
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Remember me
The analysis of extracellularly recorded neural action potentials (i.e. spikes) relies on spike sorting techniques [1, 2]. These techniques facilitate the decoding of population-level neural activities and contribute to the investigation of sensory information encoding and processing in neural circuitries [3–6]. In extracellular neural recordings [7–11], action potentials from several nearby neurons are simultaneously captured by an implanted electrode, resulting in distinct shapes of spike waveforms depending on neuronal properties, as well as the relative position and orientation to the electrode. These spike shapes are extracted and employed as classification features in spike sorting algorithms to classify and assign each spike to its originating neuron, thereby providing a more accurate representation of the underlying neural activity. With the development of multielectrode probes and advanced neural modulation techniques such as optogenetics [12, 13] and closed-loop control [14], efficient and accurate spike sorting systems are highly demanded.
Contrasting with offline spike sorting, which processes data after recording completion [1, 15–22], online real-time spike sorting algorithms perform rapid spike extraction and classification immediately after spikes are acquired during data acquisition. This technique has become increasingly popular in neuroscience research due to its indispensability in emerging applications like closed-loop neural control systems [14, 23–25] and optogenetic-based neural stimulation systems [26–29]. These applications typically necessitate instant and precise single-cell spiking information within millisecond-scale latency [25, 30].
In recent years, several real-time spike sorting algorithms have been developed and implemented in dedicated hardware. Template-matching [25, 31–36] is a widely utilized approach, wherein real-time spike sorting is conducted based on pre-trained spike templates or matching filters [37–40]. As a supervised method, the pre-training phase is essential and directly impacts system performance. However, this approach faces challenges in efficiently handling recording variations and the appearance of new clusters after the training that commonly occur in chronic neural implants due to electrode drifting [1, 34]. As a result, untrained spikes are either discarded or misclassified [41]. Alternatively, the unsupervised K-means algorithm has been modified for real-time spike sorting and implemented into low-power application-specific integrated circuit (ASIC) designs [42, 43]. Nonetheless, it requires pre-defined cluster numbers and encounters similar difficulties in handling variations. Thus, a robust unsupervised real-time spike sorting system that can effectively detect and track recording variations is highly demanded.
OSort [44], a widely used unsupervised spike sorting algorithm, demonstrates performance comparable to other offline algorithms [1, 44, 45]. Unlike conventional offline spike sorting algorithms [1, 17, 45, 46], OSort processes spike in a streaming manner and conducts sorting spike by spike, making it inherently appropriate for hardware implementations such as accelerated offline OSort on field programmable gate array (FPGA) platforms with a 25-fold speedup [47], or online OSort on FPGA or integrated circuit (IC) designs [41, 48–54]. However, a significant challenge in performing real-time spike sorting using OSort is the massive memory usage and heavy computation load during the initiation phase, characterized by an uncertain large number of transient clusters to save before eventual convergence, especially in multi-channel systems. Various strategies have been developed to implement hardware OSort with reduced memory usage, including utilizing shared memory between all channels [36, 49, 54] or limiting the number of occurring clusters [41]. In one example of an IC implementation for a 16-channel system [48, 49], a multiplexing approach was utilized to share memory among all channels to generate the channel templates, and a template-matching process was then conducted across all channels to perform real-time spike sorting. Despite optimizing memory usage and working voltage, memory-related power consumption still accounted for a dominant 88% [49]. In addition, accurately estimating the number of transient clusters is challenging, often requiring extra considerations to avoid cluster overflow, such as inferring from experimental data [47–49] or weighting cluster size and eliminating small clusters [36, 41]. Although existing designs of hardware OSort have recognized challenges posed by transient clusters and mitigated the issue through increased architecture complexity, there remains a need for a more targeted solution to tackle the issues of transient clusters in the implementation of hardware OSort.
In this study, we propose an optimized OSort algorithm (opt-OSort) specially adapted for real-time hardware implementation, which seeks to resolve issues related to transient clusters by applying a fixed number of cluster slots while preserving the performance and advantages of the original OSort. Furthermore, opt-OSort is designed to handle recording variations such as electrode drifting in chronic recordings. The FPGA-implemented opt-OSort achieves an accuracy comparable to offline OSort and exhibits a reduction in transient cluster occurrence by two orders of magnitude with a 0.68 µs sorting time. These outcomes demonstrate a rapid, precise and robust spike sorting solution that can be integrated into low-power, portable or implantable devices for further closed-loop neural control systems.
The proposed opt-OSort algorithm utilizes cluster slots to perform spike sorting, where the number of cluster slots can be determined by the count of neurons recorded in experimental data, typically ranging from 4 to 6 per channel in extracellular recording [49]. The implementation of a fixed number of cluster slots leads to a marked reduction in memory usage, thus reducing the computation of spike classification and facilitating further simplification of the related hardware architecture. This section starts with an introduction to the OSort algorithm and the obstacles in implementing hardware OSort, proceeds with an explanation of the proposed opt-OSort algorithm and its hardware implementation, and ends with the description of the simulated datasets and experimental recordings used to verify the performance.
2.1. OSort and transient clustersThe conventional OSort algorithm conducts spike sorting in a streaming manner as illustrated by the flowchart in figure 1. Initially, the distances (D) between the incoming streaming spikes and all existing cluster centers are calculated. These cluster centers are computed as the means of all spikes in the corresponding clusters, with the first spike of a new cluster serving as the center. Following this, the minimum distance (min(D)) of the input spike is compared to the preset spike classification threshold (TC). When the min(D) exceeds TC, indicating that the input spike does not belong to any existing clusters, a new cluster is created, and the corresponding spike is established as the cluster center. The algorithm then completes the sorting process and awaits the next spike. Conversely, if min(D) is less than TC, the input spike is assigned to the min(D) cluster. In this case, as a new spike is assigned, the center of the min(D) cluster needs to be updated. Subsequently, the distances (Dall) between the min(D) cluster center and all other centers are computed, and the min(D) cluster is merged with the min(Dall) cluster if they are close to each other. During this procedure, if min(Dall) is less than the preset cluster merging threshold (TM), indicating that two clusters are not distant from one another, they are merged together and a new cluster center is generated. This process is iteratively carried out until no cluster merging occurs (or min(Dall) > TM). Once this is achieved, the spike classification is completed and the algorithm awaits the next input spike.
Figure 1. Flowchart of the original OSort algorithm.
Download figure:
Standard image High-resolution imageTwo thresholds TC and TM are estimated as the same value of N times δ in real implementation, where N is the number of samples used to represent a spike, and δ is the standard deviation of recording noise [44]. The cluster center generated by two merged clusters is calculated as the weighted average of each center. For example, two cluster centers C1 (containing M spikes) and C2 (containing P spikes) are merged, the new cluster center Cnew is calculated as equation (1) [49]:
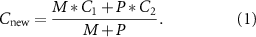
Since the input spikes are streamingly sent into OSort and the OSort has the process of creating new clusters, the early formed clusters are usually not the final converging clusters. There are a large number of transient clusters gradually occurring during the procedure of spike sorting. The outputted spike ID in this phase is thus not the true ID of the spike. Each input spike will slowly drive the centers of transient clusters moving towards the direction of the converging centers, and these movements will further promote the merge of transient clusters that are closed in distance. Along with this procedure, these transient clusters are gradually occurring, moving, merging, and finally converged into several clusters which are equal to the number of recorded neurons in the experiment.
The advantage of the OSort is to handle spikes in a streaming manner, thus it is hardware friendly to handle streamingly captured neural voltages in real-time [36, 41, 44, 47–54]. However, the large number of transient clusters still rise several challenges for hardware implementation when performing real-time spike sorting.
The first issue is that the number of transient clusters is difficult to estimate in real recordings. It is related to the distribution of spike data and recording noise, especially when the recorded neural signal is contaminated by non-Gaussian noise like electrode-drifting or animal moving artifacts, which are unavoidable to happen in the long-term recordings. All these factors can increase the number of transient clusters in the sorting procedure. For example, figure 2 shows the maximum number of transient clusters under different noise level in a simulated dataset, which is from the OSort paper and each set of data contains three neural clusters [44]. The spike amplitudes are normalized into 1 and the noise level is expressed as the standard deviation of recording noise. Figure 2 demonstrates that the maximum number of transient clusters are varying greatly, from minimal 40 to maximal 201 clusters under different noise level. However, the capability designed to handle the transient clusters is usually limited in hardware. Thus, strategies have to be taken to estimate the number of occurring clusters, but it is usually impractical in real recordings. To solve this problem, the handled clusters are estimated by experimental observations in some designs [36, 47, 49], or monitoring the cluster size and removing the small size clusters to handle the case of cluster overflow [36, 41, 49]. The hardware architecture is thus complicated.
Figure 2. The number of transient clusters varies under different levels of noise using OSort dataset [44].
Download figure:
Standard image High-resolution imageThe second issue caused by the transient clusters is the memory cost. Even though only three neural clusters are constructed in the dataset [44], all transient cluster centers (40-201) are required to be saved to calculate the final converging cluster centers. The extra memory required is about 13–67 times compared to the final converged clusters in the simulated dataset. This is not a problem for running OSort algorithm in a computer which has massive memory. However, for IC or ASIC design, the memory is very precious resource and its usage has to be carefully considered. Not to mention that the previous analysis is just for single-channel recording. In a commonly-used multi-channel system, 13–67 times of the memory cost is unacceptable without any optimization. Therefore, the architecture of sharing memory between channels is typically adopted to save memory in hardware implementations [36, 49, 54]. Along with the memory cost, power consumption is another big challenge for implementing spike sorting digital signal processor (DSP) with big memory. After optimizing the architecture of hardware implementation (to save memory) and memory working voltage (to save power), the memory-related designs still take about 88% power consumption [49]. Excessive power-consumption limits the OSort-based system implemented into miniaturized, portable, and low-power devices for future closed-loop control applications.
The third issue caused by the transient clusters is the heavy computation load. As described in figure 1, each new input spike requires computing distances with transient cluster centers to perform spike classification. After assigning the spike into a cluster, the cluster merging procedure is conducted between all existing centers. It is an iteration process: the cluster merging would be continually carried out between the transient clusters until all left clusters are far away from each other in distance. The large number of transient clusters obviously leads to more computations, therefore increasing computational latency and consuming more power. Thus, the development of low-power portable devices using OSort to perform real-time spike sorting is hindered.
2.2. Optimized OSort algorithmThe nature of spike sorting is to cluster a group of spikes that have similar features in the same group, which are distinct from other groups. The original OSort uses spike waveform as the spike features, which indicates that different spikes are clustered by their temporal shapes and the spike distances are used as the only factor to classify spikes and merge clusters. Combining with the streaming processed manner, it is easy to generate a large number of transient clusters, especially when the recorded neural signal is contaminated by non-Gaussian noise, which is unavoidable in real physiological conditions (electrical drifting, cell bursting activity, and local field potential occurrence) during the long term recordings [1].
To sort the neural spikes into different clusters, it has been found in previous work [34] that both Euclidean distance (ED) and correlational matching (CM) techniques achieved high sorting accuracy. And CM can better handle spikes with non-Gaussian distributions, making it more robust for physiological conditions and recording noises. The results can be explained by the fact that mathematically the correlation coefficient is much less sensitive to amplitude fluctuation as long as the spike shape is maintained, while ED may change significantly when the amplitude varies.
Inspired by this finding, we propose an optimized OSort algorithm (opt-OSort) that uses Pearson correlation coefficients (CC) between the temporal shapes as spike classification factor to reduce the transient cluster number. Neural spikes usually remain similar temporal shape under the same recording neuron [33, 34, 55] and this keeps the spike in the same clusters with high CC values, while the spikes from different clusters keep pretty low CC values. Yet if CC is used to replace distance as spike classification criterion, the converged cluster number could possibly be detected at the first several spikes as long as the spike shape in the same clusters is very similar. Therefore, three groups of neural spikes could potentially be detected by the first three spikes if they are belonging to different clusters, and the rest spikes would be automatically classified into the first three clusters as long as they have similar spike shapes and keep a high CC value with their respective cluster centers. This method could find the converged cluster number using a few numbers of spikes with high CC values. Hence, the process that a large number of transient clusters are merging and converging in the original OSort is avoided, and all the issues caused by transient clusters are thus addressed.
The equation of Pearson correlation coefficient used in spike sorting is shown as equation (2),  is the waveform of spike i arranged in temporal sequence. k is the number of samples in a spike.
is the waveform of spike i arranged in temporal sequence. k is the number of samples in a spike.  is the center of cluster a.
is the center of cluster a.  is the CC value of spike i with cluster center a.
is the CC value of spike i with cluster center a.  and
and  are the averages of spike
are the averages of spike  and cluster center
and cluster center  . The CC has a value range of [−1,1]. The value 1 indicates a very strong similarity, while −1 shows pretty poor similarity,
. The CC has a value range of [−1,1]. The value 1 indicates a very strong similarity, while −1 shows pretty poor similarity,
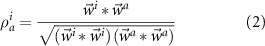
where
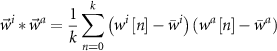
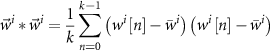
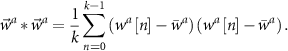
In order to demonstrate the characteristic of CC in the spike groups, the OSort dataset with typical noise level of 0.15 is sorted with CC as shown in figure 3. The temporal shapes of sorted all three spike groups are shown in figure 3(A) with different colors. The CC values of each spike with all three cluster centers are projected as shown in figure 3(B), and these three clusters are clearly separated by CC values. Figure 3(C) demonstrates the statistics results of CC values of each cluster. The pie charts in the upper of figure 3(C) count the density of the CC values that are larger than 0.8 (strong similarity) in the corresponding cluster. The results illustrate that at least 97.8% (the green cluster) of spikes have a CC value larger than 0.8 (the other two clusters are 98.8% and 98.2%) with their respective centers, which implies the spikes keep strong similarity in the same cluster. Inspired by this observation, a CC-based opt-OSort and its procedure are proposed in this work.
Figure 3. Characteristics of the correlation coefficient (CC) represented by three spike clusters from the OSort dataset [44]. (A) The spike waveform of the sorted spike groups by CC indicated in different colors at noise level of 0.15. (B) 3D projection of CC values of all the spikes in the classified cluster. (C) Histogram of CC values of all classified cluster.
Download figure:
Standard image High-resolution imageThe flow chart of the opt-OSort algorithm is shown in figure 4. The first step of the algorithm (S1) is to set running related parameters. The definition of these parameters is listed as follows:
Cnumber: the configurable maximum neural cluster number (4–6 for single-channel extracellularly recording). ρthr: CC threshold used to classify the spike into a specific cluster. Nloop1: checking point at each Nloop1 spikes. Gsize1: the minimal cluster size at Nloop1 checking point. Nloop2: checking point at each Nloop2 spikes. Gsize2: the minimal cluster size at Nloop2 checking point. Dsize: the threshold of discarded spikes.Figure 4. Flowchart of opt-OSort algorithm.
Download figure:
Standard image High-resolution imageThe typical values of these parameters used in the work are introduced in table 1. After setting the parameters, the spike sorting procedure starts to work. The Input spike (S2) is sent to the module to count the total input spike number Ntotal, and calculate the CC value ρ between the input spike and the Cnumber of cluster centers (S3). Then, the obtained Max(ρ) value is compared with the classifying threshold ρthr (S4). If Max(ρ) exceeds the ρthr, the algorithm runs assigning cluster procedure (S5–S10); else the algorithm runs creating new cluster procedure (S11–S15). The two procedures are separately introduced as follows.
Table 1. The parameters used in the proposed opt-OSort algorithm.
ParametersThe value in this paperTypical value Cnumber 44–6 ρthr0.6–0.80.6–0.8 Nloop1200Related to the firing rate Gsize144–10 Nloop21000 Nloop2 > Nloop1 Gsize25030–300 (Gsize2 > Gsize1) Dsize100Related to the firing rateAssigning cluster procedure (S5–S10): as the Max(ρ) is larger than the classification threshold ρthr, indicating that the input spike is strongly related to Max(ρ) cluster and is thus assigned to this cluster. The spike center of Max(ρ) cluster is then updated by re-calculating the spike mean, and the number of total spike N in this cluster adds one (S5).
Next, the algorithm checks if the Ntotal is the multiple of Nloop1 (S6). If not, the spike classification is completed and the algorithm will wait for another input spike (S2). If yes, the algorithm checks cluster size N in each of the sorted clusters (S7). If N is less than Gsize1, the corresponding cluster is discarded as an interference cluster. In this case, the interference cluster center and spike number N are reset to zero (S8). After that, the algorithm checks if another checking point is coming (S9), that Ntotal is multiple of Nloop2 (Nloop2 is much larger than Nloop1). If yes, the algorithm checks if existing N in all sorted clusters is less than Gsize2 (S10). If yes, the corresponding cluster center and spike number N are also reset to zero (S8); otherwise the algorithm waits for another input spike (S2).
Creating new cluster procedure (S11–S15): If the Max(ρ) value is smaller than ρthr, indicating that the input spike is not similar to all the existing clusters and a new cluster is created. Then, the algorithm checks if empty clusters are existing in all the Cnumber clusters (S11). Here, the empty cluster is defined as the cluster size N is zero. If yes, the input spike is set as the new cluster center, and the new cluster size N is set to 1 (S12); if not, the spike is discarded and the discarded spike number D is added one (S13). After that, the algorithm checks if discarded spike number D is larger than Dsize (S14). If yes, indicating that too many spikes are discarded and the whole spike sorting procedure needs to be restarted. The total input spike counter Ntotal, the Cnumber of cluster centers, and the corresponding spike counter N are all reset (S15). If not, the algorithm waits for another input spike (S2).
The proposed opt-OSort algorithm provides two loop-checking points (Nloop1 and Nloop2), which basically have the same process but with different design purposes. The first loop-checking point (at each Nloop1 spikes) usually sets a small Nloop1 and Gsize1 (in this work, checking on every 200 spikes if existing clusters size is smaller than 4), to prevent the occasionally occurring spike outliers taking the position of the Cnumber of cluster slots. Otherwise, the neural spikes are discarded due to the fact that the interference clusters may take all the Cnumber of slots, and there is no empty cluster slot left to create a new cluster and assign the true spikes. This could happen as the interference are occurring prior to the true spikes in the neural recordings (e.g. recording noise or moving artifacts), taking the precious Cnumber of cluster slots and being handled as new clusters. These interference clusters could be detected and removed in the first loop-checking process due to the abnormally-small size (occasionally occurring) compared to the true neural clusters (continually firing). The proposed opt-OSort sets a small Nloop1 value to make a quick check and remove the interference clusters as soon as possible, thereby leaving the cluster positions to the true neural spikes.
The second loop-checking point (at each Nloop2 spikes) is designed to prevent the case that the interference clusters fortunately exceed the first loop-checking threshold Gsize1 (e.g. a long period of recording noise caused spikes), which can be detected and removed at Gsize2 threshold checking. Therefore, the setting of Nloop2 is larger than Nloop1, and Gsize2 is larger than Gsize1. More than that, the second checking point could handle electrode-drifting caused recording clusters varying in the long-term recordings, in which the recording electrode is slowly drifting away from the recording position. In that case, some sorted spike clusters are gradually stopping update and new spike clusters are occurring. The opt-OSort will remove those stopped growing clusters at the second loop-checking point once detecting that their sizes are smaller than the Gsize2. The new occurring clusters are gradually taking the positions of removed clusters. This feature is demonstrated in the result section. After the two rounds of loop-checking, the left clusters are belonging to those steadily firing neurons, and all those occasionally appearing spike outliers are detected and removed.
As described in the figure 4, the proposed opt-OSort algorithm only uses Cnumber of cluster slots to perform the whole spike sorting procedure, therefore addressing all the issues caused by the large number of transient clusters when running the original OSort. Cnumber is typically less than 6 in single-channel extracellular recordings configuration and is implemented into 4 in most hardware designs [31, 33, 36, 49]. In addition, the opt-OSort could automatically reject occasionally occurring spike outliers and only those that have strongly similar shapes, with steadily firing clusters are kept. Moreover, the opt-OSort could handle electrode drifting caused neural clusters varying in the long-term recordings. Compared with the conventional OSort algorithm, the present opt-OSort could achieve not just more efficient memory usage, less computational load, and less power consumption, but also more robust for various physiological conditions and recording noises.
2.3. Hardware implementation of opt-OSort algorithmThe hardware implementation of opt-OSort is shown in figure 5, which follows the flowchart of figure 4 but with hardware logic. In this design, we assume the spikes have been detected and only consider the real-time sorting function. The designed hardware contains four cluster centers: Spike Center 1–4 (Cnumber = 4). Counter 1–4 are designed to count the spike number of the four clusters. The other running related parameters ρthr, Nloop1, Nloop2, Gsize1, Gsize2, Dsize, are implemented as registers and configured by Uart module, which is designed to communicate with the computer. The value of these registers could be flexibly changed on-the-fly by user according to the real recording conditions. The hardware opt-OSort is working as follows: Input Spike is firstly sent into Computing Correlation Coefficient module to obtain CC value ρ with 4 Spike Centers. The method employed to implement the hardware Correlation Coefficient has been introduced in previous work [34]. Input Spike Counter module counts the total input spike number of Ntotal. Ntotal works with two remainder modules (Ntotal%Nloop1 and Ntotal%Nloop2) to determine the two loop-checking points. If checking points are detected, the Comparator 3 module will automatically select Gsize1 or Gsize2 as the threshold to compare with Counter 1–4 at the same time. Smaller than selected Gsize threshold would result in the corresponding Spike Center1–4 and Counter1–4 being reset to zero. At the same time, calculated 4 CC values ρ are sent into Comparator 1 module to obtain the Max(ρ) and its ID. The value is then sent into Comparator 2 module to compare with the classification threshold ρthr, which is set by the computer through Uart module. If larger than ρthr, the Update Spike Center and Counter module would output Max(ρ) cluster ID and update its Spike Center with recalculated cluster mean. The Counter of updated Spike Center adds 1 too. If smaller than ρthr, the Update Spike Center and Counter module checks Counter1–4 value to decide if existing empty cluster center (equal to zero). If existing, the Update Spike Center and Counter module will directly save the input spike into the empty Spike Center and output its ID. If not, the input spike will be discarded and the Counter 5 will add one to count the total discarded spikes. In the meantime, Comparator 4 module would compare the Counter 5 with Dsize (the threshold of discarded spikes) to decide if too many spikes are discarded and the whole system needs to be reset. If the system is reset, the Spike Center 1–4 and related Counter1–4 are reset, and the input spike counter Ntotal is reset too. From the above description we could conclude that only simple logic is required to implement the opt-OSort. By contrast, special designs are usually required in original OSort to process a large number of transient clusters, and the complexity of designed architecture and resource usage are thus compromised.
Figure 5. The hardware implementation of proposed opt-OSort algorithm.
Download figure:
Standard image
Comments (0)