
記住我
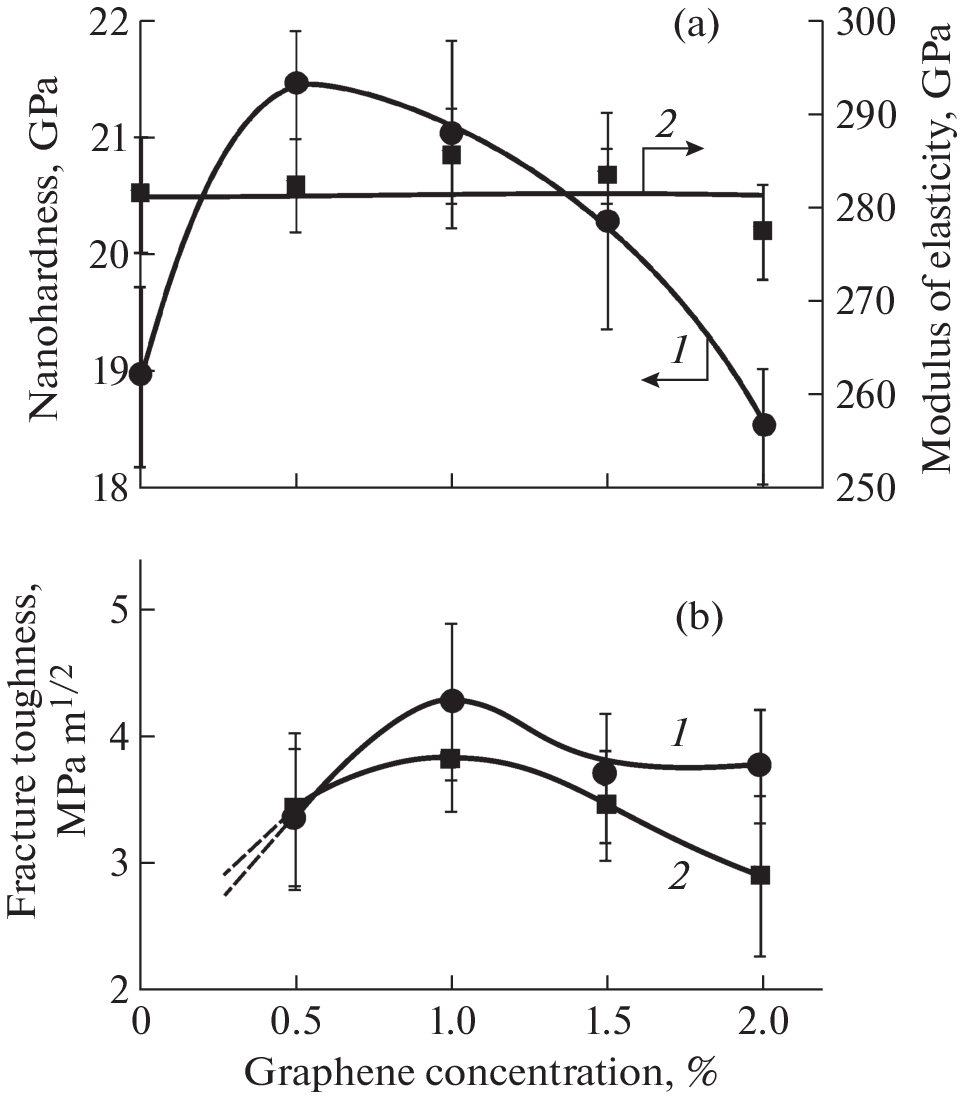


The architecture of the NGID, the software, and hardware should provide an acceptable speed for performing operations related to the search, visualization, analysis and high-performance processing of genetic information using machine-learning technologies and supercomputing. To ensure the protection of information, the NGID has identified three information-processing loops: open, confidential and special. The software and hardware architectures of each of the circuits are similar, but there are differences due to the requirements for information protection. The information and computing infrastructure of the NGID is based on the following solutions:
(i) a distributed storage system for working with genetic data;
(ii) a computing cluster for running applications and services based on containers;
(iii) a system for managing computing resources, data storage, and computing clusters;
(iv) tape system of long-term storage.
The distributed storage system provides the operation of the file system and object storage. Object storage is based on a nonhierarchical storage structure with access to objects through unique identifiers, in which data is stored as objects. This solution provides ample opportunities for storing metadata, organizing data access, and provides efficient scaling. The object repository of the NGID will contain genetic data deposited by users, as well as data obtained during the import and exchange of information with external databases.
Cloud technology is used to manage computing resources, clusters, and data storage in open and confidential circuits. This solution allows flexible management of the infrastructure of a computing cluster, the implementation of increased isolation of information-processing segments, and balancing of the load between clusters. In the open and confidential circuits, the NGID uses an adapted environment for working with containerized applications in the cloud infrastructure, certified for compliance with CNCF (Cloud Native Computing Foundation) standards and information-protection requirements in accordance with applicable law. Such an environment will provide an extended application programming interface for solving the following tasks: creating, configuring, and deleting disks, load balancing, managing external networks, setting up security groups, etc. This solution simplifies the maintenance of computing facilities. The performance estimate of total computing resources, taking into account recommendations for resources for high-throughput sequencing based on time measurement for typical processing operations, is 30 000 computing cores [3]. To use analytical programs that have increased requirements for computing resources, in particular for calculations based on graphics accelerators and operations that require a large amount of memory, a high-performance computing cluster is provided as part of the NGID open circuit. To ensure the safety of data for a long time period, a tape storage system will be used.
Supercomputer resources are used as high-performance computing infrastructure. To ensure the storage of genetic data, the system includes two storage systems: a storage system for I/O intensive tasks and a distributed long-term storage system for the archive of genomic data, based on hard disk drives. In creating the computing infrastructure, the main emphasis is placed on ensuring the fault-tolerant operation of the NGID and reducing maintenance time. NGID infrastructure components at all levels use hot standby; containerization of software applications is used [4].
Planned Volumes of Information StorageThe total size of the NGID storage is determined based on the size of storages of existing international databases. According to the European Bioinformatics Institute (EMBL-EBI), in 2021 the volume of stored data exceeded 390 PB and continues to increase [5]. Today, in the international databases of the International Nucleotide Sequence Database Collaboration (INSDC), about 10 PB of open genetic data are published, a comparable amount of closed data is reported to be stored, and several petabytes of new data are published annually [6]. Considering that the volume of publicly available genetic data that can be used by a wide range of researchers is much higher (for the Sequence Read Archive of the National Center for Biotechnology Information (SRA NCBI), the volume of publicly available data is about 45 PB) and there is a need to provide redundancy in data storage, the NGID storage with a useful volume of 50 PB is currently being considered [7].
An important feature of genetic data is the small average file size, ~1 MB. Thus, 1 PB of genetic data includes about a billion files, which greatly exceeds the capabilities of modern storage systems. Therefore, when developing the NGID, measures were taken to solve this problem: genetic data is combined into archives before being placed in a storage system, data services extract files from archives directly, and an object storage system is used that allows the arrangement of many files without performance degradation.
Data ModelTo organize the data, a modified approach is used, which was implemented earlier using the example of the INSDC, one of the most famous global initiatives in the field of genetic-data exchange, which was formed in the early 1980s [6]. INSDC members have created a global, comprehensive public domain collection of nucleotide sequences and related metadata. The data ranges from raw reads, and genomic assemblies and alignments to a variety of functional annotations. The regular exchange of data, standardized formats and, increasingly, the exchange of technology ensure global synchronicity in collaboration. Due to the above advantages, the hierarchy of metadata and their standards are used in databases not included in the INSDC, in particular, in the National Genomics Data Center (NGDC), China [8].
The top level of data organization is the BioProject, which simplifies the classification and systematization of data and metadata for all INSDC participants. A BioProject is mainly metadata about research projects that allows you to combine large amounts of scientific information, simplify its search, increase accessibility for database users, and also unite research participants in a single information context. The biosample database (BioSample) was developed to store descriptive information (metadata) of specifically biological samples, from which deposited genetic data were subsequently obtained [9]. The next (lower) level of organization in INSDC databases is the level of description of genetic data, i.e., metadata about genomic assemblies and sequencing data.
The NGID retains the levels of metadata presented in the INSDC databases and adds a new level of metadata: a biological object located in the hierarchy between the BioProject and the BioSample (Fig. 2). A bio-object allows you to link several BioSamples taken from one living organism or one cell culture, but under different conditions, at different times or from different tissues. For example, a bio-object can be metadata on a specific laboratory rat (R. norvegicus) with a description of the general characteristics of this animal, while the BioSamples will be metadata for each individual biomaterial sampling at different time intervals after exposure to medicinal substances. The introduction of a bio-object retains compatibility with the metadata of the INSDC databases, since during import this level can be restored based on the metadata of the BioSample.
Fig. 2.
Hierarchy of the NGID-model metadata. The levels of metadata that are directly related to genetic data are highlighted in gray.
Thus, each of the levels of the metadata hierarchy allows solving a separate user task: a BioProject used for searching for studies by topic and tasks, as well as structuring and linking objects of lower levels; a bio-object used for saving metadata on a specific research object with the ability to search according to attributes and structuring of samples, obtained from this object in a different way and/or under different conditions; and a BioSample used for the preservation of metadata on a specific sample of the object of study, including all the nuances of sampling and effects on the body, taking into account possible dynamic changes.
One of the most important metadata attributes is the taxonomic identifier. The NCBI Taxonomy Database, a curated database organized in the form of a directed graph which systematizes information about all domains of living organisms, was taken as the basis of taxonomy at the NGID [10]. At the beginning of 2023, the NCBI Taxonomy Database included information on more than 100 000 genera and 2 million species, and the database dynamically changes both due to replenishment (in 2022, 80 thousand new species and almost 4 thousand new genera were added), and by adapting the changes made to the main taxonomic codes [11]. The taxonomy includes seven main ranks: domain or superkingdom (eukaryotes, archaea, bacteria, viruses), phylum or type, class, order, family, genus and species, as well as intermediate ones, which allow the more accurate classification of organisms. It is worth considering that the NCBI Taxonomy Datavase is not the only one used in bioinformatic databases, for example, taxonomic classifications within the Silva-LTP (All-species Living Tree Project) project and the GTDB (Genome taxonomy database), which classifies prokaryotes based on their genomic sequences and phylogeny of marker genes, are very popular [12, 13]. The NGID provides support for several variants of taxonomic classification with the possibility of their further mutual integration.
留言 (0)