


記住我




Due to the scarcity, difficulty in acquisition, and high cost of labeling of air traffic control (ATC) speech data in various control scenarios, ATC speech recognition models are prone to data sample bias and class imbalance issues during model training, directly affecting the recognition accuracy of speech recognition models. This situation may further lead to incorrect aircraft control decisions made by other ATC systems that rely on recognizing text as input, posing significant flight safety risks and potential hazards.
To address these issues, this study delves into data quality and constructs a comprehensive data ecosystem (Downs et al., 2021). By using a quantitative approach to quantify accents, the quality of speech data is calibrated. Subsequently, different strategies for combining data quality categories are selected according to the requirements of different model application scenarios, ensuring that the trained speech recognition models achieve optimal recognition accuracy. This initiative plays a crucial foundational role in advancing the integration, application, and decision-making of civil aviation intelligence, and is expected to promote the civil aviation air traffic management intelligence to a higher level.
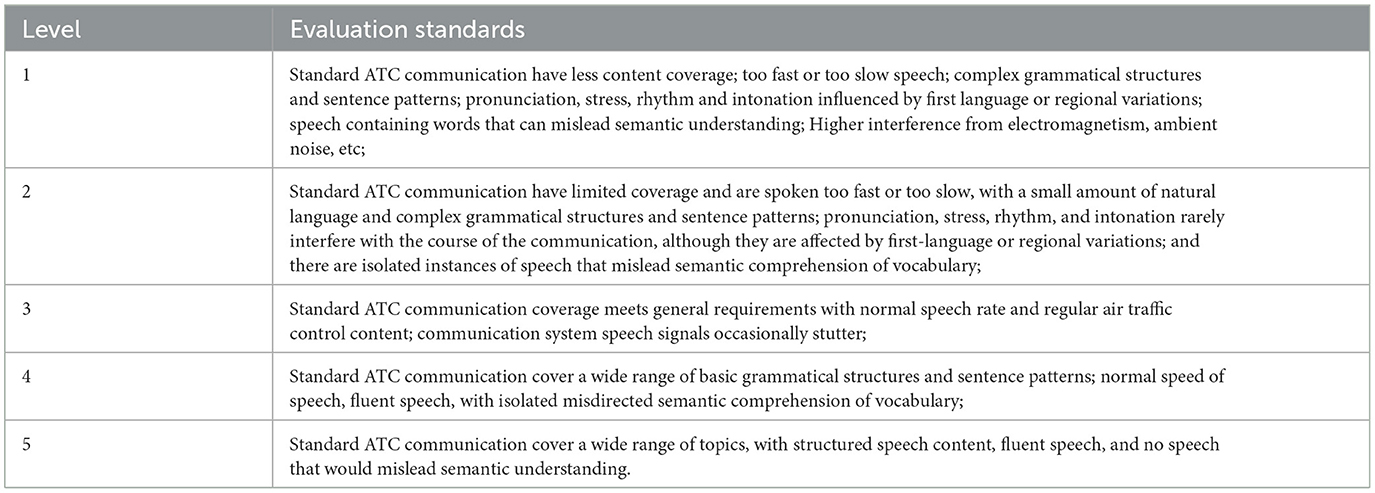
As is well-known, deep learning models are inherently sensitive to data distribution due to their nature of self-supervised learning (Pan et al., 2023). However, dealing with incomplete instances is a common phenomenon when processing real-world datasets (Liu and Letchmunan, 2024). Typically, to ensure the completeness of data collection, methods such as fuzzy clustering, interpolation, multisensory information fusion, and similarity measurement are employed during data preprocessing to fill in missing data and improve the performance of machine learning (Choudhury and Pal, 2022; Liu, 2023, 2024). However, in some special fields, simulating missing data can become exceptionally cumbersome, or the supplemented missing data may differ significantly from real data. Therefore, the approach adopted in this paper is to fully leverage the value of the collected real data and deeply explore its data worth, avoiding the complexity of simulating missing data while ensuring the authenticity of the entire dataset and avoiding the use of synthetic data. Currently, there are two main methods for speech quality assessment. One is non-intrusive black-box models, such as Mean Opinion Score (MOS) (International Telecommunication Union, 1996), which are artificial fuzzy speech quality evaluation methods. According to the International Civil Aviation Organization (ICAO) English Language Proficiency Standard (ICAO Annex 1, Personnel Licensing), the MOS evaluation specification for ATC speech quality is shown in Table 1, which classifies the ATC speech quality into levels 1 to 5. Level 5 is the best quality. Although they can assess speech quality, they cannot deeply understand the internal logic of speech quality evaluation within the model. Another method is to use the Perceptual Evaluation of Speech Quality (PESQ) algorithm (International Telecommunication Union, 2001), but it requires standard pronunciation samples as references, making it difficult to deploy and unsuitable for complex and variable scenarios.
Table 1. The MOS evaluation specification for ATC speech quality (Levels 1–5, Level 5 is the best quality).
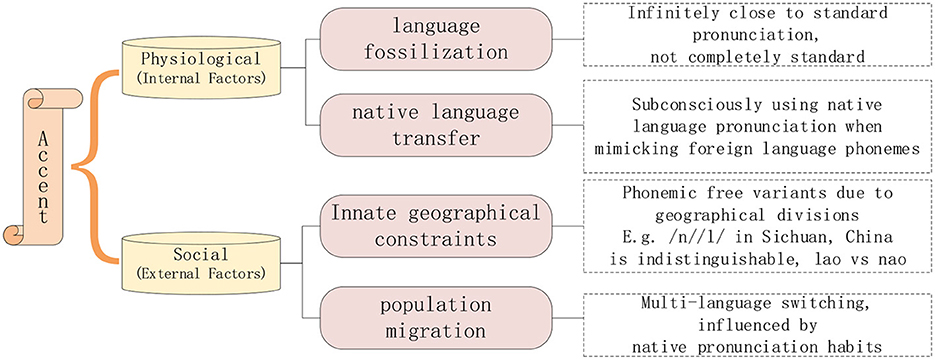
1.1 Background of the proposed ATC speech accent evaluation metricThe differences between ATC speech and everyday conversation speech lie in their rapid pace, unique pronunciation rules, complex noise background, and the phenomenon of multilingual switching and accents. In the actual air traffic control communication process, although the ICAO in the “Manual on the Implementation of ICAO Language Proficiency Requirements” (International Civil Aviation Organization, 2009) stipulates that civil aviation frontline workers must have a language proficiency of at least level four. That is, they must maintain a standard pronunciation while working, which does not affect the understanding of semantic content. However, everyone has an accent, and the reason for the accent is shown in Figure 1, which is only avoided in the frontline work of civil aviation, so the degree of accent is slightly weak, called “micro-accent phenomenon”.
Figure 1. Causes of the micro-accent phenomenon.
As shown in the Table 2, accents may lead to distortion of speech signals, making it difficult for conventional speech recognition models to accurately match accent variants, involving multiple aspects such as acoustic models, language models, and encoder-decoders, thereby affecting the performance of speech recognition models. The ATC speech recognition model is required as an intelligent application to assist in improving efficiency in intelligent civil aviation. Although it wants to try its best to mimic the human mind to achieve a specific intelligent task, it is still essentially a class of machine learning models, and their recognition accuracy in practice may be affected if the various accents and speech variants are not covered in their previous cognitive learning. Because of this, the preprocessing of speech data quality assessment in speech recognition models is very important, making full use of the existing historical data to evaluate the data quality, so that the training and testing sets of speech recognition models are distributed evenly, and the various accents and speech variants are covered extremely well, so as to improve the recognition performance of the models.
Table 2. The impact of accents on different speech recognition models.
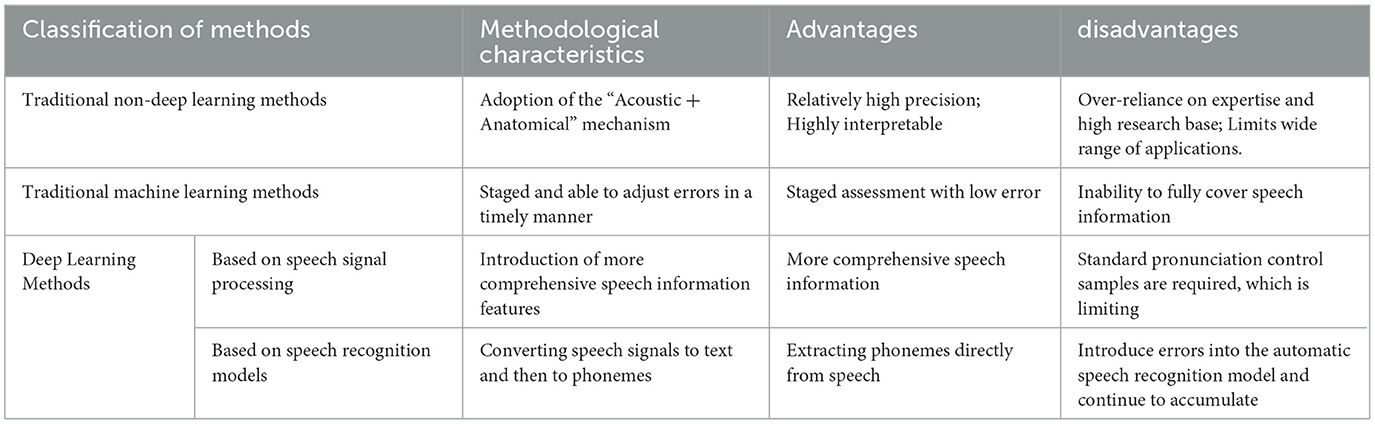
1.2 Related workATC speech accent assessment, essentially accent pronunciation segment perception, detects the phonemes in the speaker's speech, and compares the detected speech phonemes with the phoneme sequences transcribed from the speech text. If the comparison results are consistent, the pronunciation is standard; if they are not, an accent is present. As shown in Table 3, the methods for evaluating speech quality are evolving from traditional techniques to deep learning, with continuous refinement and improvement. In earlier phoneme detection methods, scholars used an “acoustic + anatomical” mechanism to map the target phonemes to corresponding phonetic features in speech. This involves assessing the size/shape of the resonator and considering whether there are obstacles to articulation, and ultimately identifying specific phonemes (Tepperman and Narayanan, 2008). Although this method is relatively high in accuracy, it is overly dependent on the expertise reserves of domain experts, and the research base is too high, which limits its wide application. With the development of machine learning and deep learning technology, a series of mutually integrated and optimized Goodness of Pronunciation (GOP) models based on Hidden Markov Model (HMM) and Gaussian Mixture Model (GMM) have come into view (Witt, 2000; Kanters et al., 2009; Sudhakara et al., 2019). These models are usually structured in two parts, the first phase is acoustic feature extraction as input to the algorithm, the second phase is the calculation of the probability of occurrence of each phoneme in each time frame (i.e., a posteriori probability) on a given sequence of acoustic feature observations, and the likelihood of comparing the sequence of phonemes from a real text transcription with the posterior probability as an assessment of the goodness of pronunciation (Huang et al., 2017). However, most of the improved models of such methods focus on the optimization of the a posteriori probability calculation method in the second stage, which has great limitations and only focuses on the processing of speech acoustic features, which cannot cover the comprehensive information of speech well, and will miss the important speech information such as frequency, intonation, and rhythm of speech. As the development of deep learning models becomes more and more mature, people begin to introduce more comprehensive speech information features, such as Mel-frequency cepstral coefficient (MFCC) and filter bank cepstral coefficient (FBANK). The PESQ algorithm is used to compare the difference between the speech signal and the reference speech signal to make an objective evaluation of speech quality (Lee and Glass, 2012; Lee et al., 2013, 2016), but the algorithm requires standard pronunciation samples as a control, which leads to limitations in land and air call recognition. It is only suitable for the evaluation of speech pronunciation quality with fixed text content, and it is more difficult to be deployed for the complex and changing control scenarios and the unfixed text content of control instructions in air traffic control. In addition, there are researchers who indirectly identify phonemes with the help of speech recognition models by recognizing speech signals as text, and text is converted into corresponding phonemes (Chan et al., 2015; Chorowski et al., 2015; Watanabe et al., 2017), but this approach may introduce the continuous accumulation of errors in the automatic speech recognition (ASR) model, which affects the correctness and reliability.
Table 3. Evolution of speech quality evaluate methods: from traditional to deep learning.
Therefore, this paper integrates the multiple advantages of the above methods and establishes a phoneme recognition model based on the fusion of speech and sentence a priori textual features by using the mutual integration of deep neural networks and information theory. The introduction of contextual context and attention mechanism makes it possible to capture speech information more comprehensively, thus improving the accuracy of the phoneme recognition model. The main purpose of this paper is to propose an objective quantitative metric for analyzing the quality of ATC speech—accent. The aim is to elucidate whether ATC speech classified according to this metric has an impact on the performance of speech recognition models and the relationship between the interactions.
1.3 Structure of the paperThis paper is divided into five parts: the first chapter describes the background, reasons, and relevant arguments for using “accent” as an evaluation metric for ATC speech quality. In this way, it explains the necessity of accent evaluation and analyses and summarizes the research methods used and challenges faced by other experts and scholars. In Chapter 2, the technical methodology and model used to adopt 'accent' as an evaluation metric of ATC speech quality are described. Chapter 3 details the experimental processes and results. In Chapter 4, the ATC speech data evaluated based on the above evaluation methods will be applied to the speech recognition model, using correlation coefficients and comparison experiments to verify the validity of the effect of different ATC speech accent levels on the recognition results. Chapter 5 summarizes the main contents of the whole paper and explains the application value and significance of the research results.
2 Technical methods and modeling 2.1 Technical route analysisIn this paper, we are inspired by the Computer Assisted Pronunciation Training (CAPT) research method (Feng et al., 2020), which adopts the training method of one speech corresponding to multiple texts, and locates the mispronounced pronunciation segments by introducing multiple different texts corresponding to the same speech. While the purpose of this study is to detect the presence of accents, which also belongs to a kind of pronunciation error, but unlike the CAPT method it is difficult to artificially annotate the sequence of ATC speech phonemes, and the experimental conditions we already have can only be to annotate the correct text it corresponds to. Therefore, we adopt the training method of multiple speech corresponding to one text, so that one text corresponds to multiple different speech, so that the model can be better generalized to the pronunciation characteristics of ATC speech, and improve the accuracy of the prediction of the phoneme recognition model.
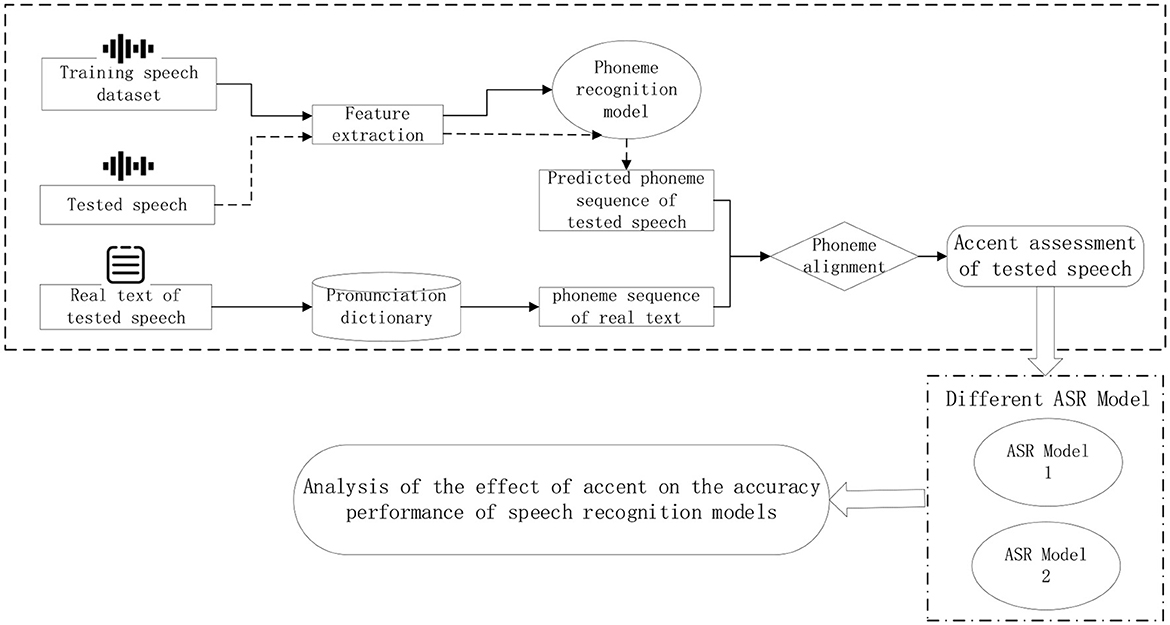
Therefore, the technical route designed in this paper is shown in Figure 2, which uses a publicly available standard acoustic-phoneme database defaulting to its non-accented dataset, to build a standard speech phoneme database and use it as a training set, and secondly, the training set and incorporate a certain amount of ATC speech data, so as to make the model adapt to the pronunciation characteristics of ATC. The phoneme recognition model is trained using the assembled pronunciation data, and different speech features are mapped to the corresponding phonemes. The speech to be tested is passed through the trained phoneme recognition model to predict the sequence of phonemes contained in the speech to be tested, and then this sequence is compared with the sequence of phonemes corresponding to the correct text transcribed from the speech to be tested. If an accent is present in the speech to be tested, the model may recognize the speech segment as other phoneme variants. Therefore, the recognized phoneme sequences are compared with the phoneme sequences transcribed from the speech text, and where there are differences, it is assumed that an accent fragment is present.
Figure 2. Overall research ideas and technical routes.
2.2 Model architectureThe overall architecture of the model consists of an audio coding module, a priori text coding module, a feature fusion module, and a full connectivity layer, as shown in Figure 3. The input of the model is the speech and the corresponding a priori text, and the output is the phoneme sequence of the speech.
Figure 3. Structure of the phoneme recognition model.
The total number of frames of the whole speech is T, the speech feature vector X = [x1;x2;...;xt;...;xT], where xt represents the feature vector of the speech at the t-th frame. The audio encoding module consists of two two-dimensional (2D) convolutional layers and four bidirectional long short-term memory (Bi-LSTM) layers. Batch normalization is applied to the input of each bidirectional LSTM to mitigate the vanishing gradient problem, accelerate convergence, and enhance the model's robustness. The specific formula for batch normalization is shown in Equation (1).
x^k(t) = xk(t) - E[xk]Var[xk] (1)xk(t) represents the observed value of the k-th dimension of the t-th frame's speech feature vector. x^k(t) represents observations after batch normalization. E[xk] is the mean of the eigenvalues of all samples in the current batch on that dimension. Var[xk] is the variance of the eigenvalues of all samples in the current batch on that dimension.
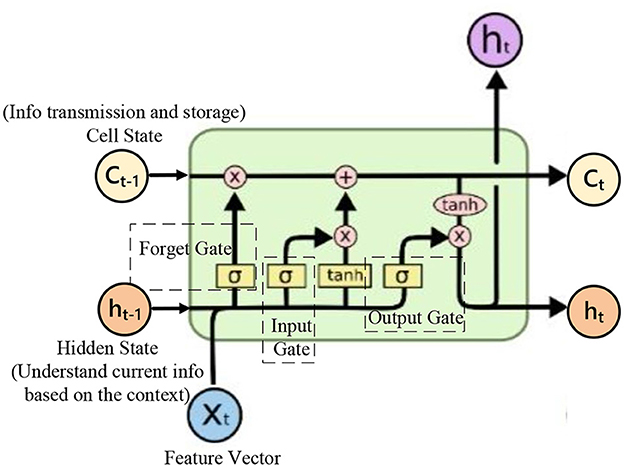
Speech data possesses strong temporal characteristics and rich time-frequency information. Introducing Bi-LSTM into the audio encoding module allows for comprehensive coverage of speech information. As shown in Figure 4, it illustrates a diagram of an LSTM structure. Bi-LSTM propagates information in both forward and backward directions, considering past and future information simultaneously, resulting in more accurate feature extraction of audio data. Bi-LSTM utilizes internal gating mechanisms to finely control the flow of information. The role of the forget gate is to enable the network to maintain appropriate memory between different speech segments, facilitating a better understanding of long-term speech patterns. Meanwhile, the input gate is responsible for dynamically incorporating new input information and updating the cell state. These intricate designs enhance Bi-LSTM's performance in modeling temporal information. The input speech features are passed through the audio coding module to obtain the output feature sequence denoted as Encoder Query, which is subsequently used for the computation of the attention vector and the feature fusion operation. The calculation of Encoder Query is shown in Equation (2).
Encoder Query = CNN-RNN(X) (2)Figure 4. A diagram of an LSTM structure.
The a priori text encoder corresponding to speech uses the Bidirectional Encoder Representations from Transformers (BERT) model, which is a bidirectional Transformer encoder capable of efficiently extracting features of the input text from both directions. The text encoder input is the sequence P = [p1, ..., pn, ..., pN] of phonemes corresponding to the a priori text, pn is the phoneme at the n-th position, and the length of the phoneme sequence is N.
The output sequence features of the phoneme sequence P after BERT coding are used as sequence K and sequence V, respectively, where K=V, and are input to Mlti−attention together with Encoder Query. The purpose of the multi-head attention mechanism calculation is to assist the training of the audio coding module to accelerate the alignment and improve the accuracy, which is shown in Equations (3)–(5).
attention(Q,K,V) = softmax(QKTdK)V (3) Multi-Head(Q,K,V) = concat(head1,head2,…,headh)W0 (4) headi = attention(QWiQ,KWiK,VWiV) (5)The features produced by each attention head are weighted and summed to form a new feature vector, denoted as context vector. The previous acoustic features are used to make acoustic residuals to reduce the model error. A beam search is performed to predict the phoneme sequence P′=[p1′,...,pn′,...,pN′]. The results predicted for each frame phoneme are shown in Equation (6).
pt ′ = softmax(W(contextvector⊕Q)+b) (6)In this equation, ⊕ represents the concatenation of two vectors, and pt ′ represents the predicted phoneme for the t-th frame.
3 Experimental results and validation 3.1 ATC Speech data collectionThis experiment focuses on evaluating the degree of accent in ATC speech, and observing and measuring the effect of ATC speech with different degrees of accent on the recognition accuracy performance of speech recognition models. According to a research study (Jahchan et al., 2021), multi-language inter-switching tends to produce more pronounced accents than geographic switching, and individual languages have their own pronunciation habits. For example, civil aviation pilots in various countries are generally familiar with the English pronunciation of the destination country in advance before executing international flights, so that they can quickly make corresponding feedback in the first time after receiving the speech control instructions to ensure the absolute safety of aviation operations (Romero-Rivas et al., 2015).
Therefore, the dataset used for model pre-training consists of the TIMIT database (Garofolo, 1993), which is an acoustic-phoneme continuous speech corpus created by Texas Instruments and Massachusetts Institute of Technology. The TIMIT dataset has a speech sampling frequency of 16 kHz and contains a total of 6,300 sentences, all of which are manually segmented and labeled at the phone level. This paper focuses on accents caused by multilingual switching in different national contexts, so the TIMIT dataset, with its distinctive feature of phone level labeling for each speech sample, is ideal for setting up a standard pronunciation database.
To ensure the professionalism of the data, our study covers 20,000 pieces of ATC speech data, of which 15,000 are from the first-line approach control recordings of the East China Air Traffic Control Bureau of the Civil Aviation Administration of China (CAAC), and the other 5,000 are from the recordings on the control simulators, with a total length of about 30 h. The 5,000 on-simulator recordings were collected for the purpose of model training for the adaptation of pronunciation characteristics of ATC speech, so we purposely looked for experienced controllers to avoid accents when collecting this part of the data. Notably, we use these 5,000 control simulator recordings as the standard pronunciation to ensure high accuracy of the trained speech model. Finally, a batch of the first-line approach control recordings was selected from the dataset for phoneme sequence recognition by the phoneme recognition model, so as to calculate the degree of accent of the speech data. In the experiments, the speech data were classified into different accent levels according to the distribution of the accent degree of the speech data. In addition, in order to observe the influence of different ATC speech accent degrees on the correct rate of speech recognition model recognition, this paper also adds two speech recognition models for comparative verification experiments (PPASR ASR model and Wishper ASR model, respectively), and the two speech recognition models used still pick the same ATC speech data from them for fine-tuning training, and then analyze the relationship between the influence of ATC speech accents on the recognition accuracy of speech recognition model performance.
The experiments were conducted on a Linux operating system with the following computer configuration: an Intel Core i5-8400 processor, 56G of running memory, an NVIDIA RTX4090 24G graphics card, a 250 GB solid-state drive, and a 3.6 TB hard disk drive Speech feature extraction was performed using the Kaldi toolkit (Povey et al., 2011) to extract high-quality acoustic features from the raw speech signal for the flow of information between modules in the subsequent model.
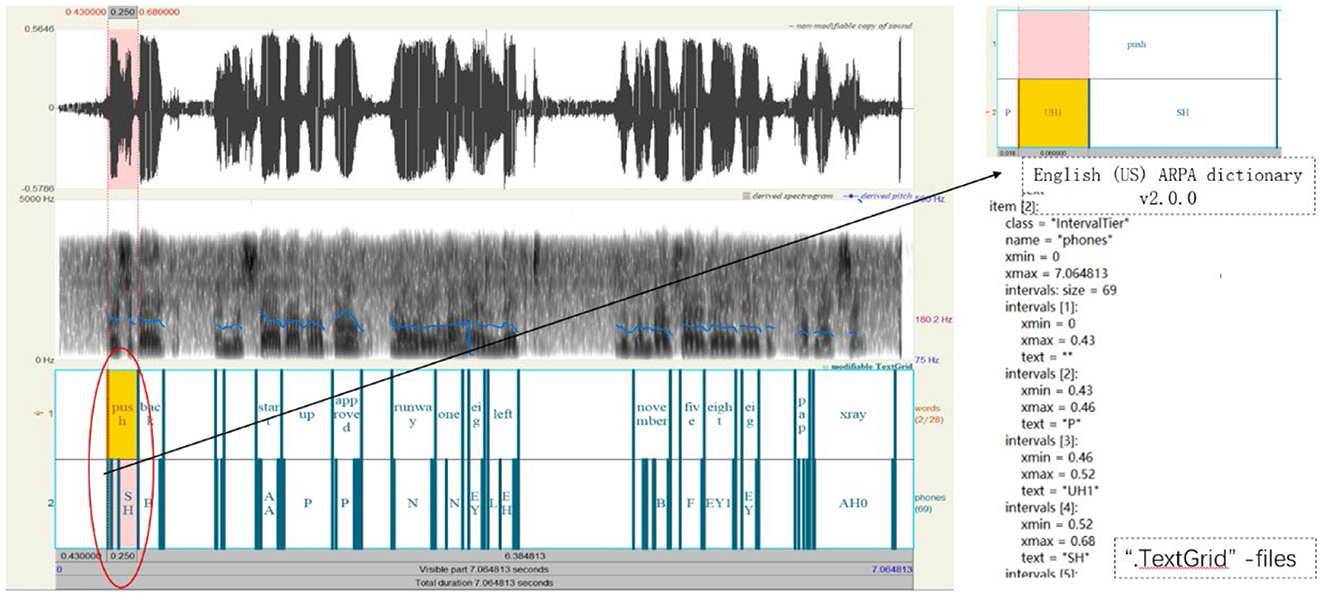
3.2 Speech data preprocessingThe Montreal Forced Aligner (MFA) phoneme alignment toolkit (McAuliffe et al., 2017) is used to align the speech segments in speech data with their corresponding text, generating “.TextGrid” files. These files contain time markers at the phoneme level and provide information about their positions within the speech. Additionally, the aligning results can be visualized using Praat software (Styler, 2013), as shown in Figure 5, facilitating subsequent speech processing tasks.
Figure 5. Data preprocessing process diagram (Control instructions: push back and start up ap-proved runway one eight left NOVEMBER five eight eight PAPA XRAY).
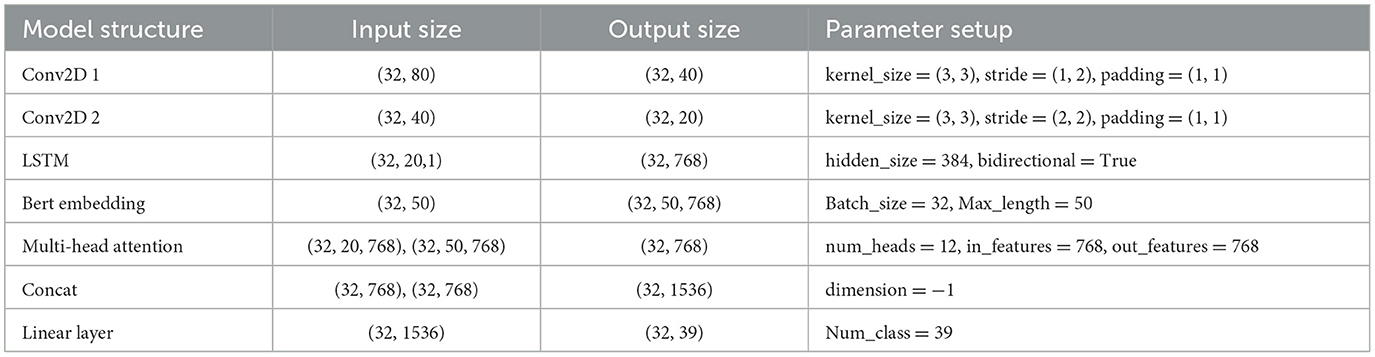
3.3 Phoneme recognition model training resultsThe details of the architecture are shown in Table 4. The phoneme sequence prediction (decoding) performance is evaluated using the decoder.wer() function, which calculates the word error rate (WER_Phoneme_ASR) between the output of the phoneme recognition system and the real text phoneme sequence, as shown in Equation (7). That is, how many insertion, deletion and substitution operations need to be performed to convert the phoneme sequence output by the model to the original text phoneme sequence. The lower the value of _Phoneme_ASR, the better it is, indicating the better phoneme sequence recognition performance of the model.
WER_Phoneme_ASR = S+D+IN (7)Table 4. Details of architecture.
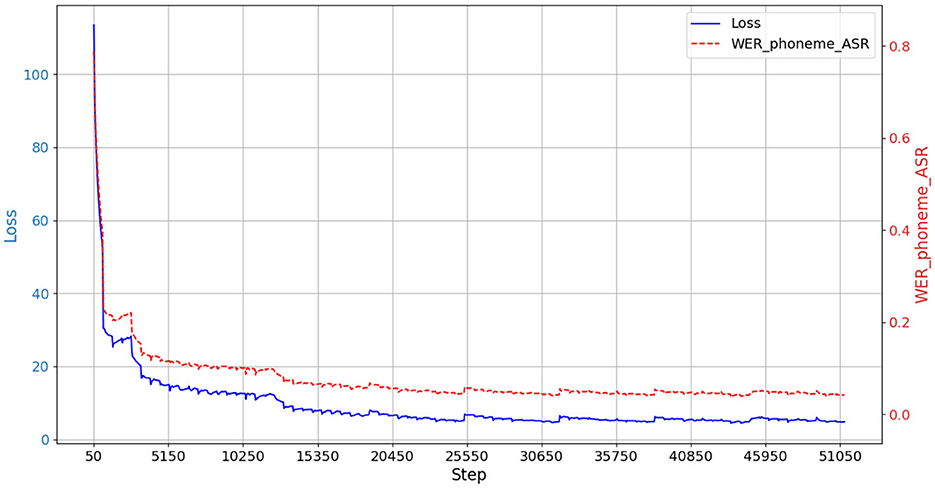
Where S denotes the number of substitutions, D denotes the number of deletions, I denotes the number of insertions, and N denotes the number of real text phoneme sequences. After testing of the model, according to the statistical analysis results the phoneme recognition error rate (WER_Phoneme_ASR) of the model is 15.65%. The model training process is shown in Figure 6. In Figure 6, the vertical axes reflect the strengths and weaknesses of the model performance. The left and right vertical axes are mainly different in the unit of measurement, and the Loss value is a continuous, scalar value that measures the difference between the model's predicted value and the true value. A smaller Loss value indicates better model performance. WER_Phoneme_ASR is a discrete percentage indicating the percentage of difference between the predicted and true values of the model used as a metric.
Figure 6. Visual monitoring of the training process.
3.4 ATC speech accent level classificationThe overall framework designed in this paper is aimed at assessing the impact of accent on the performance of a speech recognition model for ATC speech. When the recognized phonemes in the test speech differ from the phonemes corresponding to the real speech text transcription, it indicates an acoustic difference between the pronunciation of the phoneme and the standard pronunciation, resulting in a slight accent phenomenon. We measure the degree of accent in the speech by evaluating the difference between the phoneme recognition sequence of the test audio and the real sequence (i.e., the phoneme recognition error rate). The error rate computed here is for the recognized and true phoneme sequences of the speech to be tested, i.e., it is the computed measure of the degree of accent of the ATC speech as proposed in this paper, denoted by WER_Accent. The principle of calculating WER_Accent is consistent with Equation (7), but due to the characteristics of ATC speech itself, such as fast speech speed and noise interference, there are some overly distorted results in the experimental results, and the number of phonemes recognized by the phoneme recognition model is more than that transcribed from the original text, resulting in WER_Accent being greater than one. WER_Accent is not limited to the value range of 0 to 1 as people usually understand, and there is no upper limit to the value range of WER_Accent. For example, it cannot be simply said that a WER_Accent value of 0.8 indicates a large degree of accent, but it should be understood that the larger the WER_Accent, the larger the degree of accent. However, the relatively small number of such phenomena is related to noise interference and distortion in ATC speech, as well as the data enhancement algorithms of the phoneme recognition model that need to be improved.
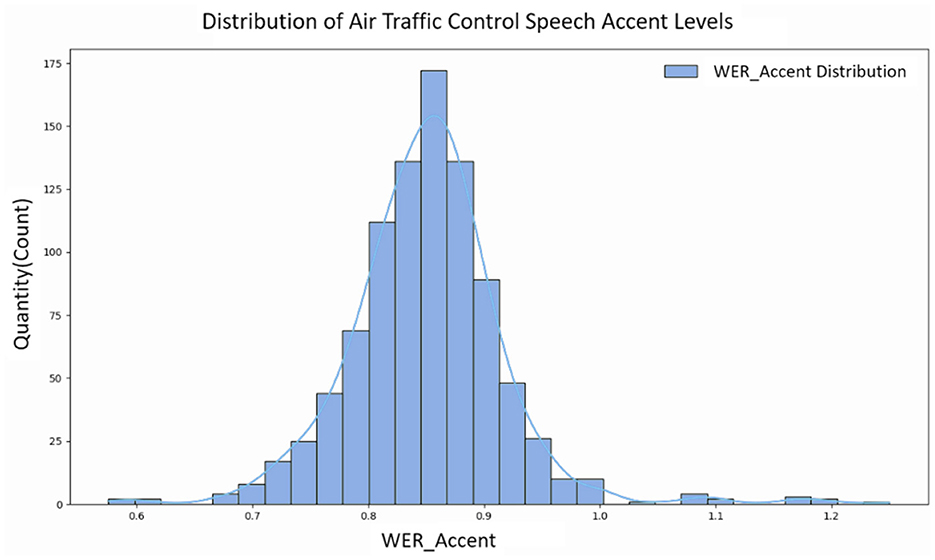
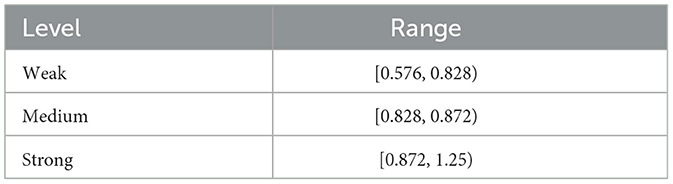
Another batch of speeches from the first-line approach control recordings was selected as test data and calculated speech accent degree distribution. According to the calculated speech accent degree distribution, the overall results show a trend of skewed distribution, as shown in Figure 7. Therefore, we artificially divided the ATC speech data tested in the experiment into three different levels based on the quartiles of the speech accent degree data distribution, corresponding to the three accent degree levels of Strong, Medium and Weak, as shown in Table 5. This division allows us to understand the differences in ATC speech accents more clearly and provides a more informative guide for further analyses and applications.
Figure 7. Distribution of degree of ATC speech accent.
Table 5. ATC speech accent level classification and description.
The ATC speech data tested in this experiment had a significantly skewed right-normal distribution of the degree of accent, with a skewness of 0.7529. The horizontal axis denotes the degree of ATC speech accent, and the vertical axis denotes the number of speech samples at the corresponding degree.
4 Experimental impact of different levels of ATC speech accent on speech recognition model accuracy 4.1 Speech recognition model accuracy impact evaluation metricSpeech data with different ATC speech accent degree levels were input into different types of ATC speech recognition models to observe their effects on the recognition accuracy of the models. The speech recognition models used in the experiments are Whisper pre-training model, an automatic speech recognition model developed by OpenAI (Radford et al., 2023), and PPASR pre-training model, a speech recognition model developed by Baidu (Zhang et al., 2022), which are publicly available on the web. Both pre-training models were fine-tuned using the same ATC speech dataset in advance before the start of the impact experiments in order to better adapt them to the pronunciation characteristics of ATC speech. Both speech recognition models use the same experimental environment, the same training dataset and test dataset. Although the pre-trained models were publicly downloaded from the web, we chose to pre-train based on the same publicly available dataset. Both pre-training models were fine-tuned using the same ATC speech dataset in advance before the start of the impact experiments in order to better adapt them to the pronunciation characteristics of ATC speech.
The recognition accuracy of each speech recognition model is also calculated using the same principle as in Equation (7), i.e., how many insertion, deletion, and substitution operations need to be performed in order to convert the recognized text output from the model to the original text. The error rate (WER_ATC_ASR) of the ATC speech recognition model calculated here is for the degree of difference between the recognized text and the real text, and the value of (1-WER_ATC_ASR) is used as the accuracy rate of the speech recognition model. After fine-tuning the training, the recognition accuracy of the Whisper-based ATC speech recognition model is 95.07%, and the recognition accuracy of the PPASR-based ATC speech recognition model is 77.21%.
In the process of calculating the correlation between the degree of ATC speech accent and the recognition accuracy of each speech recognition model, since the degree of ATC speech accent is calculated for the degree of difference between the recognized phoneme sequences of the speech to be tested and the real phoneme sequences, the recognition accuracy of the speech recognition model is aimed at the degree of difference between the recognized text and the real text, and also calculates the degree of difference between the two sequences.
Therefore, in order to unify the quantitative metrics, we adopt the minimum edit distance to analyze ATC speech accents and the recognition accuracy of each speech recognition model, which are denoted by the symbols Phoneme_Edit_Distance and ASR_Edit_Distance, respectively. The minimum edit distance is calculated by finding the minimum number of edits required to convert one sequence to another; these edit operations include inserting, deleting, and replacing characters. Minimum edit distance is usually unitless, as it indicates the number of edit operations without involving actual physical or time units. Lower values indicate that the two sequences are more similar; higher values indicate that the two sequences are less similar. Therefore, the larger the edit distance (Phoneme_Edit_Distance ) between the recognized phoneme sequence and the real phoneme sequence of the audio to be tested, the greater the degree of ATC speech accent; the larger the edit distance (ASR_Edit_Distance ) between the text recognized by the speech recognition model and the real text, the worse the recognition accuracy. The edit distance calculation formula is shown in Equation (8).
D(i,j) = min{D(i−1,j)+1 (Deletion)D(i,j−1)+1 (Insertion)D(i−1,j−1)+Cost(Si,Tj) (Substitution) (8)Where D(i, j) denotes the minimum distance required to convert the recognized phoneme sequence S(1:i) to the real phoneme sequence T(1:j) and Cost(Si, Tj) is the cost of the substitution, which is 0 if Si=Tj and 1 otherwise.
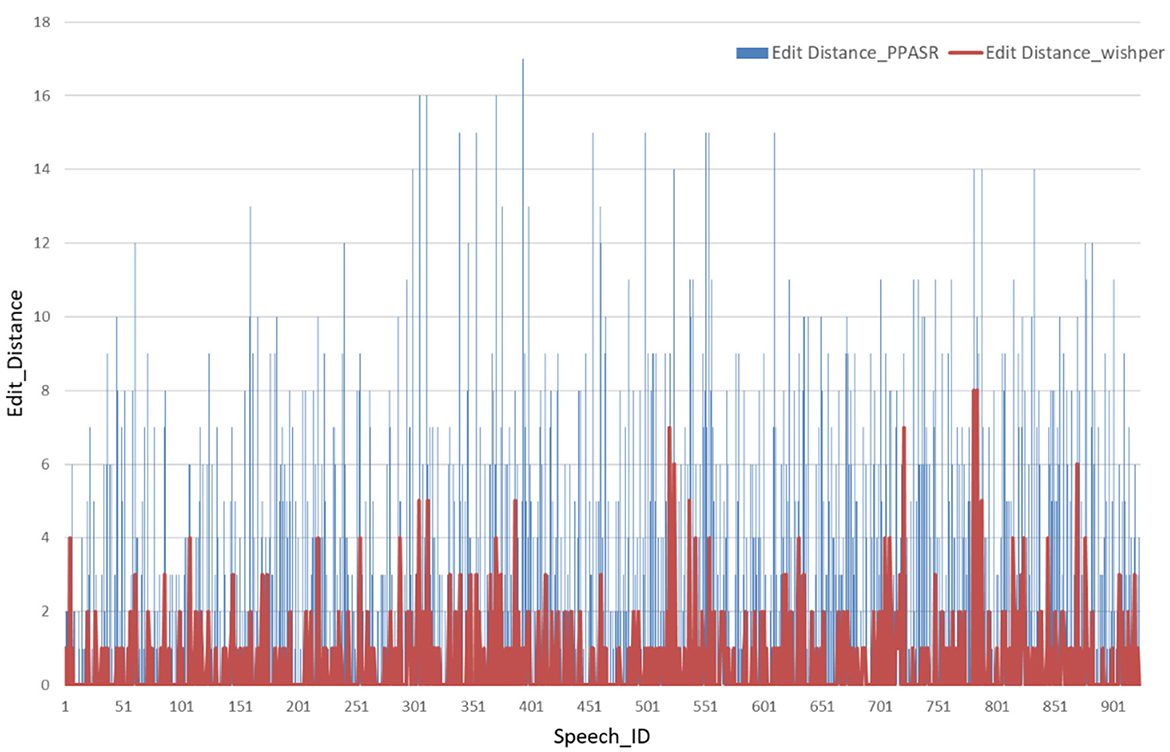
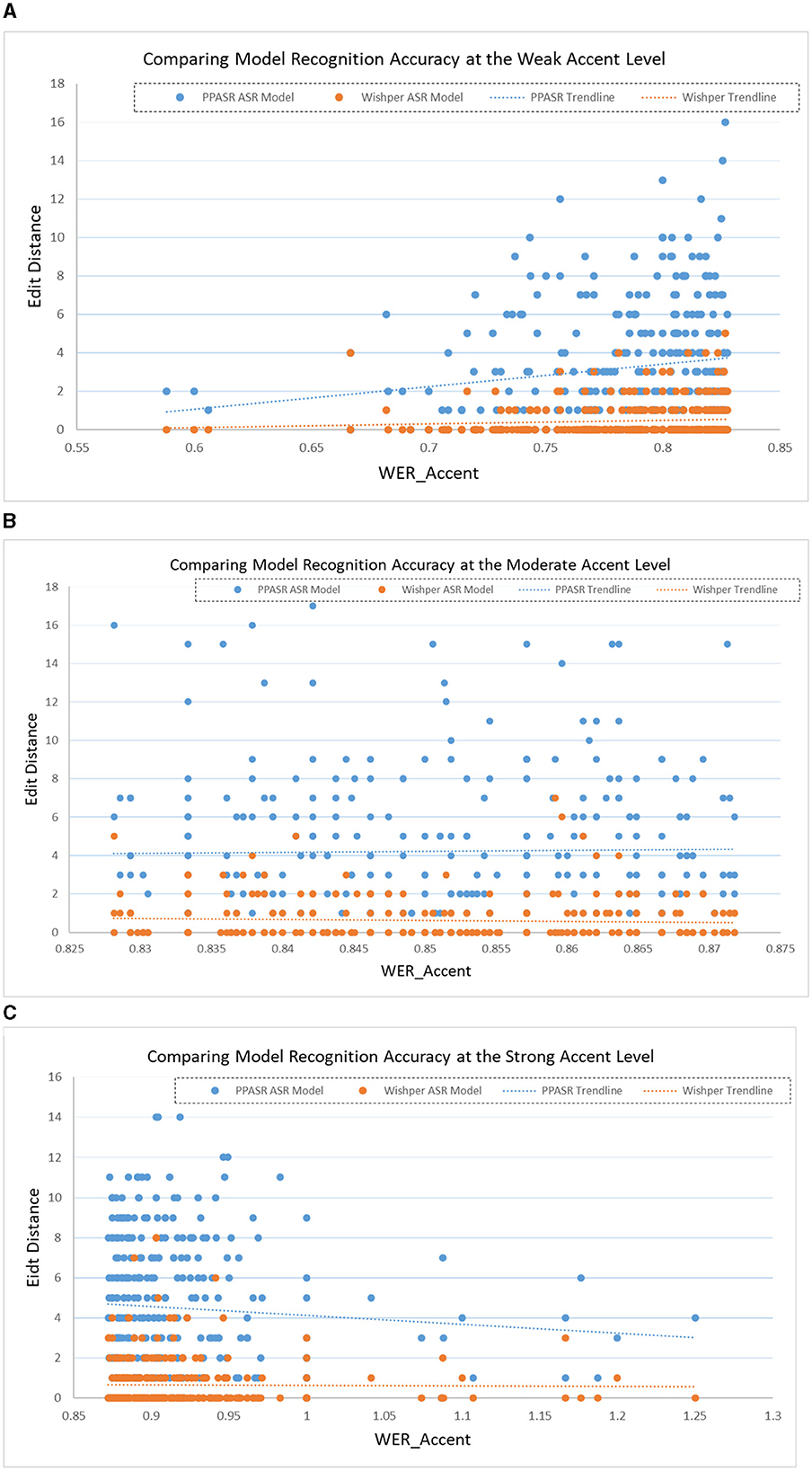
4.2 Minimum edit distance per speech in different speech recognition modelsFor experimental validation, we individually selected 1,000 ATC speech from the collected ATC speech corpus as a test set. As shown in Figure 8, the horizontal axis represents the identifier for each speech, such as Speech 1, Speech 2, and so on. The vertical axis corresponds to the minimum edit distance of each speech in the speech recognition model. When confronted with speech data with accents, the minimum edit distance of the Whisper model under each speech is significantly smaller than the performance of the PPASR model. As shown in Figure 9, the minimum edit distance of the Whisper model is also significantly smaller than that of the PPASR model as the degree of accent of the speech on the horizontal axis changes.
Figure 8. Minimum edit distance for various ATC speech recognition models.
Figure 9. Comparison of various speech recognition model accuracy performance by ATC speech accent levels. (A) Comparison of model accuracy performance for weak ATC speech accent level. (B) Comparison of model accuracy performance for medium ATC speech accent level. (C) Com-parison of model accuracy performance for strong ATC speech accent level.
In summary, the Whisper-based ATC speech recognition model exhibits high
留言 (0)