
Remember me
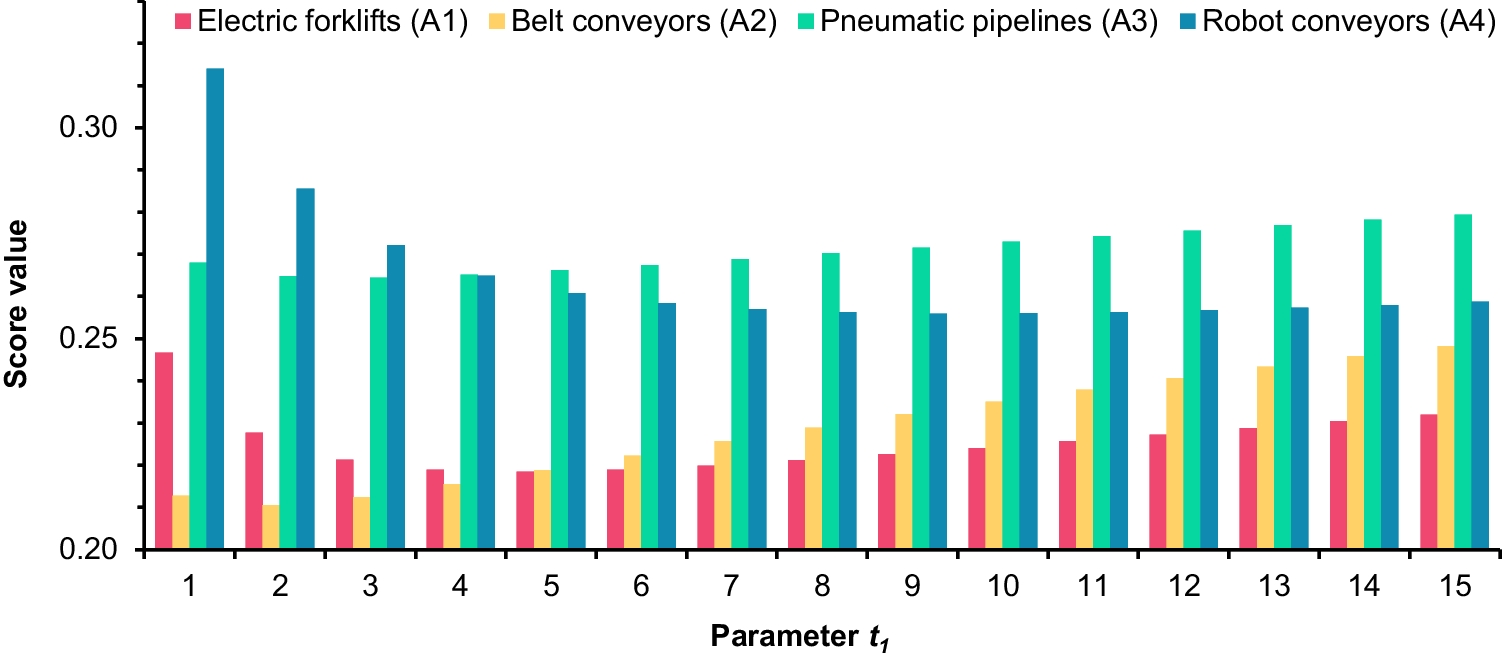

An excellent low-light image enhancement model should be able to restore the details of the image, adjust its brightness, and solve the problem of the degradation of reflection components hidden in the dark. A deep convolutional neural network architecture is proposed to achieve this goal. As shown in Fig. 2, the network can be functionally decomposed into three modules: the decomposition module, the enhancement module, and the adjustment module. The decomposition module is used to extract the lighting and reflection components of the image. It uses a data-driven decomposition method which addresses the problem of poor transferability that is caused when using preset constraints to decompose images. The enhancement module is used to reduce the degradation of object reflection and lighting components caused by noise. The adjustment module is used for complex feature fusion, ensuring the restoration of image detail and color. More information about this network is given below.
Further Thoughts and HypothesisAnalysis of the Retinex TheoryThe Retinex theory posits that the color of an object is primarily determined by its reflectivity, an intrinsic property that remains constant regardless of the light intensity or illumination inhomogeneities to which it is exposed. Thus, an object’s image results from the incident light reflecting off its surface. This reflectivity depends solely on the object’s own characteristics and is unaffected by the characteristics of the incident light. According to Retinex theory, an image I comprises a light component L and a reflection component R, mathematically represented as \( I = R \circ L \).
Although designed for image enhancement under ideal conditions, the traditional decomposition model \( I=R\circ L \) does not account for the influence of noise, which can significantly affect both the reflectance and illumination components after decomposition. This paper introduces the DEANet++ network, which integrates the Retinex model with deep learning techniques to effectively address noise interference. Building on the physical model, DEANet++ offers enhanced interpretability over other deep learning networks and improves the performance of the physical model under non-ideal conditions.
Improvements to DEANetIn our previous research, we introduced DEANet [1] to mitigate the impact of noise on the reflective components during low-light image enhancement. The model was initially based on the premise that image noise predominantly affects high-frequency information with minimal impact on low frequencies. However, subsequent empirical studies have shown that even slight noise within the low-frequency domain can adversely affect the reflective components, leading to decreased image quality and blurriness under dim lighting conditions. To address the interference of low-frequency noise and further improve the quality of restored images, DEANet++ has been redesigned. The enhanced module now integrates a channel attention mechanism to effectively extract features and suppress noise. In the final adjustment module, the inclusion of attention mechanisms ensures thorough integration of image features. Ultimately, this paper presents improvements in the network structure and loss functions, significantly enhancing the quality of image restoration under low-light conditions.
Image DecompositionTraditional methods often decompose images into reflection and lighting components using well-designed, yet rigid constraints that may not be suitable for all applications. In contrast, a data-driven approach to image decomposition has been implemented, effectively overcoming these limitations. During the training phase, pairs of low-light and normal-light images are simultaneously fed into the decomposition network module. This module then processes and separates the images into distinct lighting and reflection components. Trained on a substantial dataset, the module demonstrates enhanced performance in component separation compared to traditional methods restricted by pre-defined rules.
Image EnhancementIn practical scenarios, the degradation observed in low-light images is typically more severe than in normal-light images. This issue extends to the reflection and lighting components derived post-decomposition of these images. Specifically, in the reflection component of objects, the intensity of the lighting component significantly influences the extent of degradation. To address this, an enhancement module is proposed. This module initially learns the mapping relationship between the reflection components of low-light and normal-light objects. Subsequently, it applies this mapping to restore the degraded reflected images.
Image AdjustmentGuided by the principle of \(I = R \circ L\), the adjustment module integrates feature fusion of the reflection and illumination components processed by the enhancement module. This integration facilitates precise tuning of image detail restoration and illumination enhancement. Considering the potential loss of image details in earlier stages within the decomposition and enhancement networks, the adjustment network overlays the enhanced reflection and illumination components onto the original input. This step ensures a comprehensive restoration of image details.
DEANet++Building on the analysis and assumptions discussed in the previous section, we propose the deep neural network, DEANet++. This network not only ensures the restoration of image details but also enhances the brightness of low-light images. The architecture of DEANet++ is illustrated in Fig. 2.
DEANet++ comprises three subnets: a decomposition module, an enhancement module, and an adjustment module. These modules are responsible for decomposing low-light images, enhancing contrast, and adjusting details, respectively. Specifically, the decomposition module separates the low-light image into lighting and object reflectance components based on Retinex theory. The enhancement module focuses on the recovery of reflection and the enhancement of lighting. The processed components are then forwarded to the adjustment module, which aims to further enhance image contrast and detail reconstruction.
Subsequent sections will provide a detailed description of these modules, examining their functionality and contribution to the overall performance of the network.
Fig. 3
DecomposeNet. This proposed new hybrid network can utilize the skip connections of ResNet [14] and the cross-layer connections of U-Net [16] to minimize the information loss in the convolution process
Decomposition ModuleFirstly, guided by Retinex theory, the image is decomposed into components R and L through the decomposition network, where R retains the color and details of the image, and L captures the light intensity. Due to the absence of actual lighting guidance, it is challenging to design a constraint a priori that effectively separates the lighting and reflection components from the image. Fortunately, the dataset cited in [35], which contains paired images [\(I_\), \(I_\)] configured at different exposures, facilitates this process. Here, \(I_\) represents a low-light image, and \(I_\), a normal-light image.
As depicted in Fig. 3, the decomposition network leverages the extensive data within the dataset to drive learning and refine an optimal decomposition method. This method enables the network to accurately decompose image pairs under various illumination conditions, resulting in paired object reflection components [\(R_\), \(R_\)] and lighting components [\(L_\), \(L_\)]. In Retinex theory, the object reflection component is expected to remain constant across different illumination intensities, suggesting that \(R_\) and \(R_\) should be identical. However, in practice, the object reflection component exhibits varying degrees of degradation under different illumination intensities, with degradation intensifying as illumination decreases. Consequently, adjustments to the object reflection components aim to align them as closely as possible.
Fig. 4
DenseNet_R. This proposed network combines the powerful information extraction ability of DenseNet [15] and the cross-layer connection of U-Net [16] to capture image features for recovery
To enhance the training of the network, several loss functions are employed to ensure accurate image separation. In LIME [25], the light change constraint is derived by weighting the initial light map, determined by the maximum pixel values in the RGB channels. However, this method of weighting the light map does not perfectly adapt to changes in image brightness. Therefore, inspired by LIME, the maximum pixel values across the RGB channels are used as the light map. This single-channel light map is then combined with the low-light image along the channel dimension and fed into the decomposition network. The loss functions specified in Eqs. 1 and 2 ensure the structural correctness of the decomposition for both low-light and normal-light images according to Retinex theory, where \(\left\| \cdot \right\| \) signifies the mean absolute loss (L1 loss). Additionally, the loss functions in Eqs. 3, 4, and 5 are designed to ensure consistency in the object reflections.
Total variation minimization (TVM) is incorporated to impose smoothness constraints on the decomposition network. TVM is commonly utilized in image restoration tasks to minimize the overall image gradient. However, if applied directly as a loss function, it fails in areas with significant gradient variations, due to its assumption of uniform image gradients. To enhance the smoothness of the image post-decomposition, the TVM is modulated by the gradient of the object reflection component, as delineated in Eq. 6. Here, \(\nabla \) represents the image gradient, with horizontal and vertical components denoted by \(\nabla _h\) and \(\nabla _v\), respectively. The smoothing constraint coefficient, \(\lambda _g\), and the exponential weight \(\exp \left( -\lambda _ \nabla R_}\right) \) adjust the sensitivity of the smooth loss function in regions of abrupt gradient changes. The total loss function of the decomposition module is thus formulated.
$$\begin \mathcal _}= & \left\| R_ } \cdot L_ }-I_}\right\| _ \end$$
(1)
$$\begin \mathcal _}= & \left\| R_ } \cdot L_ }-I_}\right\| _ \end$$
(2)
$$\begin \mathcal _}= & \left\| R_ } -R_}\right\| _ \end$$
(3)
$$\begin \mathcal _}= & \left\| R_ } \cdot L_ }-I_}\right\| _ \end$$
(4)
$$\begin \mathcal _}= & \left\| R_ } \cdot L_ }-I_}\right\| _ \end$$
(5)
$$\begin \mathcal _ }= & \sum _\left\| \nabla L_ \circ \exp \left( -\lambda _ \nabla R_}\right) \right\| \end$$
(6)
$$\begin \mathcal _}= & \mathcal _}+\mathcal _}+0.01*\mathcal _}\nonumber \\ & +0.001*\mathcal _}+0.001\nonumber \\ & *\mathcal _} +\mathcal _ } \end$$
(7)
The decomposition module employs a novel hybrid network structure that integrates elements of ResNet and U-Net, as depicted in Fig. 3. This hybrid architecture leverages the skip connections from ResNet and the cross-layer connections from U-Net to minimize information loss during the convolution process. The network processes pairs of images, \(I_\) and \(I_\), as input. Initially, under the guidance of the loss function in Eq. 7, the network decomposes \(I_\) to obtain \(R_\) and \(L_\). Subsequently, using weight sharing, it decomposes \(I_\), yielding \(R_\) and \(L_\). Backpropagation is then performed by calculating the loss between the newly generated components (\(R_\), \(L_\), \(R_\), \(L_\)) and the original image pair (\(I_\), \(I_\)). To address feature loss during the image upsampling and subsampling processes, the decomposition network utilizes skip-layer connections within its architecture. Additionally, a channel attention mechanism is incorporated into the skip-layer connections between ResNet and U-Net, enhancing the network’s capacity to emphasize key features by weighting the channels of the convolutional outputs.
Fig. 5
ResNet_L. The light enhancement network learns the mapping between the low-light components and the normal-light components. This mapping can adjust the brightness of the light and adjust the low-light image to the normal-light level
Fig. 6
AdjustNet. The adjustment network is a typical combined network of the five-layer U-Net [15] and ResNet [14]. This adds a skip-layer connection method with a channel attention mechanism and combines the upsampling of nearest-neighbor interpolation and convolution
Enhancement ModuleIn the enhancement module, we use a DenseNet_R is used with excellent performance and a simple ResNet_L. These are employed to recover the degraded object reflection component and enhance the lighting component, respectively.
In DenseNet_R, the degradation intensity of the object reflection component varies with different illumination intensities. Consequently, the lighting component \(L_\) and the object reflection component \(R_\) from the low-light image are concatenated along the channel dimension and fed into the enhancement network. Governed by the L1 loss function as specified in Eq. 8, the enhancement network effectively learns the mapping between the object reflection components of the low-light and normal-light images.
The reflection component, initially obtained in the decomposition module, is input into the enhancement module to mitigate degradation. The enhancement module generates a new reflection component, denoted as \(R_\). This process not only restores the degraded reflection but also reduces noise compared to the original low-light reflection component. This mapping effectively eliminates the degradation caused by noise between the reflection component of the low-light object and that of the normal-light object. Furthermore, Eq. 9 ensures that the gradients’ changes in the reflected components of both objects are identical, implying that the boundary contours of the reflection components are aligned. Ultimately, the restoration network employs \(\mathcal =}\left( R}, R_}\right) \), where SSIM (\(\cdot \), \(\cdot \)) measures structural similarity. This metric confirms that the reflected components of both objects are structurally and perceptually similar. The loss associated with the recovery of the object reflection component is expressed in Eq. 10.
$$\begin \mathcal _}= & \left\| R_ }-R_\right\| _ \end$$
(8)
$$\begin \mathcal _}= & \left\| \nabla R_ }-\nabla R_ }\right\| _^ \end$$
(9)
$$\begin \mathcal _= & \mathcal _}+\mathcal _}+\mathcal _ \end$$
(10)
The network for object reflection component recovery is based on the combination of DenseNet and U-Net, as shown in Fig. 4. This proposed network combines the powerful information extraction ability of DenseNet and the cross-layer connection of U-Net to capture image features for recovery. In the DenseNet_R network, DenseNet is combined with UNet in the following way. The first layer is a Resnet_block that subsamples the input feature map. The second to the fifth layers are Dense_block blocks, which contains Conv_blocks. This network utilizes the powerful feature extraction capability of DenseNet and can obtain sufficient features in the subsampled process. At the same time, U-Net’s skip-layer connection is used to minimize the loss of features in the convolution process. Like the decomposition module, the channel attention mechanism is also added to the U-Net skip-layer connection. This can efficiently transfer effective information to the upsampling layers to ensure that the final generated image has excellent detail information and better visual perception.
Fig. 7
Visual comparison with low-light image enhancement methods on the LOL [35] Dataset
Fig. 8
Visual comparison with low-light image enhancement methods on the LOL [35] Dataset
As shown in Fig. 5. The ResNet_L network is a five-layer simple convolutional neural network. In order to effectively enhance the lighting component, the \(L_\) obtained by the decomposition module is enhanced under the constraint of the L1 loss function in Eq. 11. In other words, the light enhancement network learns the mapping between the low-light components and the normal-light components. This mapping can adjust the brightness of the light and adjust the low-light image to the normal-light level. \(L_\) represents the newly generated lighting component. Finally, the loss function in Eq. 12 is also used in this network to ensure that the gradient change of \(L_\) equals that of \(L_\). The loss of the light enhancement network can be expressed as Eq. 13.
$$\begin \mathcal _= & \left\| L_ }-L_ }\right\| _ \end$$
(11)
$$\begin \mathcal _= & \left\| \nabla L_ }-\nabla L_ }\right\| _^ \end$$
(12)
$$\begin \mathcal _= & \mathcal _}+\mathcal _} \end$$
(13)
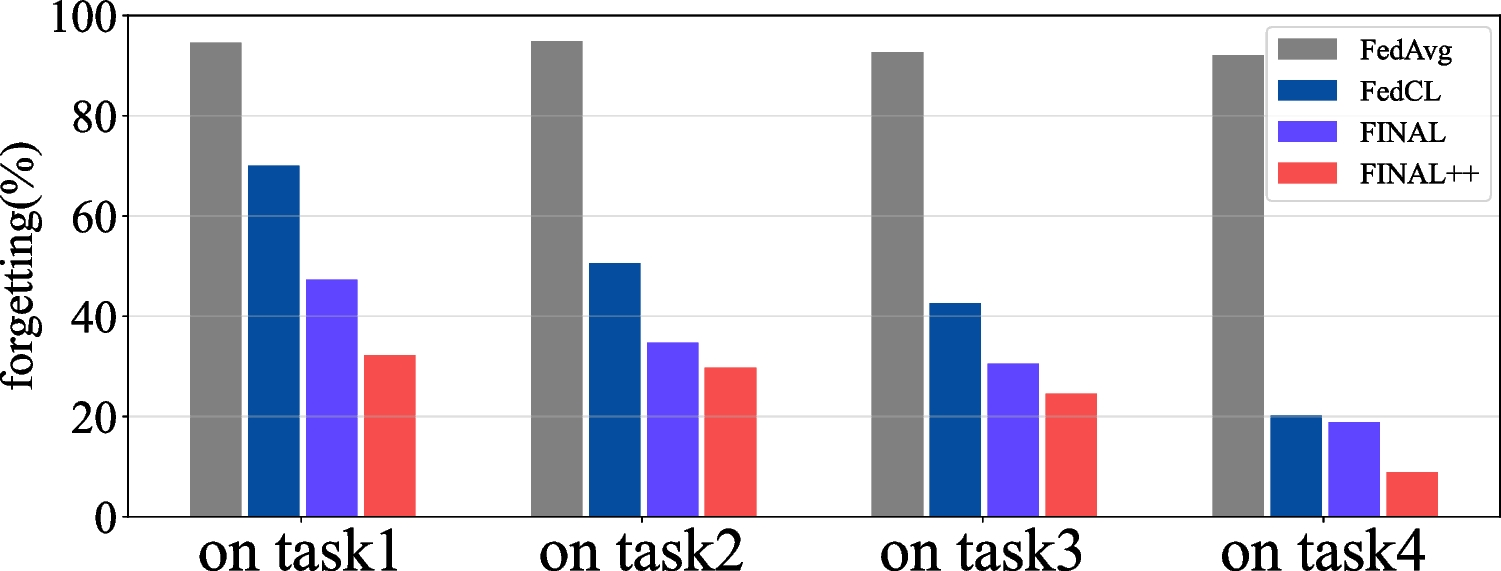
Table 1 Quantitative evaluation of low-light image enhancement methods on the LOL [35] datasetAdjustment ModuleIn the adjustment module, a network structurally similar to the decomposition module is proposed, which is primarily designed for the complex fusion of image features and the fine-tuning of image details and illumination intensity. Relying solely on \(I=R\circ L\) to merge the newly generated object reflection component \(R_\) and the new lighting component \(L_\) from the enhancement network is insufficient for achieving intricate feature fusion. Consequently, this paper introduces an adjustment network to address this shortfall. Moreover, the original input \(I_\) is reintegrated into the adjustment network to mitigate the feature loss encountered in the earlier decomposition and enhancement stages. This loss often results in diminished image details and color inaccuracies. Thus, reintegrating the original input into the final adjustment network helps refine details and preserve color fidelity. Additionally, a channel attention mechanism is incorporated into the U-Net’s skip connections within the adjustment network. This mechanism effectively reduces noise and mitigates low-light interference introduced by the original input, thereby enhancing the network’s capability to represent significant features.
Fig. 9
Visual comparison with other low-light image enhancement methods on LIME [25] and NPE [26] datasets
To ensure that the adjustment network accurately restores image features, a content loss function is incorporated, utilizing the pre-trained Visual Geometry Group (VGG) 19 network [60]. This network is employed to simultaneously extract feature pairs [\(Feature_\), \(Feature_\)] from the generated image and the normal-light image. The L1 loss, as defined in Eq. 14, is applied to these feature pairs to assure feature similarity. Here, \(Feature_\) denotes the features extracted from the image \(I_\) by the adjustment network, while \(Feature_\) refers to the features extracted from the normal-light image \(I_\).Additionally, the adjustment network implements the L1 loss constraint outlined in Eq. 15 between the generated image and the normal-light image pair [\(I_\), \(I_\)]. This constraint is crucial for ensuring the consistency of color reproduction in the generated image. The overall loss function of the adjustment network is defined in Eq. 16.
$$\begin \mathcal _}= & \Vert \text_}-\text_} \Vert _ \end$$
(14)
$$\begin \mathcal _ }= & \left\| I_ }-I_ }\right\| _ \end$$
(15)
$$\begin \mathcal _= & \mathcal _ }+\mathcal _ } \end$$
(16)
As depicted in Fig. 6, the adjustment network integrates a typical configuration of the five-layer U-Net and ResNet. This architecture incorporates a skip-layer connection strategy enhanced with a channel attention mechanism and employs both nearest-neighbor interpolation and convolution for upsampling. These techniques are strategically utilized to establish mappings that are critical for the restoration of image details and color accuracy.
Fig. 10
Detailed zoom-in comparison of different low-light enhancement methods on the LOL [35] dataset
Comments (0)