Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Lu, Polosukhin I. Attention is all you need. In: Advances in Neural Information Processing Systems. vol. 30 2017. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, et al. An image is worth 16x16 words: transformers for image recognition at scale. 2020. arXiv:2010.11929.
Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L. Imagenet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. 2009;248–255. https://doi.org/10.1109/CVPR.2009.5206848.
Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL. Microsoft coco: common objects in context. In: Fleet D, Pajdla T, Schiele B, Tuytelaars T. (eds.) Computer Vision – ECCV 2014. 2014;740–755. Springer, Cham.
Kafle K, Kanan C. An analysis of visual question answering algorithms. In: ICCV. 2017.
Hudson DA, Manning CD. GQA: a new dataset for real-world visual reasoning and compositional question answering. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR. 2019, Long Beach, CA, USA, June 16-20, 2019, 2019;6700–6709. https://doi.org/10.1109/CVPR.2019.00686 . http://openaccess.thecvf.com/content_CVPR_2019/html/Hudson_GQA_A_New_Dataset_for_Real-World_Visual_Reasoning_and_Compositional_CVPR_2019_paper.html.
Singh A, Natarajan V, Shah M, Jiang Y, Chen X, Batra D, Parikh D, Rohrbach M. Towards VQA models that can read. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019;8309–8318. https://doi.org/10.1109/CVPR.2019.00851.
Marino K, Rastegari M, Farhadi A, Mottaghi R. OK-VQA: a visual question answering benchmark requiring external knowledge. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019;3190–3199. https://doi.org/10.1109/CVPR.2019.00331.
Suhr A, Zhou S, Zhang A, Zhang I, Bai H, Artzi Y. A corpus for reasoning about natural language grounded in photographs. 2018. arXiv:1811.00491.
Xie N, Lai F, Doran D, Kadav A. Visual entailment: a novel task for fine-grained image understanding. 2019. arXiv:1901.06706.
Kayser M, Camburu O-M, Salewski L, Emde C, Do V, Akata Z, Lukasiewicz T. E-vil: a dataset and benchmark for natural language explanations in vision-language tasks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2021;1244–1254.
Kayser M, Camburu O-M, Salewski L, Emde C, Do V, Akata Z, Lukasiewicz T. E-vil: a dataset and benchmark for natural language explanations in vision-language tasks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021;1244–1254
Bagher Zadeh A, Liang PP, Poria S, Cambria E, Morency L-P. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018;2236–2246. Association for Computational Linguistics, Melbourne, Australia. https://doi.org/10.18653/v1/P18-1208 . https://aclanthology.org/P18-1208.
Chen Z, Wang P, Ma L, Wong K-YK, Wu Q. Cops-ref: a new dataset and task on compositional referring expression comprehension. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020;10086–10095
Yang S, Li G, Yu Y. Graph-structured referring expression reasoning in the wild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020;9952–9961.
Yu J, Wang Z, Vasudevan V, Yeung L, Seyedhosseini M, Wu Y. Coca: contrastive captioners are image-text foundation models. (2022).
Wang W, Bao H, Dong L, Bjorck J, Peng Z, Liu Q, Aggarwal K, Mohammed OK, Singhal S, Som S, Wei F. Image as a foreign language: BEiT pretraining for vision and vision-language tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (2023).
Du Z, Qian Y, Liu X, Ding M, Qiu J, Yang Z, Tang J. GLM: general language model pretraining with autoregressive blank infilling. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022;320–335.
Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M-A, Lacroix T, Rozière B, Goyal N, Hambro E, Azhar F, Rodriguez A, Joulin A, Grave E, Lample G. LLaMA: open and efficient foundation language models. 2023.
Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A, Agarwal S, Herbert-Voss A, Krueger G, Henighan T, Child R, Ramesh A, Ziegler DM, Wu J, Winter C, Hesse C, Chen M, Sigler E, Litwin M, Gray S, Chess B, Clark J, Berner C, McCandlish S, Radford A, Sutskever I, Amodei D. Language models are few-shot learners. 2020.
OpenAI: GPT-4 Technical Report. 2023.
Li J, Li D, Savarese S, Hoi S. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. 2023.
Zhu D, Chen J, Shen X, Li X, Elhoseiny M. Minigpt-4: enhancing vision-language understanding with advanced large language models. 2023. arXiv:2304.10592.
El Sayad I, Martinet J, Urruty T, Djeraba C. Toward a higher-level visual representation for content-based image retrieval. Multimed Tools Appl - MTA. 2010;60:1–28. https://doi.org/10.1007/s11042-010-0596-x.
Article
Google Scholar
Sadeghi MA, Farhadi A. Recognition using visual phrases In: CVPR. 2011;2011:1745–52. https://doi.org/10.1109/CVPR.2011.5995711.
Article
Google Scholar
Li LH, Yatskar M, Yin D, Hsieh C-J, Chang K-W. VisualBERT: a simple and performant baseline for vision and language. 2019.
Kim W, Son B, Kim I. Vilt: vision-and-language transformer without convolution or region supervision. In: Meila M, Zhang T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Research. 2021;139:5583–5594. http://proceedings.mlr.press/v139/kim21k.html.
Tan H, Bansal M. Lxmert: learning cross-modality encoder representations from transformers. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019.
Lu J, Batra D, Parikh D, Lee S. Vilbert: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Adv Neural Inf Process Syst. 2019;32.
Yu F, Tang J, Yin W, Sun Y, Tian H, Wu H, Wang H. Ernie-vil: knowledge enhanced vision-language representations through scene graphs. In: Proceedings of the AAAI Conference on Artificial Intelligence. 2021;35:3208–3216.
Chen Y-C, Li L, Yu L, El Kholy A, Ahmed F, Gan Z, Cheng Y, Liu J. Uniter: universal image-text representation learning. In: European Conference on Computer Vision. 2020;104–120. Springer.
Li X, Yin X, Li C, Zhang P, Hu X, Zhang L, Wang L, Hu H, Dong L, Wei F, et al. Oscar: object-semantics aligned pre-training for vision-language tasks. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16. 2020;121–137. Springer
Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J, Krueger G, Sutskever I. Learning transferable visual models from natural language supervision. 2021.
Wang P, Yang A, Men R, Lin J, Bai S, Li Z, Ma J, Zhou C, Zhou J, Yang H. OFA: unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. 2022. arXiv:2202.03052.
Du Z, Qian Y, Liu X, Ding M, Qiu J, Yang Z, Tang J. GLM: general language model pretraining with autoregressive blank infilling. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022;320–335. Association for Computational Linguistics, Dublin, Ireland. https://doi.org/10.18653/v1/2022.acl-long.26 . https://aclanthology.org/2022.acl-long.26.
Liu H, Li C, Li Y, Lee YJ. Improved baselines with visual instruction tuning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024;26296–26306.
Bai J, Bai S, Yang S, Wang S, Tan S, Wang P, Lin J, Zhou C, Zhou J. Qwen-vl: a versatile vision-language model for understanding, localization, text reading, and beyond. 2023. arXiv:2308.12966.
Gao P, Han J, Zhang R, Lin Z, Geng S, Zhou A, Zhang W, Lu P, He C, Yue X, Li H, Qiao Y. Llama-adapter v2: parameter-efficient visual instruction model. 2023. arXiv:2304.15010.
Awadalla A, Gao I, Gardner J, Hessel J, Hanafy Y, Zhu W, Marathe K, Bitton Y, Gadre S, Sagawa S, et al. Openflamingo: an open-source framework for training large autoregressive vision-language models. 2023. arXiv:2308.01390.
Zellers R, Bisk Y, Farhadi A, Choi Y. From recognition to cognition: visual commonsense reasoning. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019
Schwenk D, Khandelwal A, Clark C, Marino K, Mottaghi R. A-okvqa: a benchmark for visual question answering using world knowledge. arXiv. 2022.
Lu P, Mishra S, Xia T, Qiu L, Chang K.-W, Zhu S.-C, Tafjord O, Clark P, Kalyan A. Learn to explain: multimodal reasoning via thought chains for science question answering. In: The 36th Conference on Neural Information Processing Systems (NeurIPS). 2022.
Lerner P, Ferret O, Guinaudeau C, Le Borgne H, Besançon R, Moreno JG, Lovón Melgarejo J. ViQuAE, a dataset for knowledge-based visual question answering about named entities. In: Proceedings of The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. SIGIR’22. Association for Computing Machinery, New York, NY, USA. 2022. https://doi.org/10.1145/3477495.3531753 . https://hal.archives-ouvertes.fr/hal-03650618.
Feng J, Sun Q, Xu C, Zhao P, Yang Y, Tao C, Zhao D, Lin Q. MMDialog: a large-scale multi-turn dialogue dataset towards multi-modal open-domain conversation. 2022.
Ustalov D, Pavlichenko N, Likhobaba D, Smirnova A. WSDM Cup 2023 Challenge on visual question answering. In: Proceedings of the 4th Crowd Science Workshop on Collaboration of Humans and Learning Algorithms for Data Labeling, Singapore. 2023;1–7. http://ceur-ws.org/Vol-3357/invited1.pdf.
Liu F, Emerson G, Collier N. Visual spatial reasoning. Trans Assoc Computat Linguist. 2023;11:635–51.
Article
Google Scholar
Parcalabescu L, Cafagna M, Muradjan L, Frank A, Calixto I, Gatt A. VALSE: a task-independent benchmark for vision and language models centered on linguistic phenomena. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022;8253–8280. Association for Computational Linguistics, Dublin, Ireland. https://doi.org/10.18653/v1/2022.acl-long.567 . https://aclanthology.org/2022.acl-long.567.
Manjunatha V, Saini N, Davis L. Explicit bias discovery in visual question answering models. 2019;9554–9563. https://doi.org/10.1109/CVPR.2019.00979.
Niu Y, Tang K, Zhang H, Lu Z, Hua X-S, Wen J-R. Counterfactual VQA: a cause-effect look at language bias. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
Si Q, Meng F, Zheng M, Lin Z, Liu Y, Fu P, Cao Y, Wang W, Zhou J. Language prior is not the only shortcut: a benchmark for shortcut learning in VQA. In: Findings of the Association for Computational Linguistics: EMNLP 2022, 2022;3698–3712. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates. https://aclanthology.org/2022.findings-emnlp.271
Lu C, Krishna R, Bernstein M, Fei-Fei L. Visual relationship detection with language priors. In: European Conference on Computer Vision. 2016.
Zhu Y, Groth O, Bernstein M, Fei-Fei L. Visual7W: grounded question answering in images. In: IEEE Conference on Computer Vision and Pattern Recognition. 2016.
Kuznetsova A, Rom H, Alldrin N, Uijlings J, Krasin I, Pont-Tuset J, Kamali S, Popov S, Malloci M, Kolesnikov A, Duerig T, Ferrari V. The open images dataset v4: unified image classification, object detection, and visual relationship detection at scale. Int J Comput Vision. 2020;128. https://doi.org/10.1007/s11263-020-01316-z.
Xu D, Zhu Y, Choy C, Fei-Fei L. Scene graph generation by iterative message passing. In: Computer Vision and Pattern Recognition (CVPR). 2017.
Liang Y, Bai Y, Zhang W, Qian X, Zhu L, Mei T. VRR-VG: refocusing visually-relevant relationships. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 10402–10411. IEEE Computer Society, Los Alamitos, CA, USA 2019. https://doi.org/10.1109/ICCV.2019.01050 . https://doi.ieeecomputersociety.org/10.1109/ICCV.2019.01050.
Kuznetsova A, Rom H, Alldrin N, Uijlings J, Krasin I, Pont-Tuset J, Kamali S, Popov S, Malloci M, Kolesnikov A, Duerig T, Ferrari V. The open images dataset v4: unified image classification, object detection, and visual relationship detection at scale. IJCV. 2020.
Fu C, Chen P, Shen Y, Qin Y, Zhang M, Lin X, Qiu Z, Lin W, Yang J, Zheng X, et al.: MME: a comprehensive evaluation benchmark for multimodal large language models. 2023. arXiv:2306.13394.
Miller GA. Wordnet: a lexical database for english. Commun ACM. 1995;38(11):39–41. https://doi.org/10.1145/219717.219748.
Article
Google Scholar

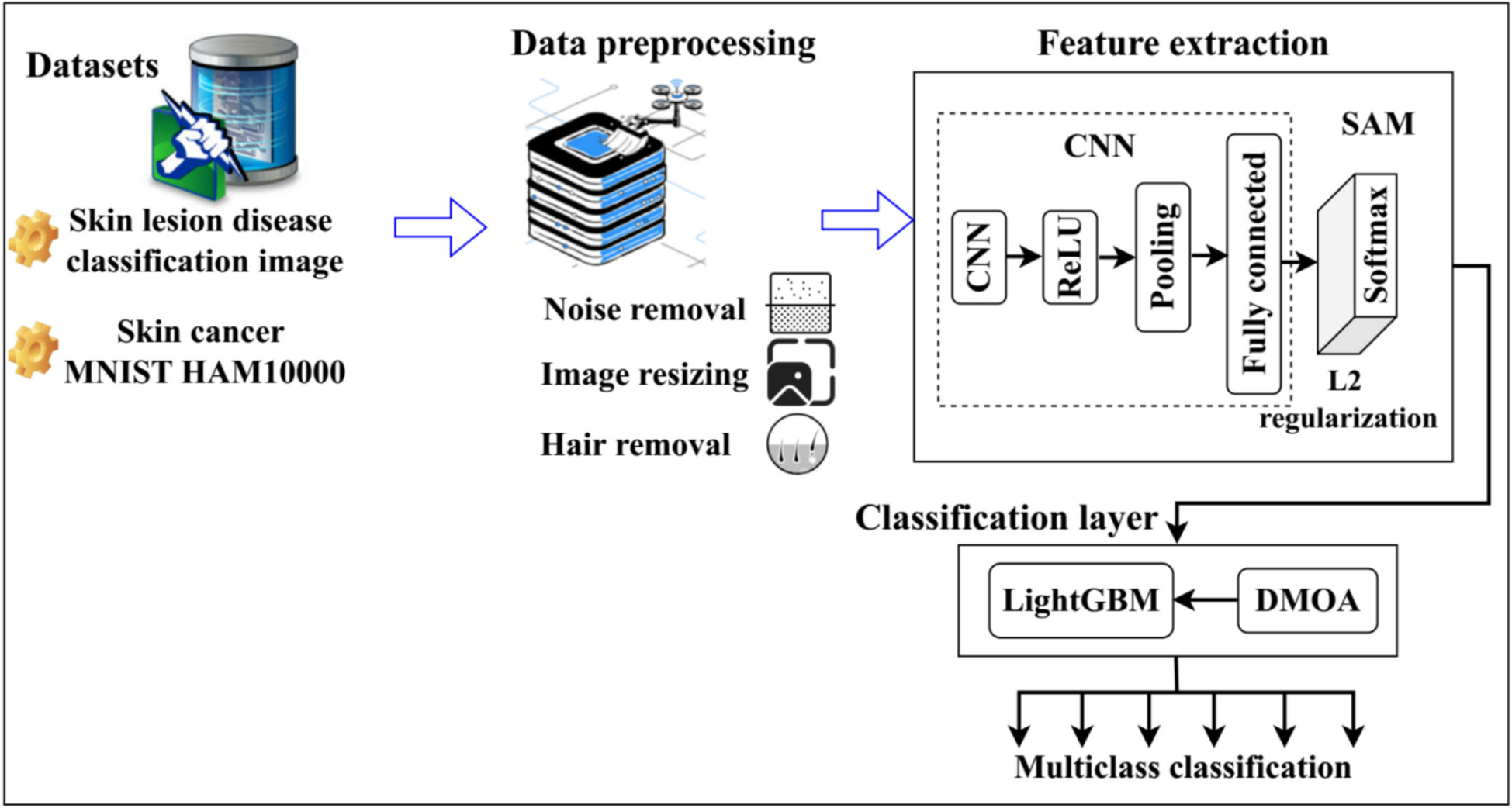
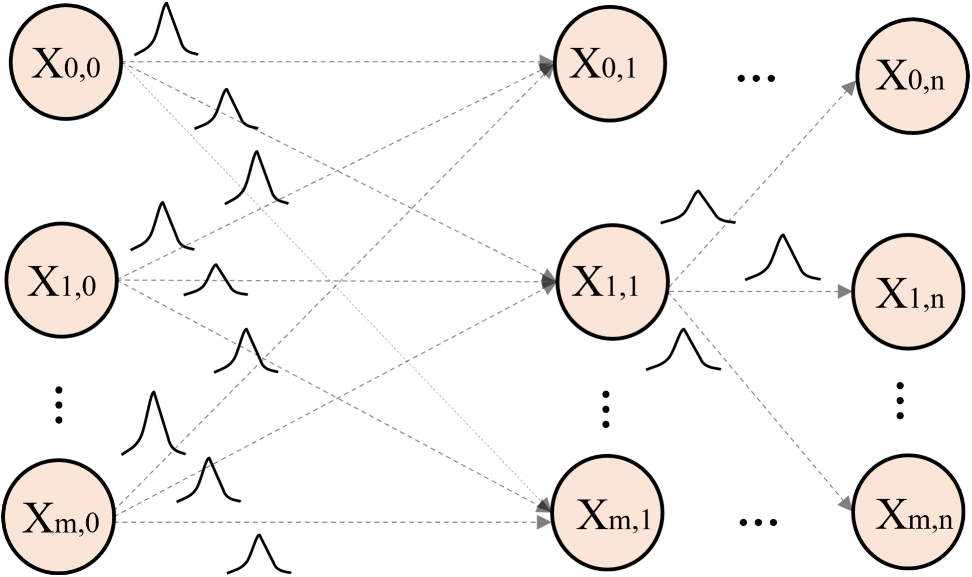
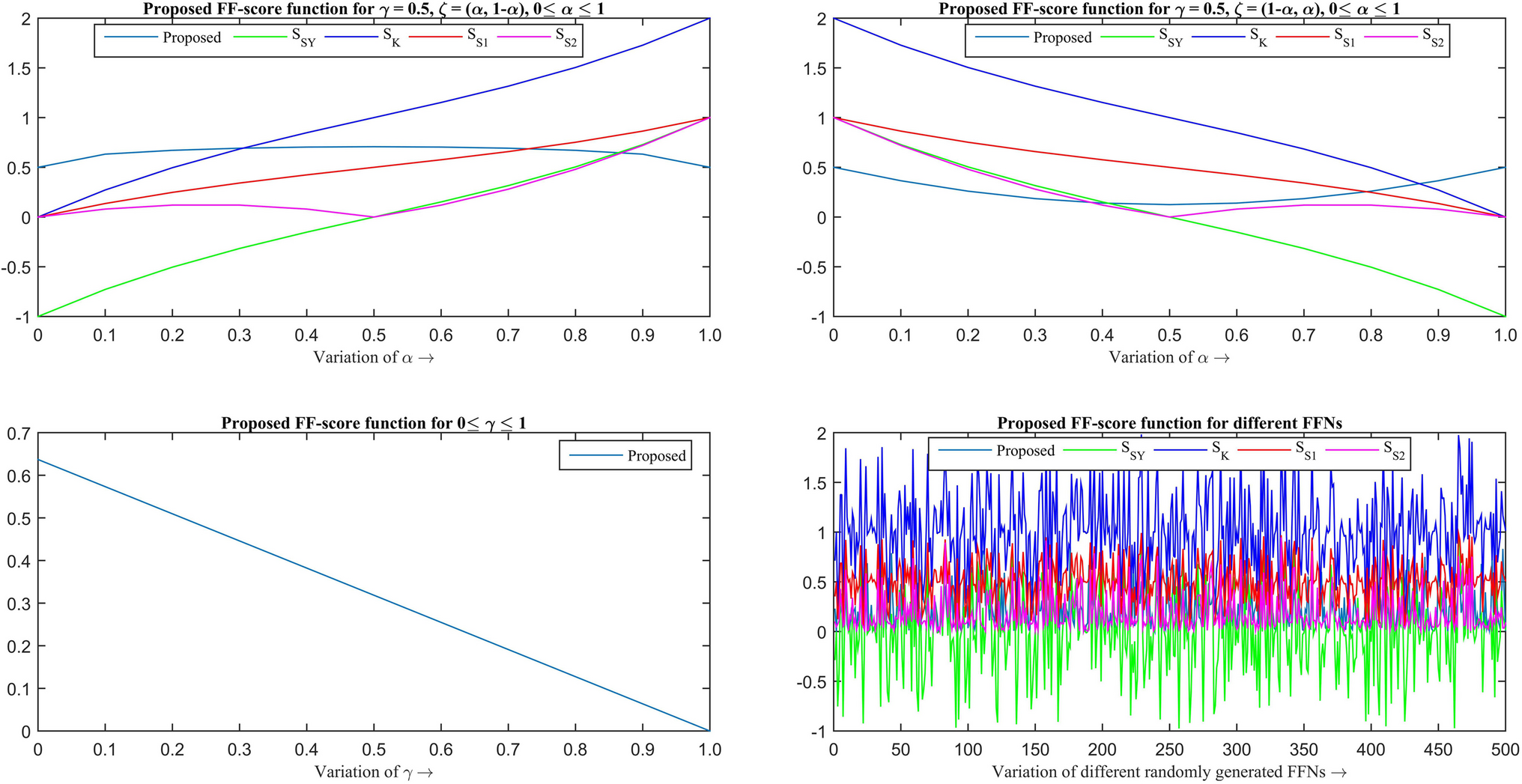
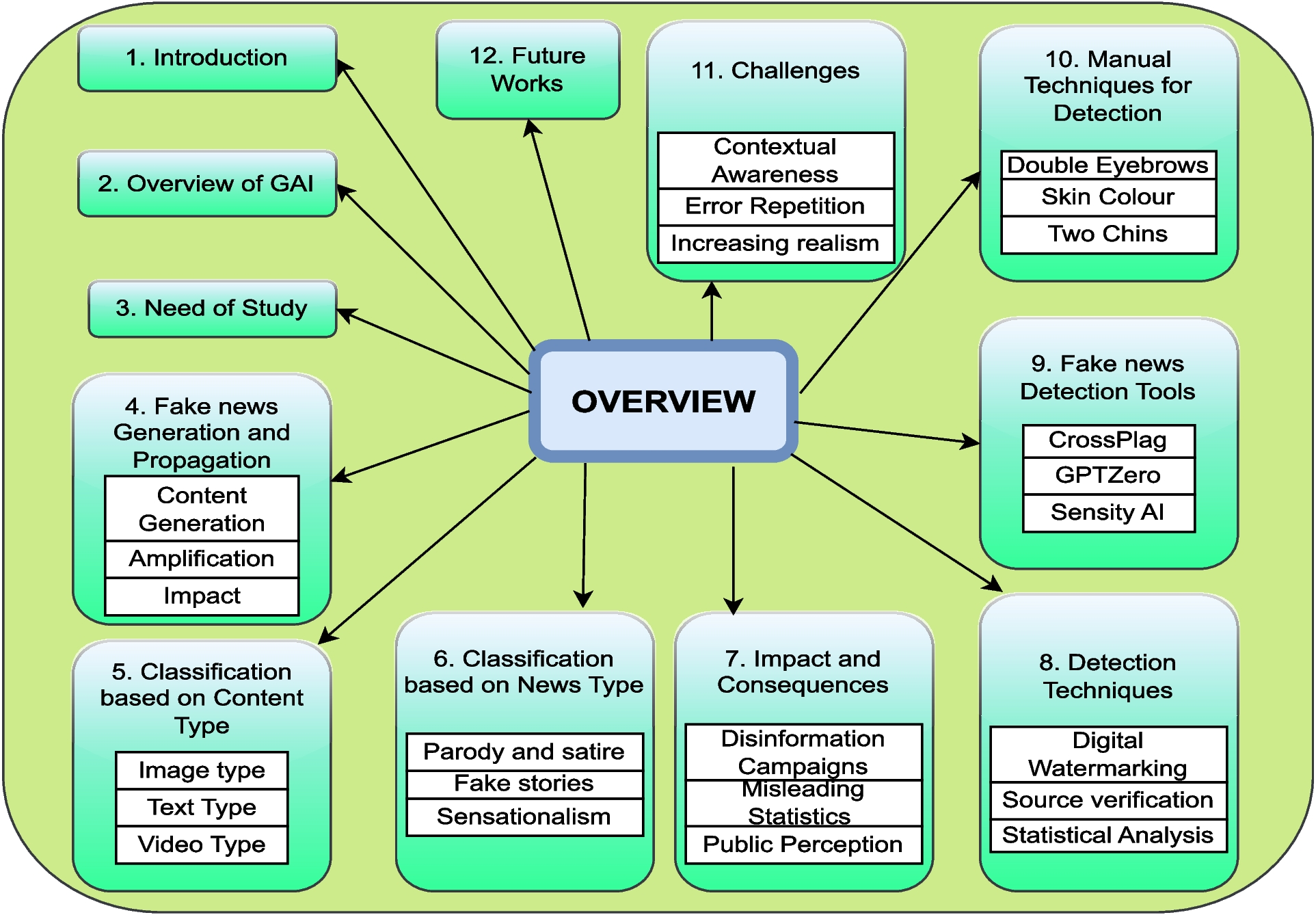

Comments (0)