
Remember me


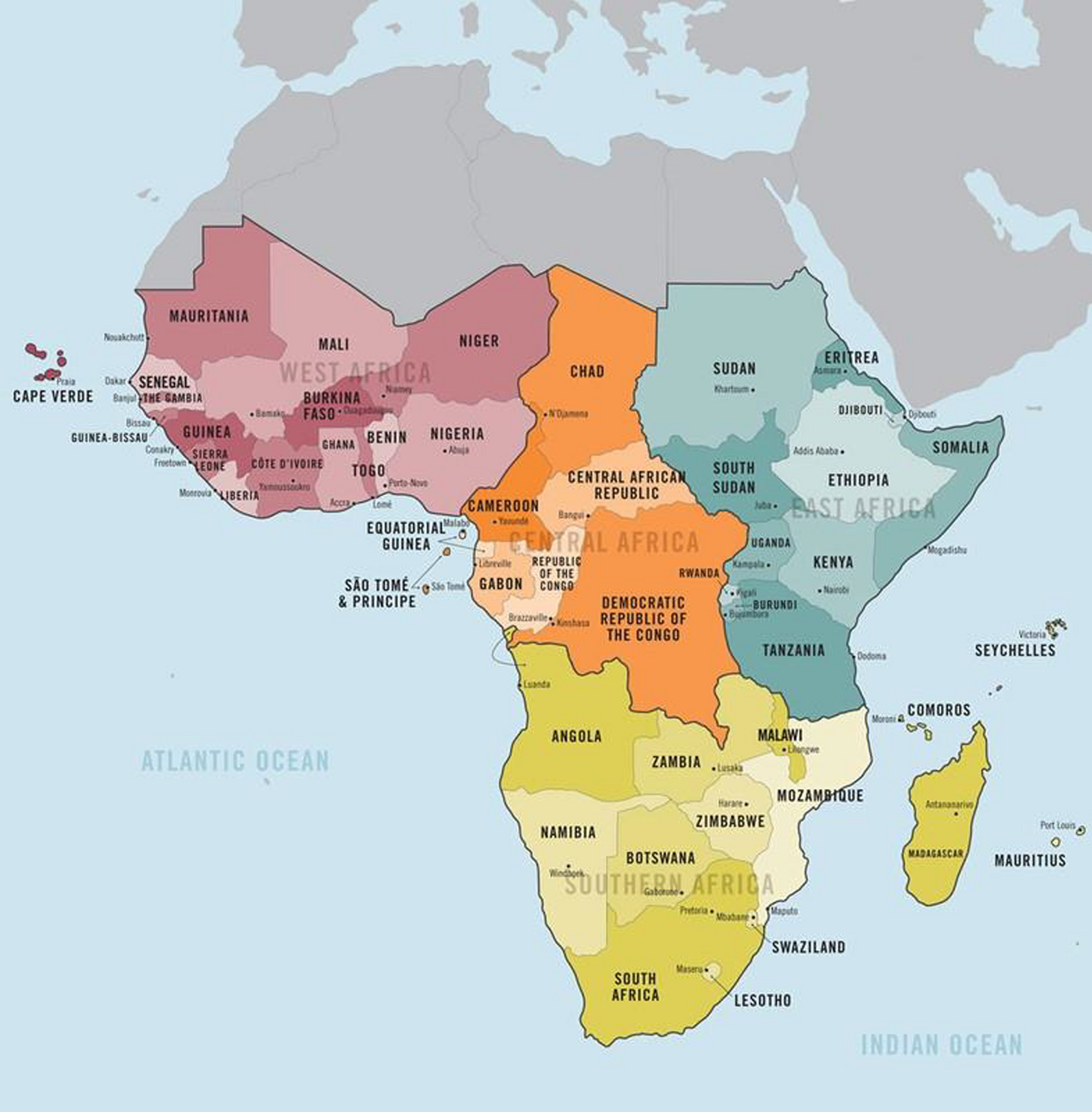




This study is an analysis of multi-country cross-sectional population-based surveys conducted in SSA between 2014 and 2021 by the DHS. The DHS is often conducted in five years interval and cut across the lower-middle-income countries including the sub-Saharan African countries. The SSA comprises of up to 46 countries with over a billion population and the one-fourth of the population is dominated by the reproductive age women 15–49 years [29]. Geographically, the SSA countries are in western, central, eastern, and southern Africa as shown in the study area map in Fig. 1.
Fig. 1
Map of Africa showing the Countries in the Sub-Saharan African Region
Data sourceThe recently (2014–2021) available country survey data on women of reproductive age 15–49 years (individual recode) was pulled from the open repository of the demographic health survey across 25 sub-Saharan Africa countries. The survey information can be accessed via the link https://dhsprogram.com
Data collection, sampling and participantsThe study population comprises of the women of reproductive age who had given birth to at least a child in the last five years preceding the country demographic health survey. The survey usually utilized a multistage sampling to select respondent per household, based on the individual country sampling frame as defined in the country population census. The first stage sampling is the selection of the district or local government areas, and the subsequent selection of the enumeration area (whether rural or urban) is the second stage sampling while the last stage sampling is the selection of the household within the enumeration areas cluster referred to as the primary sampling unit (PSU). The demographic health survey had documented the sampling strategy in the survey reports. A total of 220,865 (66,276 in urban and 154,590 in rural) women of reproductive age 15–49 years across 25 SSA countries made up the weighted sample size.
Outcome indicatorsPrimary OutcomeThe outcome of interest in this study is the type of place of delivery which is whether institutional i.e. at a health facility or non-institutional i.e. at a place other than a healthcare facility (this includes homes, faith-based, other homes i.e. friend/parent homes). Outcome variable was extracted from the response to the question “Where did you have the delivery of child?” and was classified as illustrated below.\(Type\,of\,place\,of\,delivery =\left\1, Noninstitutional\,delivery\,i.e.\,home/faith\\ 0, Institutional\,delivery\,i.e.\,healthcare\,facility\end\right.\)
$$Type\,of\,place\,of\,delivery =\left\1, Noninstitutional\,delivery\,i.e.\,home/faith\\ 0, Institutional\,delivery\,i.e.\,healthcare\,facility\end\right.$$
Secondary outcomeMaternal mortality which measure the annual number of female deaths from any cause related to or aggravated by pregnancy or its management (excluding accidental or incidental causes) during pregnancy and childbirth or within 42 days of termination of pregnancy, irrespective of the duration and site of the pregnancy, and the lifetime risk of maternal death which assess the probability that a 15 year old will die from a maternal cause are the secondary outcome measures [3, 30]. Both can be computed as:
$$Maternal\,Mortality\,Ratio = \frac \right)\,death\,at\,a\,setting/period}}} \times 100,000.$$
$$Lifetime\;Risk\;of\;Maternal\;Death = \sum\nolimits_ } \times f_ \times \frac }}} }}$$
where; \(_\) is the maternal mortality ratio at age x.
\(_\) is the fertility rate at age x.
\(_\) is the number of woman-years of exposure to the risk of dying from maternal cause at age x.
\(_\) is the probability that a girl will survive to age 15.
Explanatory factorsExplanatory variables that predetermined women type of place of delivery was identified from previous literatures assessing the related outcome in SSA [7, 8, 25,26,27, 31]. This is based on the factors measured in the demographic health survey. These factors were classified in the domains of socio-demographics, obstetrics, and maternal health as well as community and country-level factors as described below.
Socio-demographic characteristicsAge-group (15–24; 25–34; 35–49 years), highest educational level (no education; primary; secondary; higher), partner’s highest education (no education; primary; secondary; higher), occupation (not currently employed; currently employed), marital status (ever married; never married), wealth status (poor; average; rich), media exposure (not exposed to media; exposed to media), sex of household head (male; female).
Obstetrics and health-related factorsThese are factors assessing whether women were covered by health insurance (no; yes), birth order (one, two, three, four, five and above), wanted last child (wanted then; wanted later; wanted no more), healthcare decision maker (respondent alone; respondent and husband; husband/partner alone; someone else/others), sex of child at birth (male; female), antenatal care attendance (none; 1–3; 4–7; 8 and above visits), skilled birth attendant at delivery (no; yes).
Community and country-level factorsThis includes place of residence (urban; rural) and SSA region (central; eastern; southern; western; African Island Nation). The country income (low income; lower-middle income; upper-middle income) was classified based on the recent world bank GDP threshold and poverty level per region [32].
Data management and statistical analysisThe twenty-five countries survey data pulled from the DHS database was merged to achieve a pooled data about reproductive aged women (15–49 years). The merged/appended data was validated to ensure variables align throughout the dataset and data completeness and consistency was also assessed through complete omission of data missing both at random and not at random to achieve a clean data for analysis.
In preparation for analysis, the cleaned and complete data following case wise deletion of missing and incomplete maternal information/data was weighted using the women weighting indices in the DHS to adjust for population heterogeneity and verified from the frequency distribution of the outcome data. Statistical analysis commenced with the descriptive analysis of the independent factors viz-a-viz the type of place of residence. Hence the frequency and percentages were the reported statistics. The dichotomized outcome (institutional -0, non-institutional-1) was graphically presented to reveal country prevalence.
Bivariate analysis was performed to show the distribution (in frequency and percentages) of the independent factors by the outcome (institutional versus non-institutional delivery) and reveal the inherent association using the Pearson chi-square test of statistical significance set at 20% (p < 0.20) and to give allowance for equal chance of variable inclusion without stringent rule in the multivariable analysis. This was performed for both the rural and urban strata. Consequently, all the variables were reported based on the Pearson chi-square test statistic as none of the subgroup had an expected frequency less than 5 and/or 20% of the expected cell count.
Pearson Correlation and simple linear regression was performed to determine the relationship between the normally distributed country NID and MMR as well as NID and LTR estimates. Hence the correlation (rho) and regression (beta) coefficients presented the magnitude of the association. The regression intercept and the R-squared was also reported to assess the explained variation in the model. The pattern of association between NID and MMR as well as NID and LTR was assessed via the linear trend showcasing the direction of relationship. The pattern of relationship was further disaggregated by low- and middle-income countries.
Subsequently, all the 17 variables significant at the bivariate level were included in the multivariable binary logistic regression model fitted to assess the factors effect (likelihood and significance) on women type of place of delivery. Hence the adjusted odds ratio (aOR) was reported. Also, the crude odds ratio (cOR) was reported to assess the independent effect on the outcome in the absence of other factors. The inferential analysis was performed by incorporating the svyset algorithm to adjust for complex survey sampling due to data weighting, clustering, and stratification. All Analysis were performed on Stata version 18 (Texas, College station, USA) at 5% level of significance (95% Confidence Interval). Inferential statistics and/or hypothesis were performed at a two-tailed test, and multiple regression model collinearity was assessed and controlled through variance inflation factor (VIF) such that factor with VIF ≤ 5 was maintained.
Multiple logistic regressionA multiple binary logistic regression was fitted to determine the predictors of non-institutional delivery. This is based on the binary response classification that follows a Bernoulli distribution [P(\(_=0\)), P(\(_=1)]\), such that home/non-institutional delivery = 0 and facility/institutional delivery = 1 for all ith respondents. The equation producing the regression coefficients (or the exponent as odds ratio) is thus estimable under a parabolical curve rather than the straight line in the linear regression. The multivariable binary regression model which is a linear combination of the dependent term Y and independent term X is specified below.
$$Y_ \sim }\left( } \right)$$
(1)
$$Y_ = \ln \left( } \right) = \alpha_ + \alpha_ X_ + \cdots + \alpha_ X_ + \varepsilon$$
(2)
$$E\left( } \right) = Z_ = \frac + \alpha_ x_ + \cdots + \alpha_ x_ } \right)}} + \alpha_ x_ + \cdots + \alpha_ x_ } \right)}}$$
(3)
where: \(\text\left(\frac\right)\) is the log odds (‘π’ is the probability of giving birth at home/non-institutional settings and ‘1-π’ is the probability of giving birth in a health facility/institutional settings).
\(_\) is the logistic regression constant or intercept.
\(_+\cdots + _\) are the kx1 vector of regression coefficient or slopes.
\(_+\cdots +_\) are the nxk matrix of explanatory variables predicting the log odds in the model.
Comments (0)