
Remember me




While data science can help in so many ways, it can cause harm too. By developing a shared sense of ethical values, we can reap benefits while minimizing harms. Based on the previous research (Kalaiselvi et al. 2020a, b, 2021, 2022a, b, Kalaiselvi and Padmapriya 2022, Padmapriya et al. 2021, 2022) on medical image analysis by the first author and related research works involving data science during MIA as discussed in the previous section, we draw the elements for developing a structured approach to facilitating an ethical data collection process during MIA.
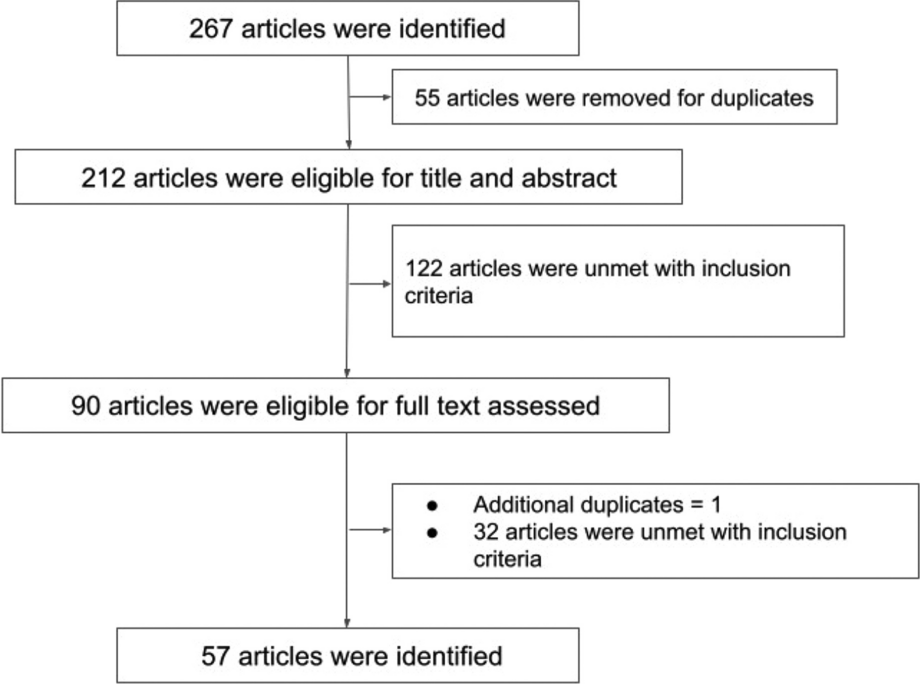
The structured approach is grounded specifically in the previous research works on applications of data science in healthcare, namely big data repositories (Xafis and Labude 2019), big data and medicines (Schaefer et al. 2019), real-time healthcare dataset (Lipworth 2019), artificial intelligence, and machine learning on a big dataset from healthcare systems (Lysaght et al. 2019; Ballantyne and Stewart 2019; Laurie 2019). This structured approach is presented below (Fig. 1) in the form of a framework. Even though it can be connected to theory with regard to data science research literature and descriptions, the goal of the framework for ethical data collection for carrying out MIA is to have a tool rather than a theory that helps justify actions or a framework that paves the way for better and deeper understanding of complicated issues (Dawson 2010).
Fig. 1
Ethical data collection framework
In a complex world, with many actors, it is often difficult to see where the problem lies and how to define limits on the use of data science. In these circumstances, using an ethical data collection framework will help the data scientists think about the ethical questions to consider as we define these limits. From Fig. 1, we observe that there are two possible sources of data—a primary dataset and a secondary dataset for conducting the medical image analysis. The medical data such as X-rays, CT scans, and MRI scans that are collected directly from the human beings are considered a primary dataset. The metadata that arises from the original dataset is viewed as a secondary dataset. It is generally considered inappropriate to use this dataset (primary or secondary) without permission. This includes recording metadata during the data collection process, such as who collected the data, what time it took place, and how long it lasted.
Concerns about data validity are not new. Anyone with basic statistics training should be able to think through the concerns we discuss. Many data scientists seem to forget these simple fundamentals. It should be noted that untimely use of data analytics may lead to erroneous inferences and findings. It is trivial that one cannot expect a fair execution of an algorithm during MIA if this algorithm uses an erroneous or invalid dataset as its input. There is no way a computer could have prejudice or stereotypes. The assumptions, model, training data, and other boundary conditions were all specified by human beings, who may reflect their biases in the data analytics outcome, possibly without even realizing it. Despite the fact that the analysis technique itself may be perfectly neutral, stakeholders have just recently started to consider how an algorithm’s dataset can lead to unfair outcomes.
Assume that you have a suggestion to enhance the process for entering patient data into electronic medical records that would reduce errors and enhance the integration of data entry with the workflow for patient care. In this scenario, when you do an experiment to test a hypothesis, the type of data you need is unquestionably prospective data, not retrospective data (i.e., pre-existing information). The prospective data is inevitable for MIA as new patients are cared for and their data recorded. Data scientists should remember that the ethical concerns for the prospective dataset and retrospective dataset would vary and permission or rights to capture and utilize those datasets for the MIA must be obtained prior to building a data model and performing analysis.
It should be noted that the prospective data collection process demands a review of dataset by the Institutional Review Board (IRB). It is also applicable to human subject-based social science research. In the current era, the use of the prospective dataset has become inevitable by data scientists as it contributes to medical research significantly. The past population is not the same as the future population. More so, MIA involving the dataset based on the past will work in the future only to the extent the future resembles the past. In these circumstances, the data scientists may have to watch out for singularities, but should also worry about gradual drift.
When discussing datasets for medical image analysis, data privacy is undoubtedly another pressing issue that comes to mind for data scientists. The roadmap to make use of it through its collection, connection, and analysis while also minimizing the negative effects that can result from the dissemination of data about human beings is a challenging task. The current need is to define rules and regulations that regulatory bodies would agree to. It should also be noted that maintaining anonymity forever is very difficult in practice.
The process of deleting identifying information so that the remaining information can never be utilized to extract the identity of any specific person is known as “anonymization” (also known by the term “anonymity”) (Xafis and Labude 2019). Considering both the data by itself and the data when combined with other information to which the organization has or is likely to have access to, as well as the measures and safeguards implemented by the organization to mitigate the risk of identification, data would not be considered anonymous if there is a space to re-identify an individual.
With enough other data, anonymity is practically impossible in practice. The diversity of datasets can be eliminated by combining them with external data. Aggregation only works when the entities being aggregated have unknown structures. In a facial recognition dataset, for instance, faces can be gradually recognized even in difficult situations like partial occlusion. The simplest way to prevent data misuse if anonymity cannot be achieved or is difficult to implement is to avoid publishing the dataset in public forums and to ensure that the data scientists are well informed about the level of consent (informed or voluntary) given by the data owners for its use during MIA.
To protect data privacy during MIA, the validity period for the usage of the collected data should be well defined, either for the purpose of research or to get new insights into the diseases or disorders. Healthcare centers or medical research laboratories legitimately collect data as part of performing MIA. However, it will make an effort to not use the data in egregiously inappropriate ways in order to maintain the consumers’ trust. But after the tests, this dataset becomes an asset that is likely sold to a different party with malicious intentions. Thus, to ensure data privacy, either the collected data must be destroyed, not sold, after a stipulated time period, or the consent for its usage should be explicitly mentioned in the agreement approved by the data owner during the data collection process itself. Modern data science systems must deal with data privacy by design. As there are too many players in the race to exploit the dataset for personal or business gains, it should be noted that the data sharing is contractual and not based on trust.
For utilizing a sensitive dataset extracted from medical records, such as de-identified data used for MIA, data scientists must first go through a straightforward licensing process. This could be carried out by means of signing a contract or agreement with the data owners or other trusted parties who hold the data repository. When it comes to utilization of the collected dataset, before commencing the medical image analysis, the data scientists should verify whether either informed consent or voluntary consent exists for the chosen dataset. By “informed consent,” we mean that the human subject must be made aware of the experiment, must give their permission for it to proceed, and must be given the option to revoke their consent at any time by notifying them. However, consent can be obtained voluntarily, i.e., without coercion for the dataset to perform MIA without any hassle. Ideally, any data science project that involves human subjects should necessarily consider the feedback from the Institutional Review Board (IRB).
The IRB comprises diverse members, including non-scientists, and approves human subject study, balances potential harm to subjects against the benefits to science, and manages necessary violations of informed consent. Regarding voluntary consent, i.e., voluntary disclosure, the stakeholders (data owners) should be informed that anything they disclose voluntarily to others has much less protection than anything they keep completely to themselves. For example, the telephone company must know what number you dialed to be able to place the call. Hence, when you have disclosed this metadata to someone, even if it is not the content of your conversation, there is always a possibility that this may quickly become problematic due to ubiquity.
Data scientists should abide by the laws framed by the medical council in different countries (USA, European Union, India, Australia, and so on) while retaining datasets on human subjects for future reference and usage. After some years, if such medical records are available on the public domain through published research papers, research reports, or design patents, then this would impact the privacy of the data owner and may later lead to legal hurdles as well. Thus, knowing how to remove such records should also be a matter of concern for data scientists during MIA.
Between voluntary consent and informed consent, there will always be a trade-off. It should be emphasized that while “voluntary” consent is given by the stakeholders to carry out a desired action when necessary, “informed” consent is based on information that is concealed in numerous pages of fine print. Facebook explicitly tells users in its agreement that it may collect user data for research purposes. But Facebook got its user’s dissatisfaction for irrelevant usage of their dataset or due to the limitations on the agreement (informed consent). Hence, it is observed that informed consent and the voluntary consent when used wisely would ensure data privacy and facilitate the data scientists in collecting and using the data for effective MIA ethically. However, if it is used otherwise, data science can result in major asymmetries during MIA. In practice, many user agreements are “all-or-nothing.” This amounts to data owners (person who holds accountability for a specific dataset) completely giving up control of shared data to get any service benefits at all. Later, such owners often complain about the loss of privacy. Hence, the ideal solution to deal with this situation would be for data scientists to provide graduated choices, so the data owners could make the tradeoffs they like, for example, incognito browsing.
Another problematic area in the ethical data collection process is “repurposing.” By “repurposing,” we refer to the collection of a dataset for one objective during MIA and later using it for a different objective without obtaining consent from the data owner. It should be noted that “repurposing” can be problematic. Imagine that one gives their dataset to a medical team to obtain a specific service. However, they may not want their dataset (medical records) to be used for other purposes by the data scientists during MIA, nor do they permit them to share the data with others. This means that the data owner’s consent can often be limited to disallow repurposing, thereby indicating that the “context” matters during the data collection and its subsequent usage by the data scientists.
Repurposing is also occasionally inevitable for carrying out medical research using data science or artificial intelligence to generate new insights on certain diseases or disorders. For instance, a patient may willingly allow the repurposing of their medical data with a hospital to receive better care. However, the specific research questions may not be known to the medical team at when this particular patient receives care at the hospital. This is referred to as retrospective data analysis in data science during MIA.
Comments (0)