
Remember me


This study employed the Bidirectional Encoder Representations from Transformers (BERT) model to automate tweet classification [20] to classify tweets about vaccine mandates from a larger database of all vaccine-related tweets. Supervised learning methods were employed for text classification to identify tweets related to vaccine mandates [21]. Unlike dictionary-based approaches, supervised learning offers the advantage of capturing implicit discussions about vaccine mandates. This is particularly valuable for tweets that do not contain explicit terms like “mandate” or “requirement.” For instance, a tweet like “So nobody upset that you can’t travel internationally without vaccinating?” would likely be missed by a dictionary approach, yet a supervised learning model can classify it as relevant due to the underlying context.
Analyses were conducted at two levels: the individual tweet level and the state-date level. At the tweet level, I compared tweets discussing vaccine mandates with vaccine-related tweets unrelated to vaccine mandates. At the state level, I used the proportion of mandate-related tweets among all vaccine-related tweets as a proxy for the salience of vaccine requirements within a state on a specific date. This proportion was then investigated for its association with aggregate levels of negativity and anger.
Tweets about vaccines and public health officialsTweets from July 2021 to February 2022 were collected using the Twitter Academic Research product track’s full-archive search endpoint (Twitter API v2). This endpoint retrieves historical public tweets that have met a search query since March 2006. The keywords to collect vaccine-related tweets include vaccine, vaccines, vaccinate, vaccinates, vaccinated, vaccinating, vaccination, vaccinations, vaccinemandate, and vaccinemandates; the keywords to collect tweets related to public health officials are fauci, anthonyfauci, drfauci, #fauci, #anthonyfauci, #drfauci, #FireFauci, #ArrestFauci, cdc, #cdc, CDCgov, and Centers for Disease Control. Tweets were then filtered to include only those in English and from the U.S., utilizing both tweet geotags and self-reported user locations [22]. This process resulted in a dataset of 6,655,234 tweets containing vaccine keywords, of which 5,836,423 could be geolocated to the state level. Similarly, 949,691 tweets containing public health authority keywords were identified and geolocated to the state level.
Classifying mandate-related tweetsThe BERTweet model [23], a BERT model pre-trained on tweets, was used to classify mandate-related tweets. To train machine learning models, a random sample of 3324 tweets was manually labeled by myself and research assistants. Each tweet was coded by two human coders, and in cases where the coders assigned different labels, a third coder provided the final label. Tweets discussing vaccination policies requiring inoculation to avoid restrictions (government- or private entity-imposed mandates for work or activities) were classified as mandate-related (see Supplementary Material Appendix A).
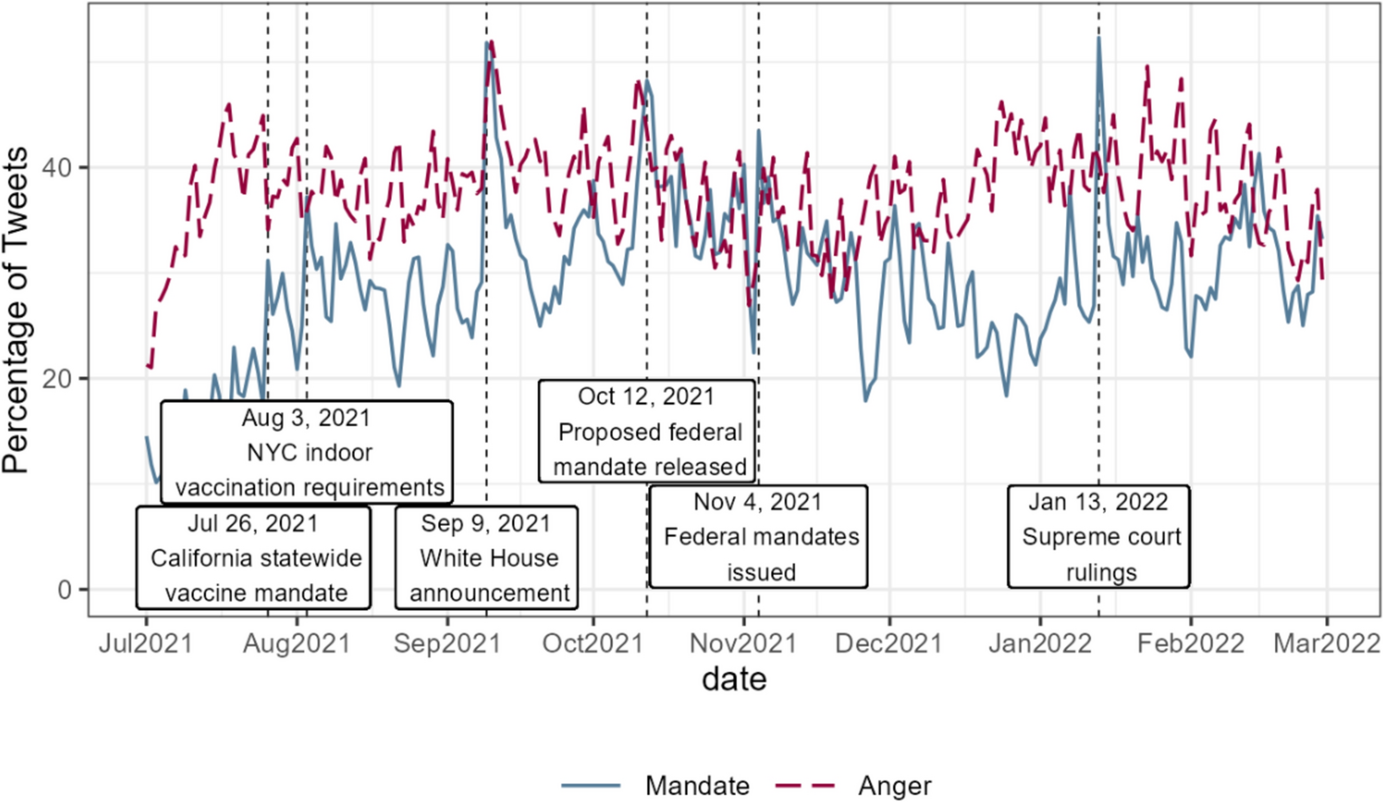
BERTweet identified a total of 1,988,078 (29.87%) mandate-related tweets from all vaccine-related tweets. Figure 1 shows the percentage of mandate-related tweets out of all vaccine-related tweets over time. The trend reflects the major events related to vaccine mandates, including the first state-wide vaccine mandate in the U.S. issued by California, New York City’s indoor vaccine requirements, and the important dates of the federal mandates for healthcare workers and large employers. The global peak is January 13, 2022, when the Supreme Court ruled on the federal mandates.
Fig. 1
The daily percentage of mandate-related tweets and angry tweets, as classified by the machine learning models, among all vaccine-related tweets in the United States. The solid line and the dashed line represent the percentages of mandate-related tweets and angry tweets, respectively
Negative sentiment in texts, anger in texts, and freedom-related words in textsNegative sentiment within tweets was measured using the Valence Aware Dictionary and sEntiment Reasoner (VADER) [24] and TweetNLP’s sentiment analysis model [25]. VADER is a rule-based sentiment analysis lexicon specifically tuned for social media. VADER assigns negative sentiment scores not only based on words but also considers punctuation, emoticons, emoji, and capitalization. VADER calculates three scores from a text—negative, positive, and neutral—on a scale from 0 to 1. The scores were rescaled to 0 to 100 in order to match the range of other measures in the study. VADER also calculates the compound score calculated from the negative, positive, and neutral scores (on a scale from − 1 to + 1). TweetNLP is a pre-trained large language model built on an optimized version of BERT [26] and trained on a substantial dataset of tweets. It provides a range of fine-tuned models for various downstream tasks, including sentiment analysis. Its sentiment analysis model assigns one of three labels—positive, neutral, or negative—based on predicted probabilities.
Anger levels were measured by two methods: the percentage of words in the anger category from the Word-Emotion Association Lexicon [27] and TweetNLP’s multilabel emotion analysis model. The multilabel model allows a text to be labeled with multiple emotions for a single tweet. The machine-learning-based anger variable was measured by whether TweetNLP’s emotion analysis model labeled a tweet as an angry tweet. Tweets were coded for the presence of specific freedom-related words: freedom, liberty, rights, and choice.
Statistical analysisGiven the large sample size of the data, the central limit theorem was applied, enabling hypothesis testing under the assumption that the probability distributions of the estimators approximate normal distributions. First, proportional tests were conducted to examine differences in proportions between mandate-related and non-mandate-related tweets for the following binary measures: (1) whether a tweet contained freedom-related words, (2) whether a tweet was classified as negative by a machine-learning-based method, and (3) whether a tweet was classified as angry by a machine-learning-based method. The alternative hypotheses were that mandate-related tweets were more likely to contain freedom-related words, be negative, and express anger compared to non-mandate-related tweets. Second, differences in means were tested for (1) the negativity score measured by a rule-based method and (2) the percentage of angry words identified by the rule-based method. The alternative hypotheses were that mandate-related tweets were more negative and angrier than non-mandate-related tweets. Additionally, Wilcoxon signed-rank tests were conducted as a robustness check for continuous measures measured by the rule-based methods.
State-date panel data analysisThese analyses explored the relationship between the salience of vaccine mandates and the aggregate sentiment and emotion expressed in tweets concerning vaccines and public health officials. Tweets were aggregated by state and by date to identify periods, where vaccine mandates were highly salient by the percentage of mandate-related tweets within the total volume of vaccine-related tweets. The use of tweet volume as an indicator of issue salience is supported by prior research [28, 29].
The panel data (repeated measures) were analyzed with the emphasis on two dimensions: states (all 50 states and the District of Columbia) and days (243 days), totaling 12,393 observations. Given the structure of the data, I employed a two-way fixed effects model: state fixed effects to account for time-invariant state-level confounders (historical vaccine hesitancy, political orientation), and date fixed effects to control for time-specific confounders. Additionally, I used Driscoll and Kraay’s panel Newey–West type of standard errors [30], a semiparametric method, to address both cross-sectional and serial correlation in the models.
Nine regression models were estimated to investigate the relationship between vaccine mandate salience and various sentiments and emotions expressed in tweets. The key independent variable in all models is the percentage of mandate-related tweets out of all vaccine-related tweets in a state and date, serving as a proxy for the salience of vaccine requirements. The dependent variables are (1) the percentage of vaccine-related tweets containing a freedom-related word, (2) the mean negative sentiment score in vaccine-related tweets, (3) the mean percentage of anger words in vaccine-related tweets, (4) the mean negative sentiment score in tweets about public health officials, and (5) the mean percentage of anger words in tweets about public health officials. All models controlled for the following covariates: (1) the natural log of the number of vaccine-related tweets per person, (2) the natural log of the seven-day moving average of new COVID-19 cases and deaths per person to account for disease severity, (3) the natural log of the seven-day moving average of new COVID-19 vaccine doses per person and the percentage of the fully vaccinated population in a state to control for vaccination progress, and (4) the weighted standard deviation of the percentage of the fully vaccinated population across counties within a state to capture within-state polarization.
Comments (0)