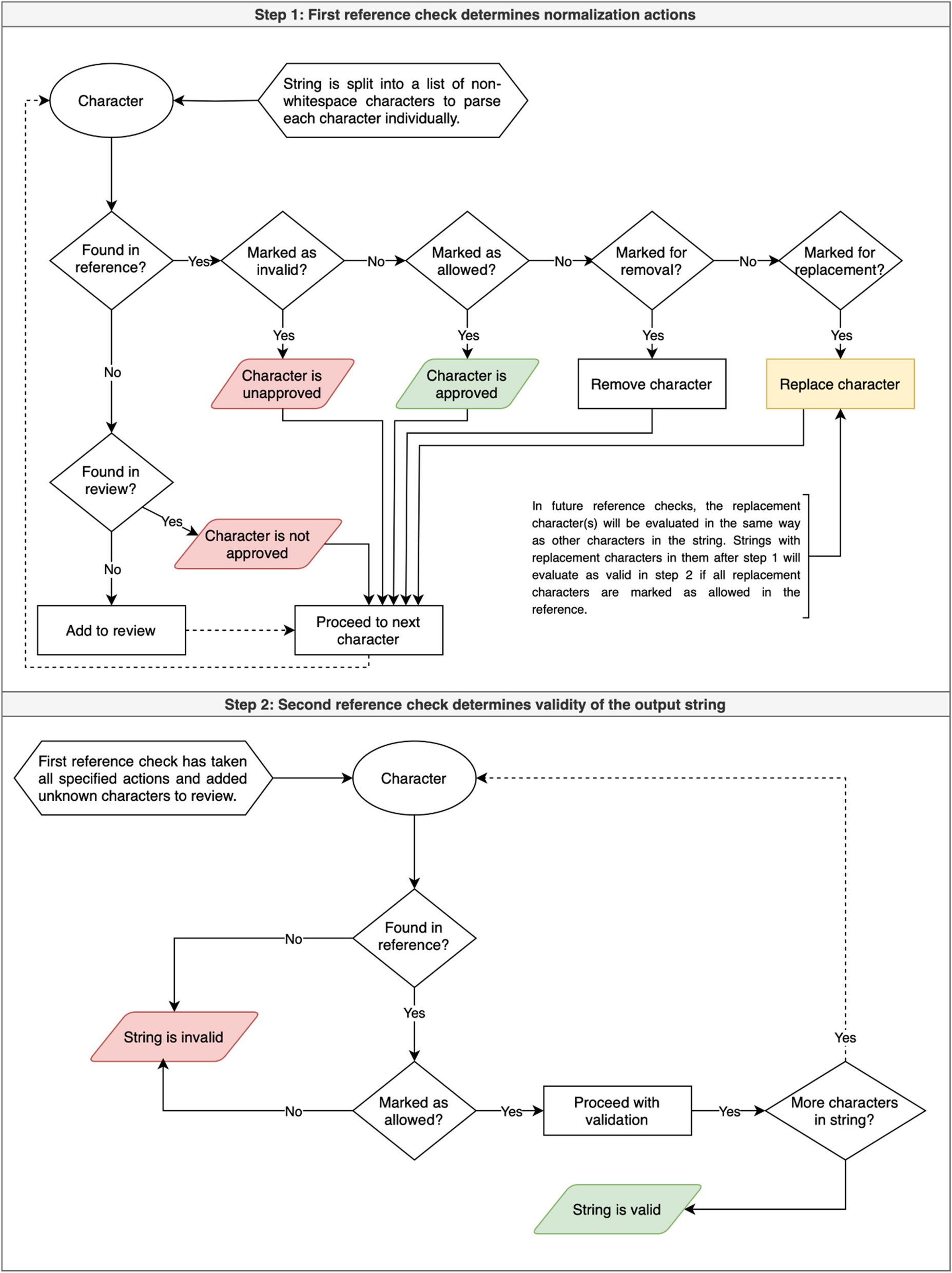
Besides manual assessments, quantifiable formal indicators are also amenable to becoming machine-actionable. Reusing shared indicators will make it possible to perform automated FAIR vocabulary assessments. The bottleneck of automated assessment, however, is the variations in the implementation of the same requirement. For example, the VersionIRI case presented above demonstrates the challenges of exhausting all formats of interpretation to build a unified assessment service. Other features, such as “Complying with domain standards” are even harder to automate. Therefore, manual assessment using indicators for FVFs is still one of the more practical and accurate approaches.
The FAIR scores provide a quantitive and intuitive “summary” of the FAIR level of a vocabulary and can be an effective measure of how the vocabulary has evolved. However, it should neither be taken as an absolute measure to evaluate either the quality comparison across vocabularies or compare different vocabularies. For example, for vocabularies which are used and shared within an institution and not designed for external usage, having global identifiers (FVF-1) is not a core requirement. In this case, the vocabulary is still FAIR for its designed purpose within the organisation, even if the FAIR score is low. When checking the FAIR level of a vocabulary, it is important to examine the detailed use cases and features, instead of just comparing scores. A vocabulary being “FAIR enough” for its purpose is more important than having a general FAIR score. Moreover, each assessment system might have different FAIR scores for the same vocabulary. Instead of aiming for an absolute higher score, assessors should understand the mechanism behind each indicator, and focus on the interpretation of each test.
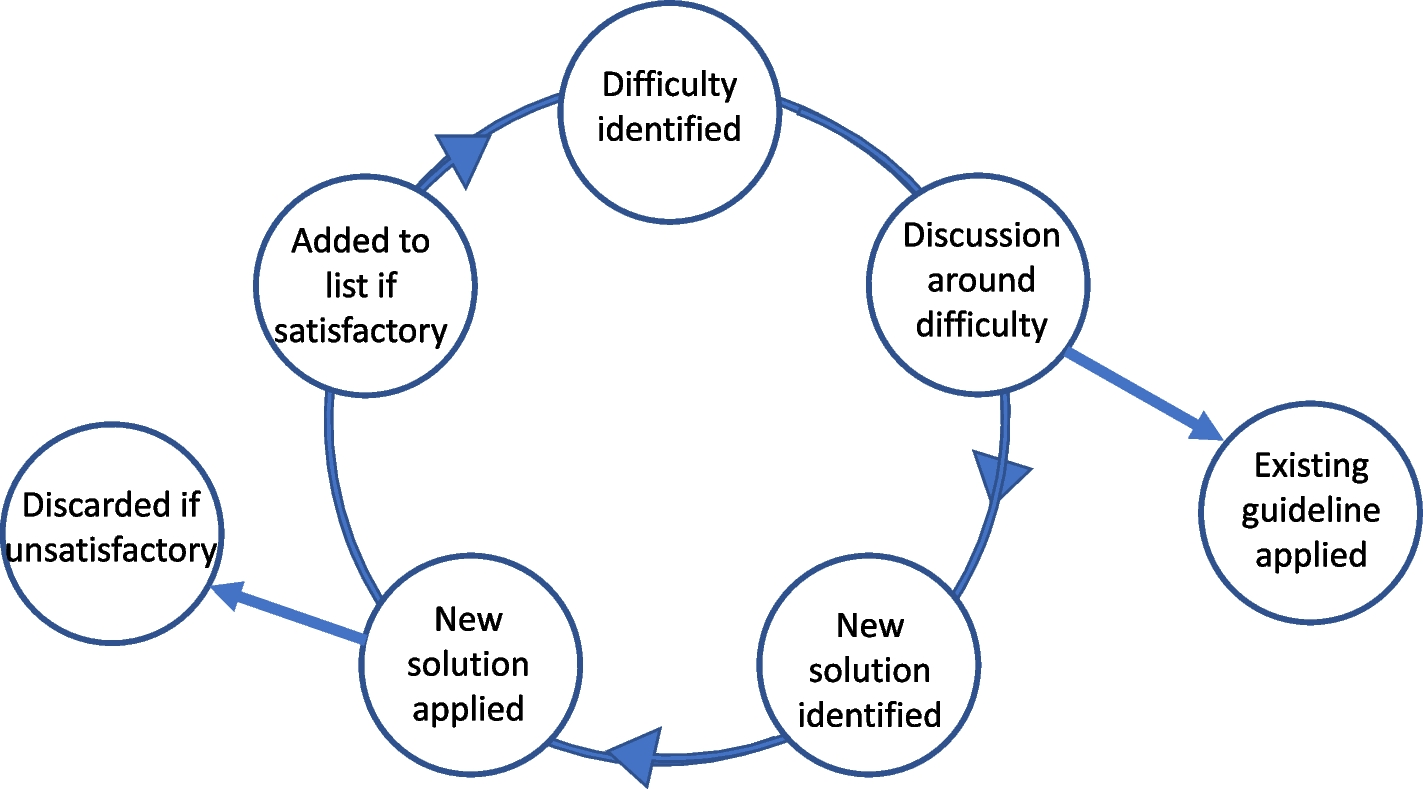
These FVF and assessments provide insights on how to improve vocabularies. For example, based on the EFO assessments, the FAIR level of EFO could easily be improved by adding a description of the aim and function of EFO, allowing different vocabulary management services to harvest that information. They also assist and guide the evolution of FAIR vocabularies by striving to iteratively improve FAIR levels of subsequently developed versions. For example, compared to ICD-10, its successor ICD-11 has incorporated many features to make it FAIRer, such as providing application programming interfaces (APIs) for easier access, having a machine-readable license, etc.








Comments (0)