S. Zou, J. He, Large Language Models in Healthcare: A Review, 2023 7th International Symposium on Computer Science and Intelligent Control (ISCSIC), 2023, pp. 141–145.
F. Busch, L. Hoffmann, D.P. dos Santos, M.R. Makowski, L. Saba, P. Prucker, M. Hadamitzky, N. Navab, J.N. Kather, D. Truhn, R. Cuocolo, L.C. Adams, K.K. Bressem, Large language models for structured reporting in radiology: past, present, and future, European Radiology (2024).
M. Naji, M. Masmoudi, H.B. Zghal, Towards an LLM based approach for medical e-consent, Procedia Computer Science 246 (2024) 3694–3701.
Article
Google Scholar
F. Busch, L. Hoffmann, C. Rueger, E.H. van Dijk, R. Kader, E. Ortiz-Prado, M.R. Makowski, L. Saba, M. Hadamitzky, J.N. Kather, Systematic Review of Large Language Models for Patient Care: Current Applications and Challenges, medRxiv (2024) 2024.03. 04.24303733.
H. Decker, K. Trang, J. Ramirez, A. Colley, L. Pierce, M. Coleman, T. Bongiovanni, G.B. Melton, E. Wick, Large Language Model−Based Chatbot vs Surgeon-Generated Informed Consent Documentation for Common Procedures, JAMA Network Open 6(10) (2023) e2336997–e2336997.
Article
PubMed
PubMed Central
Google Scholar
F.N. Mirza, O.Y. Tang, I.D. Connolly, H.A. Abdulrazeq, R.K. Lim, G.D. Roye, C. Priebe, C. Chandler, T.J. Libby, M.W. Groff, J.H. Shin, A.E. Telfeian, C.E. Doberstein, W.F. Asaad, Z.L. Gokaslan, J. Zou, R. Ali, Using ChatGPT to Facilitate Truly Informed Medical Consent, NEJM AI 1(2) (2024) AIcs2300145.
G. Currie, S. Robbie, P. Tually, ChatGPT and Patient Information in Nuclear Medicine: GPT-3.5 Versus GPT-4, J Nucl Med Technol 51(4) (2023) 307–313.
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, H. Wang, Retrieval-augmented generation for large language models: A survey, arXiv preprint arXiv:2312.10997 (2023).
M.E. Mamalis, E. Kalampokis, F. Fitsilis, G. Theodorakopoulos, K. Tarabanis, A Large Language Model Agent Based Legal Assistant for Governance Applications, International Conference on Electronic Government, Springer, 2024, pp. 286–301.
J. Wu, J. Zhu, Y. Qi, J. Chen, M. Xu, F. Menolascina, V. Grau, Medical graph rag: Towards safe medical large language model via graph retrieval-augmented generation, arXiv preprint arXiv:2408.04187 (2024).
K.D. Hopper, H.N. Tyler, Informed consent for intravascular administration of contrast material: how much is enough?, Radiology 171(2) (1989) 509–514.
Article
CAS
PubMed
Google Scholar
salary.com, Hourly Wage for Radiologist Salary in the United States, 2024. https://www.salary.com/research/salary/alternate/radiologist-hourly-wages. (Accessed 26.12.2024.
D. Truhn, C.D. Weber, B.J. Braun, K. Bressem, J.N. Kather, C. Kuhl, S. Nebelung, A pilot study on the efficacy of GPT-4 in providing orthopedic treatment recommendations from MRI reports, Sci Rep 13(1) (2023) 20159.
Article
CAS
PubMed
PubMed Central
Google Scholar
OpenAI, GPT-4 Technical Report, 2023, p. arXiv:2303.08774.
X. Li, J. Li, AoE: Angle-optimized embeddings for semantic textual similarity, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 1825–1839.
G. Van Rossum, F.L. Drake, The Python Language Reference Manual: For Python Version 3.2, Network Theory Limited2011.
C.R. Harris, K.J. Millman, S.J. van der Walt, R. Gommers, P. Virtanen, D. Cournapeau, E. Wieser, J. Taylor, S. Berg, N.J. Smith, R. Kern, M. Picus, S. Hoyer, M.H. van Kerkwijk, M. Brett, A. Haldane, J.F. del Río, M. Wiebe, P. Peterson, P. Gérard-Marchant, K. Sheppard, T. Reddy, W. Weckesser, H. Abbasi, C. Gohlke, T.E. Oliphant, Array programming with NumPy, Nature 585(7825) (2020) 357–362.
Article
CAS
PubMed
PubMed Central
Google Scholar
W. McKinney, Data structures for statistical computing in Python, SciPy, 2010, pp. 51–56.
P. Virtanen, R. Gommers, T.E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright, SciPy 1.0: fundamental algorithms for scientific computing in Python, Nature methods 17(3) (2020) 261–272.
S. Seabold, J. Perktold, Statsmodels: econometric and statistical modeling with python, SciPy 7(1) (2010).
A. Braga, N.C. Nunes, E.N. Santos, M.L. Veiga, A. Braga, G.E. de Abreu, J.J. de Bessa, L.H. Braga, A.J. Kirsch, U.J. Barroso, Use of ChatGPT in Urology and its Relevance in Clinical Practice: Is it useful?, Int Braz J Urol 50(2) (2024) 192–198.
Article
PubMed
PubMed Central
Google Scholar
J.M.M. Rogasch, G. Metzger, M. Preisler, M. Galler, F. Thiele, W. Brenner, F. Feldhaus, C. Wetz, H. Amthauer, C. Furth, I. Schatka, ChatGPT: Can You Prepare My Patients for [<sup>18</sup>F]FDG PET/CT and Explain My Reports?, Journal of Nuclear Medicine (2023) jnumed.123.266114.
W. Floyd, T. Kleber, D.J. Carpenter, M. Pasli, J. Qazi, C. Huang, J. Leng, B.G. Ackerson, M. Pierpoint, J.K. Salama, M.J. Boyer, Current Strengths and Weaknesses of ChatGPT as a Resource for Radiation Oncology Patients and Providers, International Journal of Radiation Oncology, Biology, Physics (2023).
M. Chowdhury, E. Lim, A. Higham, R. McKinnon, N. Ventoura, Y. He, N. Pennington, Can Large Language Models Safely Address Patient Questions Following Cataract Surgery?, 2023.
M.B. Singer, J.J. Fu, J. Chow, C.C. Teng, Development and Evaluation of Aeyeconsult: A Novel Ophthalmology Chatbot Leveraging Verified Textbook Knowledge and GPT-4, J Surg Educ (2023).
H. Mohammad-Rahimi, S.A. Ourang, M.A. Pourhoseingholi, O. Dianat, P.M.H. Dummer, A. Nosrat, Validity and reliability of artificial intelligence chatbots as public sources of information on endodontics, Int Endod J 57(3) (2024) 305–314.
Article
PubMed
Google Scholar
M. Moll, G. Heilemann, D. Georg, D. Kauer-Dorner, P. Kuess, The role of artificial intelligence in informed patient consent for radiotherapy treatments—a case report, Strahlentherapie und Onkologie 200(6) (2024) 544–548.
Article
CAS
PubMed
Google Scholar
G. Xiong, Q. Jin, Z. Lu, A. Zhang, Benchmarking retrieval-augmented generation for medicine, arXiv preprint arXiv:2402.13178 (2024).
Y. Ke, L. Jin, K. Elangovan, H.R. Abdullah, N. Liu, A.T.H. Sia, C.R. Soh, J.Y.M. Tung, J.C.L. Ong, D.S.W. Ting, Development and Testing of Retrieval Augmented Generation in Large Language Models--A Case Study Report, arXiv preprint arXiv:2402.01733 (2024).
M. Luo, C.J. Warren, L. Cheng, H.M. Abdul-Muhsin, I. Banerjee, Assessing Empathy in Large Language Models with Real-World Physician-Patient Interactions, arXiv preprint arXiv:2405.16402 (2024).
J.W. Ayers, A. Poliak, M. Dredze, E.C. Leas, Z. Zhu, J.B. Kelley, D.J. Faix, A.M. Goodman, C.A. Longhurst, M. Hogarth, D.M. Smith, Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum, JAMA Internal Medicine 183(6) (2023) 589–596.
Article
PubMed
PubMed Central
Google Scholar
E. Montague, P.-Y. Chen, J. Xu, B. Chewning, B. Barrett, Nonverbal interpersonal interactions in clinical encounters and patient perceptions of empathy, J Participat Med 5(33) (2013) 1–17.
Google Scholar
P.H. Yen, A.R. Leasure, Use and effectiveness of the teach-back method in patient education and health outcomes, Federal practitioner 36(6) (2019) 284.
PubMed
PubMed Central
Google Scholar
J. Talevski, A. Wong Shee, B. Rasmussen, G. Kemp, A. Beauchamp, Teach-back: A systematic review of implementation and impacts, PLoS One 15(4) (2020) e0231350.
F. Derksen, J. Bensing, A. Lagro-Janssen, Effectiveness of empathy in general practice: a systematic review, Br J Gen Pract 63(606) (2013) e76–84.
Article
PubMed
Google Scholar
C.F.C. Campos, C.R. Olivo, M.A. Martins, P.Z. Tempski, Physician’s attention to patient’s communication cues can improve patient satisfaction with care and perception of physician’s empathy, Clinics (Sao Paulo) 79 (2024) 100377.
Article
PubMed
Google Scholar
C. Ren, Y. Zhang, D. He, J. Qin, WundtGPT: Shaping Large Language Models To Be An Empathetic, Proactive Psychologist, arXiv preprint arXiv:2406.15474 (2024).
E.Y. Chang, Behavioral Emotion Analysis Model for Large Language Models, 2024 IEEE 7th International Conference on Multimedia Information Processing and Retrieval (MIPR), 2024, pp. 549–556.
S.S. Li, V. Balachandran, S. Feng, J. Ilgen, E. Pierson, P.W. Koh, Y. Tsvetkov, MEDIQ: Question-Asking LLMs for Adaptive and Reliable Medical Reasoning, arXiv preprint arXiv:2406.00922 (2024).
Z. Ren, Y. Zhan, B. Yu, L. Ding, D. Tao, Healthcare copilot: Eliciting the power of general llms for medical consultation, arXiv preprint arXiv:2402.13408 (2024).
R. Kumar, D.R.K. Gattani, K. Singh, Enhancing Medical History Collection using LLMs, Proceedings of the 2024 Australasian Computer Science Week, Association for Computing Machinery, Sydney, NSW, Australia, 2024, pp. 140–143.
K. Lekadir, A.F. Frangi, A.R. Porras, B. Glocker, C. Cintas, C.P. Langlotz, E. Weicken, F.W. Asselbergs, F. Prior, G.S. Collins, G. Kaissis, G. Tsakou, I. Buvat, J. Kalpathy-Cramer, J. Mongan, J.A. Schnabel, K. Kushibar, K. Riklund, K. Marias, L.M. Amugongo, L.A. Fromont, L. Maier-Hein, L. Cerdá-Alberich, L. Martí-Bonmatí, M.J. Cardoso, M. Bobowicz, M. Shabani, M. Tsiknakis, M.A. Zuluaga, M.-C. Fritzsche, M. Camacho, M.G. Linguraru, M. Wenzel, M. De Bruijne, M.G. Tolsgaard, M. Goisauf, M. Cano Abadía, N. Papanikolaou, N. Lazrak, O. Pujol, R. Osuala, S. Napel, S. Colantonio, S. Joshi, S. Klein, S. Aussó, W.A. Rogers, Z. Salahuddin, M.P.A. Starmans, FUTURE-AI: international consensus guideline for trustworthy and deployable artificial intelligence in healthcare, BMJ 388 (2025) e081554.
U. Mahmood, A. Shukla-Dave, H.P. Chan, K. Drukker, R.K. Samala, Q. Chen, D. Vergara, H. Greenspan, N. Petrick, B. Sahiner, Z. Huo, R.M. Summers, K.H. Cha, G. Tourassi, T.M. Deserno, K.T. Grizzard, J.J. Näppi, H. Yoshida, D. Regge, R. Mazurchuk, K. Suzuki, L. Morra, H. Huisman, S.G. Armato, 3rd, L. Hadjiiski, Artificial intelligence in medicine: mitigating risks and maximizing benefits via quality assurance, quality control, and acceptance testing, BJR Artif Intell 1(1) (2024) ubae003.
M. Finsås, J. Maksim, Optimizing RAG Systems for Technical Support with LLM-based Relevance Feedback and Multi-Agent Patterns, NTNU, 2024.
S. Simon, A. Mailach, J. Dorn, N. Siegmund, A Methodology for Evaluating RAG Systems: A Case Study On Configuration Dependency Validation, arXiv preprint arXiv:2410.08801 (2024).
G. Agrawal, T. Kumarage, Z. Alghamdi, H. Liu, Mindful-rag: A study of points of failure in retrieval augmented generation, arXiv preprint arXiv:2407.12216 (2024).

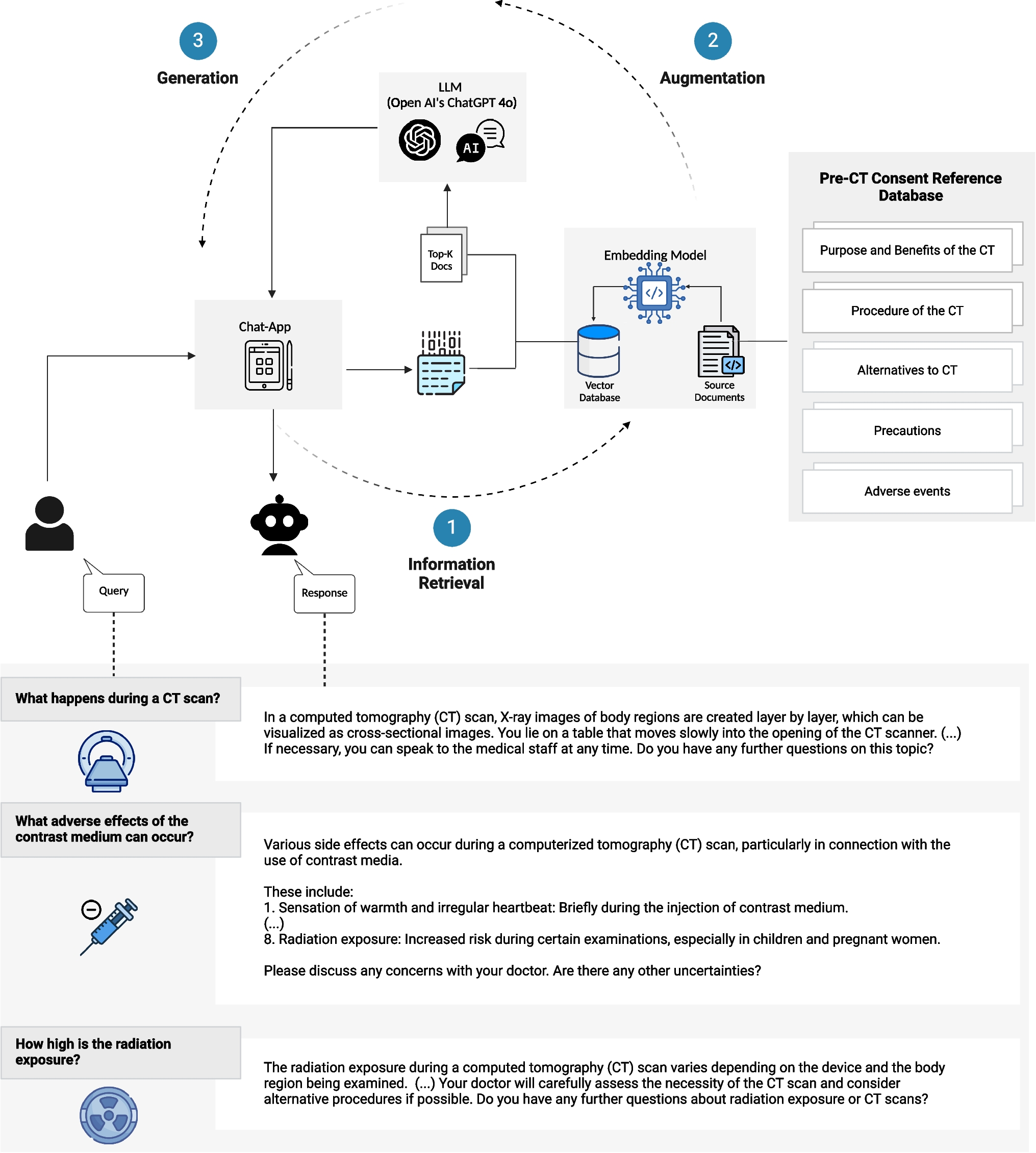


Comments (0)