
Remember me

In the following, the gradient flows of the vanilla and the dual single-layer neural networks are formally examined when trained using the quantization error, one of the most common loss functions used for training unsupervised neural networks in clustering contexts. The following theory is based on the assumption of \(\lambda = 0\) in Eq. (12). Taking into account the edge error only relaxes the analysis, but the results remain valid. Under the stochastic approximation theory, the asymptotic properties of the gradient flows of the two networks can be estimated.
Base Layer Gradient FlowFor each prototype j, represented in the base layer by the weight vector \(_^ \in }^\) of the j-th neuron (it is the j-th row of the matrix \(_\)), the contribution of its Voronoi set to the quantization error is given by:
$$^= \sum_^_}_-_^\Vert }_^= \sum_^_}(_\Vert }_^ + _^\Vert }_^-2 _^_^)$$
(19)
where \(_\) is the cardinality of the j-th Voronoi set. The corresponding gradient flow of the base network is the following:
$$_^\left(t+1\right)=_^\left(t\right)- \epsilon __^}^=_^\left(t\right)-\epsilon \sum_^_}(_^-_)$$
(20)
being \(\varepsilon\) the learning rate. The averaging ODE holds:
where \(_= }[_]\) is the expectation in the limit of infinite samples of the j-th Voronoi set, and corresponds to the centroid of the Voronoi region. The unique critical point of the ODE is given by:
and the ODE can be rewritten as:
under the transformation \(_^= _^ - _^\) in order to study the origin as the critical point. The associated matrix is \(-_\), whose eigenvalues are all equal to − 1 and whose eigenvectors are the vectors of the standard basis. Hence, the gradient flow is stable and decreases in the same exponential way, as \(^\), in all directions. The gradient flow of one epoch corresponds to an approximation of the second step of the generalized Lloyd iteration, as stated before.
Dual Layer Gradient FlowIn the dual layer, the prototypes are estimated by the outputs, in such a way that they are represented by the rows of the \(_\) matrix. Indeed, the j-th prototype is now represented by the row vector \(_^\right)}^\), from now on called \(_^\) for sake of simplicity. It is computed by the linear transformation:
$$_^= _^\right)}^\left[_ \cdots _\right]= _^\right)}^^=_^ ^$$
(24)
where \(_\in }^\) is the i-th row of the training set \(X\) and \(_^\in }^\) is the weight vector of the j-th neuron (it is the j-th row of the matrix \(_\)), and is here named as \(_\) for simplicity. Hence, the j-th prototype is computed as:
and its squared (Euclidean) 2-norm is:
$$_\Vert }_^= _^ ^ X _$$
(26)
For the j-th prototype, the contribution of its Voronoi set to the quantization error is given by:
$$^=\sum_^_}_-_\Vert }_^=\sum_^_}(_\Vert }_^ + _\Vert }_^ -2 _^_)$$
(27)
with the same notation as previously. The gradient flow of the dual network is computed as:
$$_\left(t+1\right)= _\left(t\right)- \epsilon __}^$$
(28)
being \(\epsilon\) the learning rate. The gradient is given by:
$$__}^=__}\sum_^_}\left(_^_+ _^^X _- 2 _^^_\right)= 2 \left(^X _- ^_\right)$$
(29)
The averaging ODE is estimated as:
$$\frac_}=-\left(^X _- ^_\right)$$
(30)
The unique critical point of the ODE is the solution of the normal equations:
The linear system can be solved only if \(^X\in }^\) is full rank. This is true only if \(n \le d\) (the case \(n = d\) is trivial and, so, from now on the analysis deals with \(n < d\)) and all columns of X are linearly independent. In this case, the solution is given by:
where \(^\) is the pseudoinverse of \(X\). The result corresponds to the least squares solution of the overdetermined linear system:
which is equivalent to:
This last system shows that the dual layer asymptotically tends to output the centroids as prototypes. The ODE can be rewritten as:
under the transformation \(_ = _ - _\) in order to study the origin as the critical point. The associated matrix is \(-^X\). Consider the singular value decomposition (SVD) of \(X = U\Sigma ^\) where \(U\in }^\) and \(V\in }^\) are orthogonal and \(\Sigma \in }^\) is diagonal (nonzero diagonal elements named singular values and called \(_\), indexed in decreasing order). The i-th column of \(V\) (associated to \(_\)) is written as \(_\) and is named right singular vector. Then:
$$^X=^\right)}^U \Sigma ^= V ^^$$
(36)
is the eigenvalue decomposition of the sample autocorrelation matrix of the inputs of the dual network. It follows that the algorithm is stable and the ODE solution is given by:
$$_\left(t\right)= \sum_^__^_^t}$$
(37)
where the constants depend on the initial conditions. The same dynamical law is valid for all the other weight neurons. If \(n > d\) and all columns of X are linearly independent, it follows:
$$rank \left(X\right)=rank \left(^X\right)=d$$
(38)
and the system \(X_ = _\) is underdetermined. This set of equations has a nontrivial nullspace and so the least squares solution is not unique. However, the least squares solution of minimum norm is unique. This corresponds to the minimization problem:
$$\mathit\left(_\right)\; s.t. X_=_$$
(39)
The unique solution is given by the normal equations of the second kind:
$$\left\X^z=_\\ _=^z\end\right.$$
(40)
that is, by considering that \(X^\) has an inverse:
Multiplying on the left by \(X^\) yields:
$$\left(^X\right)_= \left(^X\right)^^X\right)}^_= ^\left(^X\right)^X\right)}^_= ^_$$
(42)
that is Eq. (31), which is the system whose solution is the unique critical point of the ODE (setting the derivative in Eq. (30) to zero). Resuming, both cases give the same solution. However, in the case \(n > d\) and \(rank(X) = d\), the output neuron weight vectors have minimum norm and are orthogonal to the nullspace of X, which is spanned by \(_, _, \dots , _\). Indeed, \(^X\) has \(n-d\) zero eigenvalues, which correspond to centers. Therefore, the ODE solution is given by:
$$_\left(t\right)= \sum_^__^_^t}+\sum_^__$$
(43)
This theory proves the following theorem.
Theorem 3.1(Dual flow and PCA). The dual network evolves in the directions of the principal axes of its autocorrelation matrix (see Eq. (36)) with time constants given by the inverses of the associated data variances.
This statement claims the dual gradient flow moves faster in the more relevant directions, i.e., where data vary more. Indeed, the trajectories start at the initial position of the prototypes (the constants in Eq. (43) are the associated coordinates in the standard framework rotated by V) and evolve along the right singular vectors, faster in the directions of more variance in the data. It implies a faster rate of convergence because it is dictated by the data content, as already observed in the numerical experiments (see Fig. 4).
Dynamics of the Dual LayersFor the basic layer, it holds:
where \(l \in }^\) is a vector of constants. Therefore, \(_^\) tends asymptotically to \(_\), by moving in \(}^\). However, being \(_\) a linear combinations of the columns of X, it can be deduced that, after a transient period, the neuron weight vectors tend to the range (column space) of X, say R(X), i.e.:
$$\forall j,\forall t>_ \space \space \space \space _^\in R\left(X\right)=span \;(_,_,\dots , _)$$
(45)
where \(_\) is a certain instant of time and \(r = rank(X) = min\\) under the assumption of samples independently drawn from the same distribution, which prevents from the presence of collinearities in data. It follows
where \(l \in }^\) is another vector of constants. Then, \(_^\) can be considered the output of a linear transformation represented by the matrix X, i.e., \(_^=_\), being \(p \in }^\) its preimage. Hence, \(_^)}^=^^\), which shows the duality. Indeed, it represents a network whose input is \(^\), and the output \(_^)}^\) and parameter weight vector \(^\) are the interchange of the corresponding ones in the base network. Notice, however, that the weight vector in the dual network corresponds only through a linear transformation, that is, by means of the preimage. Under the second duality assumption \(X^ = _\), it holds:
$$\begin&^T=U\Sigma V^T\left(U\Sigma V^T\right)^T=U\Sigma\Sigma^TU^T=I_d\Rightarrow U\Sigma\Sigma^T=U\Rightarrow\\&\left\UI_d=U \space \space \space \space \space \space \space \space d\leq n\\U\beginI_n&0_\\0_&0_\end \space \space d>n\end\right.\end$$
(47)
where \(_\) is the zero matrix with r rows and s columns. Therefore, this assumption implies there are d singular values all equal to 1 or − 1. In the case of remaining singular values, they are all null and of cardinality \(d - n\). For the dual layer, under the second duality assumption, in the case of singular values all equal to − 1 or 0, it follows:
$$_-_ = \left\Vq ^ \space \space \space \space \space \space \space \space \space \space \space \space \space \space \space \space d\ge n\\ Vq\left[\begin^_\\ _\end\right] \space \space \space \space d<n \end\right.$$
(48)
where \(q \in }^\). Therefore, \(_\) tends asymptotically to \(_\), by moving in \(}^\). Hence, it can be deduced that, after a transient period, the neuron weight vectors tend to the range (column space) of X, say \(R(^)\), i.e.:
$$\forall j,\forall t>_ \space \space \space \space\space ^\in R\left(^\right)=span \;(_,_,\dots , _)$$
(49)
where \(_\) is a certain instant of time and \(r = rank(X) = min\\) under the same assumption of noncollinear data.
Resuming, the base and dual gradient flows, under the two duality assumptions, except for the presence of centers, are given by:
$$\left\w_1^j=Uce^\\\omega_j=Vqe^\end\Rightarrow X\omega_j=XVqe^\right.\Rightarrow X\omega_j=U\Sigma qe^\Rightarrow X\omega_j=Uce^\Rightarrow w_1^j=X\omega_j$$
(50)
because \(XV = U\Sigma\) from the SVD of X and \(c = \Sigma q\) for the arbitrariness of the constants. This result claims the fact that the base flow directly estimates the prototype, while the dual flow estimates its preimage. This confirms the duality of the two layers from the dynamical point of view and proves the following theorem.
Theorem 3.2(Dynamical duality). Under the two assumptions of 2.1, the two networks are dynamically equivalent. In particular, the base gradient flow evolves in \(R(X)\) and the dual gradient flow evolves in \(R(^)\).
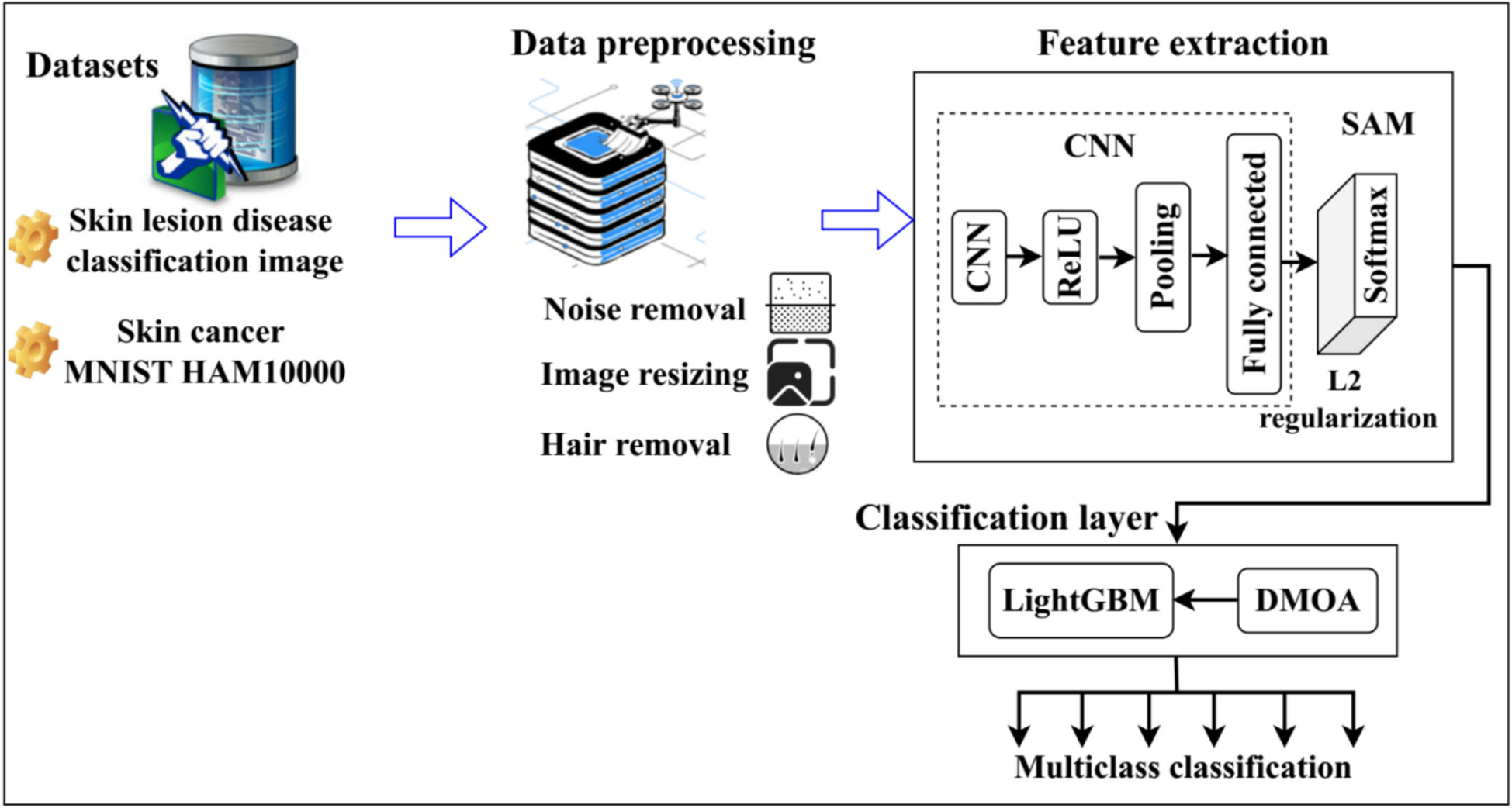
More in general, the fact that the prototypes are straightly computed in the base network implies a more rigid dynamics of its gradient flow. On the contrary, the presence of the singular values in the exponentials of the dual gradient flow originates from the fixed transformation (matrix X) used for the prototype estimation. They are exploited for a better dynamics, because they are suited to the statistical characteristics of the training set, as discussed before. Both flows estimate the centroids of the Voronoi sets, like the centroid estimation step of the Lloyd algorithm, but the linear layers allow the use of gradient flows and do not require the a priori knowledge of the number of prototypes (see the discussion on pruning in the “Clustering as a Loss Minimization” section). However, the dual flow is an iterative least squares solution, while the base flow does the same only implicitly. In the case\(d > n\),\(rank(X) = rank(^) = n\), and the base gradient flow stays in \(}^\), but tends to lie on the n-dimensional subspace\(R(X)\). Instead, the dual gradient flow is n-dimensional and always evolves in the n-dimensional subspace\(R(^)\). Figure 8 shows both flows and the associated subspaces for the case \(n = 2\) and\(d = 3\). The following lemma describes the relationship between the two subspaces.
Fig. 8
Gradient flows and subspaces (n = 2 and d = 3) [67]
Lemma 3.3(Range transformation). The subspace \(R(X)\) is the transformation by X of the subspace \(R(^)\).
Proof. The two subspaces are the range (column space) of the two matrices X and \(^\):
$$R\left(X\right)=\$$
(51)
$$R\left(^\right)=\left\^x\; \space \space for\; a\; certain \;x\right\}$$
(52)
Then:
$$XR\left(^\right)=\left\^x\; \space \space for\; a \;certain \;x\right\}=R(X)$$
(53)
More in general, multiplying X by a vector yields a vector in \(R(X)\).
All vectors in \(R(^)\) are transformed by X in the corresponding quantities in \(R(X)\). In particular:
$$_=\frac_}X_ \space \space\ \space \space\ \forall i=1,\dots ,n$$
(54)
This analysis proves the following theorem.
Theorem 3.4(Fundamental on gradient flows, part I). In the case \(d > n\), the base gradient flow represents the temporal law of a d-dimensional vector tending to an n-dimensional subspace containing the solution. Instead, the dual gradient flow always remains in an n-dimensional subspace containing the solution. Then, the least squares transformation \(^\) yields a new approach, the dual one, which is not influenced by d, i.e., the dimensionality of the input data.
This assertion is the basis of the claim the dual network is a novel and very promising technique for high-dimensional clustering. However, it must be considered that the underlying theory is only approximated and gives an average behavior. Figure 7 shows a simulation comparing the performances of VCL, DCL, and a deep variant of the DCL model in tackling high-dimensional problems with an increasing number of features. The simulations show how the dual methods are more capable to deal with high-dimensional data as their accuracy remains near 100% until 2000 − 3000 features. Obviously, the deep version of DCL (deep-DCL) yields the best accuracy because it exploits the nonlinear transformation of the additional layers.
In the case \(n \ge d\), instead, the two subspaces have dimension equal to d. Then, they coincide with the feature space, eliminating any difference between the two gradient flows. In reality, for the dual flow, there are \(n - d\) remaining modes with zero eigenvalue (centers) which are meaningless, because they only add \(n - d\) constant vectors (the right singular vectors of X) which can be eliminated by adding a bias to each output neuron of the dual layer.
Theorem 3.5(Fundamental on gradient flows, part II). In the case \(d \le n\), both gradient flows lie in the same (feature) space, the only difference being the fact that the dual gradient flow temporal law is driven by the variances of the input data.
The Voronoi Set EstimationConsider the matrix\(^^\in }^\), which contains all the inner products between data and prototypes. From the architecture and notation of the dual layer, it follows \(=\Omega ^\), which yields:
where the sample autocorrelation data matrix G is the Gram matrix. The Euclidean distance matrix\(edm(X, Y ) \in }^\), which contains the squared distances between the columns of X and Y, i.e., between data and prototypes, is given by [64]:
$$edm\left(X, Y\right)=diag\left(^X\right)_^-2^^+_diag^\right)}^$$
(57)
where diag(A) is a column vector containing the diagonal entries of A and \(_\) is the r-dimensional column vector of all ones. It follows:
$$edm\left(X, Y\right)= _^- 2G^+ _diag^\right)}^$$
(58)
and considering that \(Y^=\Omega ^^\right)}^=\Omega G ^\), it holds:
$$edm\left(X, Y\right)=f\left(G,\Omega \right)= _diag^\right)}^- 2G ^+ _^$$
(59)
as a quadratic function of the dual weights. This function allows the straight computation of the edm from the estimated weights, which is necessary in order to evaluate the Voronoi sets of the prototypes for the quantization loss.
Comments (0)