
Remember me







A retrospective observational study with an explorative character was undertaken at our hip and knee prosthetics outpatient clinic. The primary aim was to assess ChatGPT-4’s (6 July 2023 Version, OpenAI, San Francisco, USA) proficiency in orthopaedic diagnostics, in particular on its accuracy in diagnosing gonarthrosis or coxarthrosis and its therapeutic recommendations aligned with actual clinical decisions.
Patient selection and data extractionWe started a comprehensive review of medical records from patients presenting with hip or knee disorders at our outpatient clinic between 2022 and 2023. From the patient data available, we intentionally selected a study sample of 100 adult patients, ensuring an equal distribution of 50 patients with knee disorders and 50 with hip disorders. This target was also chosen to achieve an adequate population size due to the exploratory nature of the study. Furthermore, within these two groups, we maintained an even distribution in terms of treatment recommendation, with 25 patients advised for conservative treatments and 25 for surgical interventions in each group. Additionally, our sample also ensured gender balance, with 50 male and 50 female participants.
To qualify for the study, the adult patients needed to exhibit clear clinical signs of either gonarthrosis or coxarthrosis. Their medical history had to be comprehensive, including symptomatology, outcomes of physical examinations, radiographic interpretations provided by a certified radiologist, and treatment recommendations made by an orthopaedic specialist.
The outpatient medical record had to include following data:
Demographics: age, sex.
Clinical diagnosis: presence of gonarthrosis or coxarthrosis.
Anatomical details: affected joint and side.
Comorbidities: general systemic conditions, specific comorbidities such as lumbago, rheumatic diseases, obesity, prior arthroplasty on the opposite side and record of any prior surgery related to the joint.
Clinical history: duration of symptoms, various pain symptoms, need for pain medication, previous therapy such as intraarticular injections and physiotherapy.
Physical examination: clinical inspection results, joint mobility assessments and other diagnostic signs.
Radiological findings: radiological report of the X-ray, and if available, magnetic resonance imaging (MRI) findings of the considered joint.
Treatment suggestion: recommendation of the orthopaedic specialist regarding conservative or operative therapy consisting in a total joint arthroplasty.
Medical records that seemed inconsistent, especially those devoid of the essential symptom descriptions, physical examination findings, or radiographic readings, were dismissed.
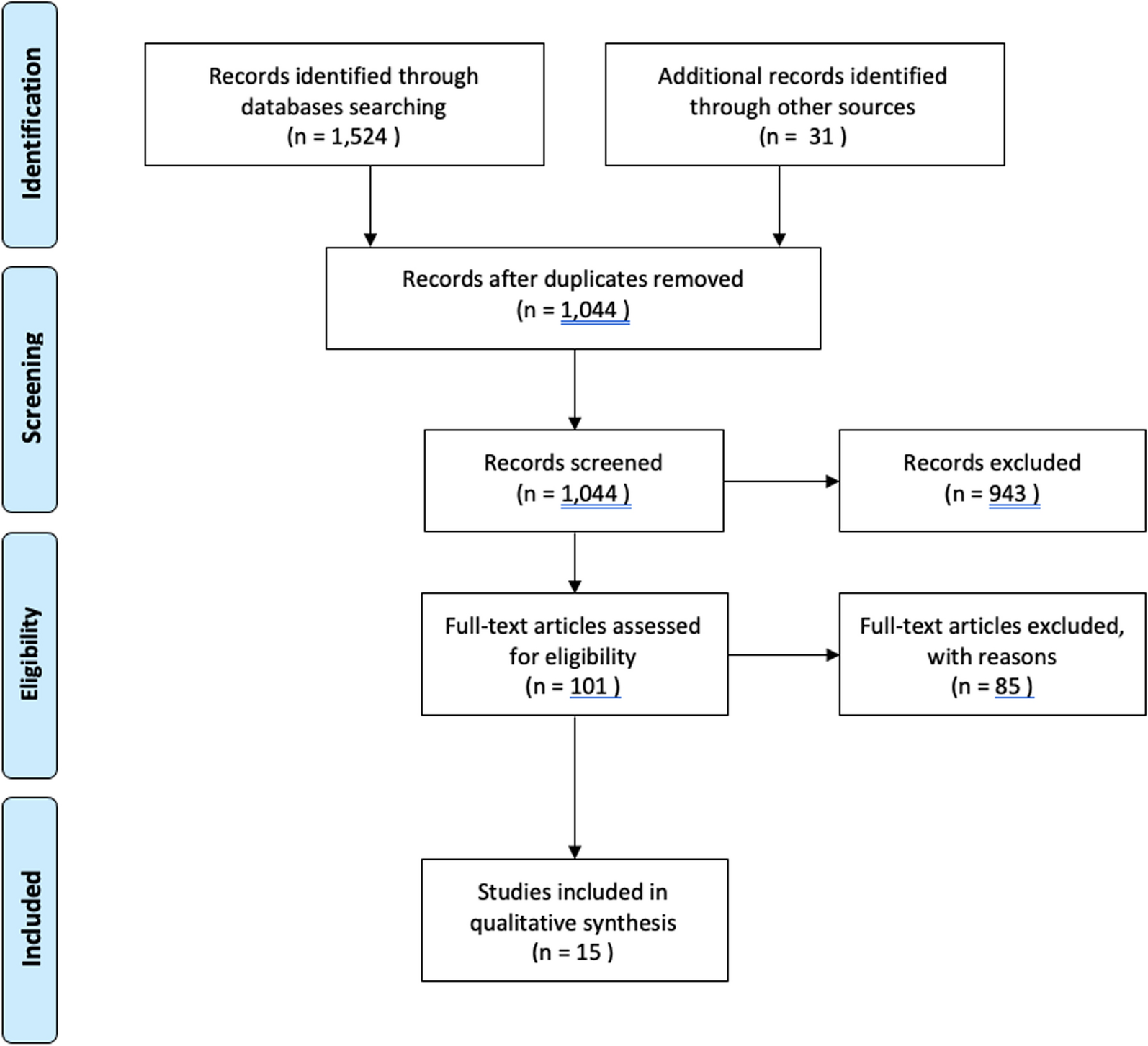
Those for whom the primary medical concern was not related to arthrosis, or who presented with disorders in hip and knee joint simultaneously, were also omitted from the study. Moreover, patients advised for surgery were excluded from the study if the procedure indicated was not specifically a total hip or knee arthroplasty (Fig. 1).
Fig. 1
Flowchart illustrating the patient selection process for the study
Data input into ChatGPT-4Given the sensitive nature of medical data, a meticulous anonymization process was followed before any clinical record was entered into ChatGPT-4. Additionally, all direct or explicit references to arthrosis as well as the treatment recommendations were removed from the medical report. Although the radiologic images were graded for osteoarthritis using the Kellgren and Lawrence (KL) classification system [13] to characterize our patient cohort, this specific classification was not included in the analysis. Instead, only a descriptive radiological report was used, from which all direct references to arthrosis were removed before input into ChatGPT-4. To maintain the integrity of the study and to ensure that ChatGPT-4 was making independent assessments, each record was entered into a fresh input page, preventing any possible influence from previous data.
ChatGPT-4 was provided with comprehensive anonymised patient information, which included descriptions of symptoms, results of physical examinations and radiographic interpretations with the expectation to generate a differential diagnosis, to rank possible disorders based on likelihood and to suggest relevant therapeutic recommendations. The specifics of this task can be found in Additional file 1 under ‘Clinical Query Input to ChatGPT-4—Case Prompt’.
In the responses generated by ChatGPT-4, the generative model gives a series of potential diagnoses and corresponding treatment options, each accompanied by a specific percentage. These percentages signify the model’s calculated confidence in the likelihood of each diagnosis or the appropriateness of each treatment option on the basis of its learning algorithms and the medical data it has been trained on. Essentially, the percentages reflect how closely the input data – symptoms, physical examination results, and radiographic interpretations – match the information within the model’s training datasets, indicating the probability that a particular diagnosis is correct or a specific treatment is suitable given the patient’s unique presentation.
For statistical analysis, a standardized approach was then employed to interpret ChatGPT-4’s responses. From the list of diagnoses and therapeutic strategies the model provided, we selected as the model’s primary suggestion the single option in each category with a confidence score surpassing 50%. This threshold was chosen to prioritize options with a higher level of algorithmic certainty. In analysing ChatGPT-4’s responses, we noted that the model often suggested multiple conservative treatments. To accommodate this in our statistical analysis, we combined the confidence scores of different treatments within the same category (conservative or surgical). For instance, if physical therapy had a 30% confidence score and pain medication 25%, we would aggregate them, achieving a cumulative 55% confidence for conservative treatment. However, for surgical recommendations, we only accounted for total arthroplasty suggestions. The primary category surpassing a 50% total confidence was then taken as ChatGPT-4’s main recommendation.
To offer a clearer understanding of ChatGPT-4’s response, a chosen example from its feedback is described in Additional file 1 under ‘Case-Based ChatGPT-4 Response’.
Statistical analysisContinuous variables were presented as mean (standard deviation, SD), while categorical data were expressed using absolute (n) and percentage (percentage) frequencies. For comparing continuous data, two-sided t-tests were employed, and categorical data comparisons were executed using the chi-squared test.
The accuracy of ChatGPT-4 in deducing disorders and giving recommendations on the basis of the provided records was assessed using sensitivity, specificity, positive predictive value (PPV) and negative predictive value (NPV), considering the physician’s therapeutic advice as the gold standard.
To assess the interrater reliability between ChatGPT-4’s therapeutic advice and the physicians’ recommendations, Cohen’s Kappa statistic was used [14].
A multivariable logistic regression was then employed to test any associations between ChatGPT-4’s therapeutic suggestions and parameters such as patient demographics, medical backgrounds and outcomes from clinical examinations, taking care to account for confounders.
Given the exploratory nature of this study, a power calculation was not performed.
Patient data were collected using the in-house database (ORBIS, Agfa healthcare). IBM SPSS Statistics version 29 was the software of choice for all statistical analyses, and the significance level was set at a two-sided p ≤ 0.050.
The study was conducted upon approval from the Ethics Committee of the University of Regensburg (protocol no. 23-3404-104).
Comments (0)