
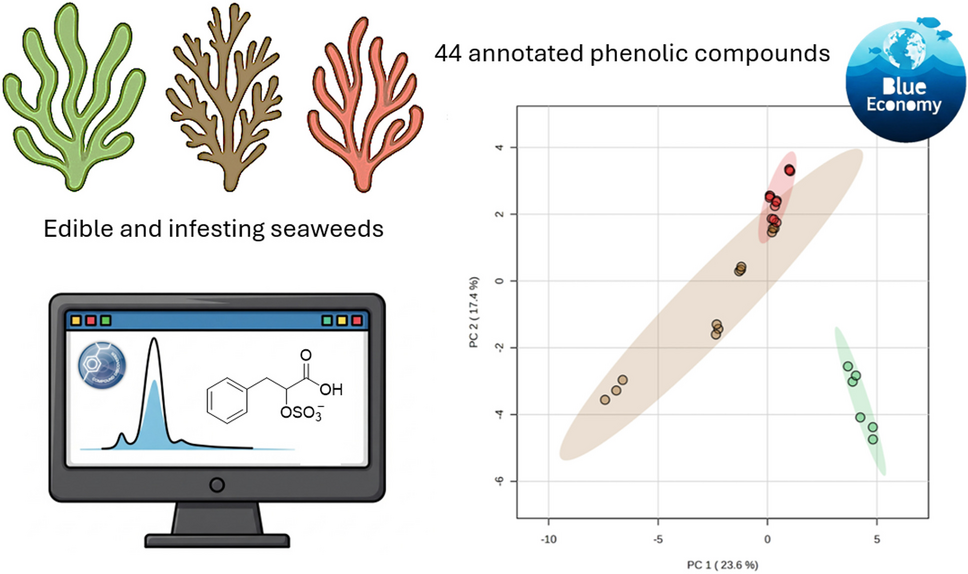
Remember me

As already mentioned, bias and variance are the most important performance criteria of a statistical estimator. Both quantities should of course be as small as possible, although there might be some trade-off in the sense that a larger bias might be acceptable when it comes along with a correspondingly smaller variance.
The aim of this work is to deliver results based on theoretical considerations and extensive simulations. One of the goals is to provide approximation formulas for bias and variance as these formulas cannot only be used to better understand the behavior of the different approaches and to judge their performance, but are also useful in practice, i.e., to calculate confidence intervals for the unknown concentration \(C_0\). To the best of our knowledge, our publication contains for the first time a complete set of formulas for all four investigated standard addition approaches for both bias and variance which are ready to use for the practitioner since all necessary components are known/can be estimated using linear regression. In addition, a standardized and widely used notation is applied to improve the accessibility of the formulas.
Besides the use of formulas, bias and variance of the estimator can be determined by applying Monte Carlo methods, in the following denoted simulations. Such simulations utilize the generation of a huge number of synthetic random samples to yield numerical results (see [19]). They do not rely on the approximation formulas, but are based solely on the relationship given in formula (1) to randomly generate observations (“measurements”) used for calculating estimates and CIs for \(C_0\) for all four approaches in parallel. By iterating this process t times, t random estimates and CIs for each approach are generated which can subsequently be used to calculate bias and variance of \(\hat_0^x, x=e,i,r,n,\) and coverage probabilities and average widths of the respective CIs. These simulation results cannot only be used to judge and compare the performance of the several approaches, but can also be used to validate the approximation formulas since the results of simulation and proper approximation have to be very close.
We would like to point out that although [16] analyze the same standard addition approaches for bias and variance, there are significant differences between our work and theirs. In contrast to our work, [16]do not provide formulas for the bias and the formulas provided for the variances in the case of the interpolation (Eq. (7)) and the normalization approach (Eq. (12)) contain quantities which are not easy to compute. In particular, these quantities are the following: in Eq. (7), it is \(S_, S_\), and \(S_\), and in Eq. (12), it is \(S_\), which would have to be stated explicitly so that Eq. (7) and Eq. (12) can be applied without further elaboration. [16] leave it open how they are to be calculated. In addition, we based our simulations on the usually applied basic assumptions of standard addition (homoscedastic and normally distributed errors, blank value not significantly different from zero, linearity). Due to these standardized conditions, deviations from the basic assumptions are excluded which allows a clear statement to be made. In contrast to our approach, real-world data are often overlain by the characteristics of the different instrumental methods used which can obscure the underlying relationship. If discrepancies between experiment and theory occur, this indicates that additional factors play a role that lead to deviations from the basic assumptions. This is also argued by [16], who are extensively discussing the potential influences of the different instrumental techniques on the outcome of their comparisons. However, neither [16] nor this work makes the other work superfluous, as theory and experiment are always complementary methods of investigation, both of which are indispensable. This means that theory must be tested with experiments and, conversely, theoretical considerations are necessary to understand and model the observations from the experiments and make them accessible for general application. The discrepancies between experiment and theory should provide the impetus for further research and improvement of the method (e.g., applying weighted regression in the case of heteroscedasticity).
In the following, consider that \(n_r\) different series are measured and that each series r consists of \(n_e\) single observations \(Y_, r=1,...,n_r, i=1,...,n_e\), i.e., the total number of observations \(n=n_r n_e\). Therefore, the used spiked concentrations in vector notation are \(\varvec=(x_,...,x_,x_,...,x_,x_,...,x_)\), and the vector of the measured responses is \(\varvec=(Y_,...,Y_,Y_,...,Y_, \) \( Y_,...,Y_)\). Keep in mind that \(x_=0\) for all \(r=1,...,n_r\) and that for all \(i=1,...,n_e \ x_=x_\) for all \(j,l = 1,...,n_r\).
Table 2 Approximation formulas for \(\sigma ^2__0}\), the variance of the estimator \(\hat_0\)Approximation formulasSince no closed forms for bias and variance of the estimators for \(C_0\) exist, we need to resort to approximation formulas to enable the calculation of approximate values for these quantities. To derive these formulas, let the errors be normally distributed and homoscedastic and \(y_:=\beta _0 + \beta _1x_\) denote the expected value of a measurement given spiked concentration \(x_\). Furthermore, define
$$ S_:=\sum _^n (x_i - \overline)^2, \ S_:=\sum _^n (y_i - \overline)^2, \ S_:=\sum _^n (x_i - \overline)(y_i - \overline). $$
By making use of Taylor expansions (propagation of error), we get the approximation formulas for bias and variance of the different estimators for the unknown concentration that can be found in Tables 1 and 2.
Some of these results can already be found in literature or have, where not available, been derived by the authors. The derivation can be found in the supplementary material.
Note that these formulas contain the true parameters of the underlying relationship, e.g., \(\beta _0\) is the true but normally unknown y-intercept, and \(\sigma ^2__0}\) is the true variance of its estimator. Of course, the true parameters are known in theoretical considerations and simulations, but when these formulas are used in practical applications, these unknown parameters have to be replaced by proper estimates.
Keep in mind that a thorough mathematical analysis with respect to the evaluation of the goodness of the approximation formulas as well as of the performance of the CIs based on these formulas would be extremely difficult or perhaps even impossible. Also, a respective evaluation based on just one dataset is not possible. Therefore, extensive simulations have been employed to investigate the performance of the approximation formulas and of the respective CIs. These simulations have been performed by utilizing the programming language
 [20] (R version 4.2.3) which has also been used to create all figures shown in this work. There has been good agreement between the results gained by the simulations and the approximation formulas indicating the validity of the derived formulas.
[20] (R version 4.2.3) which has also been used to create all figures shown in this work. There has been good agreement between the results gained by the simulations and the approximation formulas indicating the validity of the derived formulas.

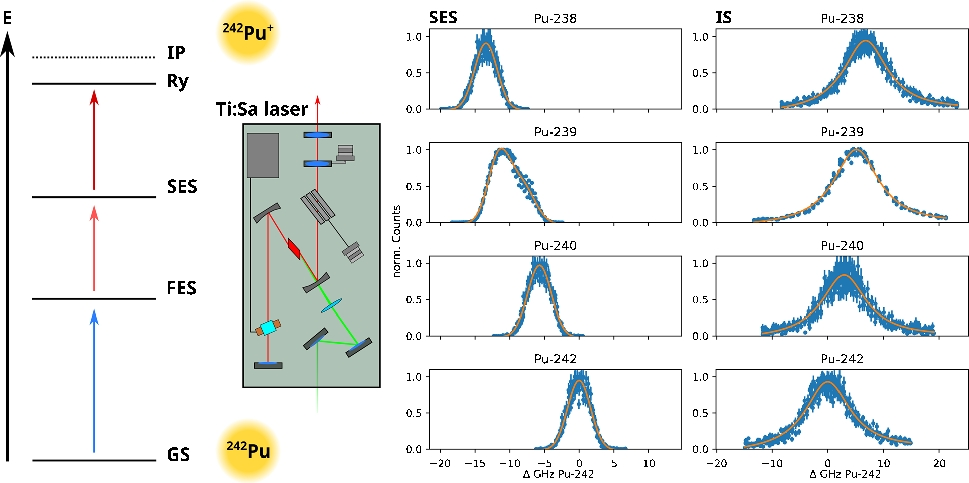
Histograms showing \(10^4\) simulated estimates for \(C_0\) for all four approaches. Estimates given in \(\mu g/g\). The simulation is based on the parameters which are deduced from the FAES dataset for Na given in Table 4 (for more information on the simulations, see text below)
Table 3 Application of the different approaches and the respective approximation formulas to the FAES dataset [13]Real-world example and simulationsThis subsection provides in addition to the analysis of a real data set the results of some simulations based on this data set. Especially, the simulations serve two different purposes, firstly to validate the approximation formulas by showing that the approximations and the simulations yield reasonably close results and secondly to enable the comparison of the different standard addition approaches.
The real-world example is taken from the paper of Gonçalves et al. [13]. They compared the extrapolation approach and reverse regression for Na and K determination in biodiesel based on measurements generated by applying FAES. The results of the analysis of these FAES data with respect to all four approaches can be found in Table 3 which shows estimates for \(C_0, \sigma ^2__0}\) and the bias and also the lower and upper bounds of the CIs, as well as their width. These estimates are denoted \(\hat_0, s__0}, \widehat, CI_l, CI_u\) and CI width.
In the case of the FAES data, the assumption of homoscedastic errors seems to apply. Therefore, the derived formulas have been used to estimate bias and variance for all considered methods by replacing the true (unknown) values of the parameters of the underlying relationship by the respective estimates. The variance estimates \(s^2__0}\) have further been used to calculate the confidence intervals which has been done based on the following assumptions: Since the estimator \(\hat_0\) can be assumed to be approximately normally distributed (see Fig. 3), we assume that \(\frac_0 - C_0}_0}} \sim t_}\), i.e., that this fraction is distributed according to Student’s t-distribution with \(n - n_p\) degrees of freedom (df). \(n_p\) equals the number of estimated parameters, i.e., \(n_p=2\) for all approaches (but see the discussion on the normalization method). Therefore, the proper confidence interval should be given by \(\hat_0 \pm s__0}t_\) with \(1-\alpha \) denoting the chosen confidence level of the CI and \(t_\) denoting the \(1-\alpha /2\) quantile of the t-distribution with \(df = n - n_p\).
Furthermore, the FAES data are also used to deduce the parameters for the simulations whose results are shown in Table 5. These parameters are estimated by applying linear regression to the FAES data and are shown in Table 4. For these simulations, also, the spiked concentrations \(\varvec\) chosen by Gonçalves et al. are used, which are as follows: \(n_e=n_r=5\) and thus \(n=n_en_r=25\) with \((x_,...,x_)=(0, 11.4, 23, 34.5, 45.9)\) and \(r=1,...,5\).
Table 4 Elementwise estimated parameters for the FAES dataset [13]Table 5 Results of applying the approximation formulas and simulations (\(10^4\) iterations) to the parameters (Table 4) deduced from the FAES dataset [13]All simulations (as already stated, many more than those whose results are shown in this work have been performed) are based on the assumption, that the true parameters (y-intercept \(\beta _0\), slope \(\beta _1\) and measurement error \(\sigma \)), and therefore, the true relationship and especially \(C_0\) is known. With respect to the simulation results in Table 5, this means that \(\beta _0\), \(\beta _1\) and \(\sigma \) have been chosen to be \(\hat_0\), \(\hat_1\) and \(\hat\) from Table 4. Therefore, \(bias_\) and \(\sigma __0 appr}\) shown in Table 5 approximating the true values of bias and \(\sigma ^2__0}\) can be calculated just by plugging in the known parameters together with the chosen spiked concentrations given by \(\varvec\) into the respective formulas in Tables 1 and 2.
To get robust simulation results, each of these results is based on the outcomes of a large number K of iterations which has been chosen to be \(10^4\) in this case. In each such iteration \(k, k=1,...,K,\) the spiked concentrations \(\varvec\) together with the parameters are used to generate \(n=n_rn_e\) new synthetic random measurements by applying the relationship \(Y_=\beta _0+\beta _1x_+\varepsilon \) with \(\varepsilon \sim N(0,\sigma ), \ r=1,...,n_r, \ i=1,...,n_e\). Each of these newly generated sets of n measurements \(\varvec=(y_,...,y_)\) is subsequently analyzed using the four standard addition approaches to estimate \(C_0\) and also plugging in the proper estimates into the formulas given in Table 2 to calculate CIs, i.e., in each iteration k, there is a new estimate \(\hat_\) and also a new CI, \(CI_k\), for \(C_0\) calculated. Therefore, the quantities found in Table 5 are calculated as follows:
$$\begin \overline}_&=\frac\sum ^_\hat_, \quad bias_=C_0-\overline}_, \quad \sigma ^2__0 sim}\\&=\frac\sum ^_(\hat_-\overline}_)^2, \end$$
\(CI_\) is the fraction of all \(CI_k\) covering \(C_0\), and \(\overline_\) is the mean width of all \(CI_k\).
Comments (0)