In this study, we evaluated the prognostic accuracy of EWS to predict in-hospital mortality, 30-day mortality, and ICU admission, considering the source of infection. To our knowledge, this is the first study to stratify the performance of EWS by infection type. Our results reveal that the predictive accuracy of EWS varies according to the infection source, highlighting the importance of considering infection type in clinical risk assessment, a feature that is rarely explored. This unique aspect of our analysis provides valuable insights into how EWS might be optimized for different clinical contexts, emphasizing the need for more personalized approaches in risk stratification.
In the case of LRTI, the NEWS was best in predicting in-hospital mortality (AUC = 0.79) and the qSOFA (AUC = 0.70) had the lowest performance. The performance was relatively consistent across the different EWS, almost always among the best performances, and never the worst in any of the EWS. For the UTI the best predicting in-hospital mortality was the NEWS-2 (AUC = 0.73), and the lowest MEWS (AUC = 0.64). Abdominal infection has the best performance in predicting in-hospital mortality for the NEWS, NEWS-2 and MEWS (AUC = 0.86, 0.86 and 0.82 respectively), however, it was the second lowest for the qSOFA (AUC = 0.64). Overall, calibration was good across all scores, except for qSOFA in different subgroups across the different outcomes (Tables S5-S7, Figures S1-S12). This is likely due to the limited number of variables in qSOFA, reducing its ability to accurately capture varying risk levels. These findings are particularly notable because none of these EWS were developed with a specific focus on the infection source, and some were not even exclusively designed for patients with infections. This highlights a potential limitation of using universal EWS across diverse infection types, as a “one-size-fits-all” approach may compromise accuracy for certain infections [9,10,11]. In addition, our cohort includes patients with COVID-19 infections, which was not considered when these EWS were developed. Despite this, the proportion of patients with LRTI were comparable to those reported globally in the pre-COVID era [21,22,23], from the 548 patients with LRTI, only 43 (7.85%) were positive with COVID-19. This reinforces the robustness of our results and underscores the need for future EWS development to consider the infection source, as it significantly influences the predictive accuracy of these scores.
Another important consideration is the accuracy of diagnoses at the ED and the timing of calculating EWS considering the dynamic nature of variables included in these scores. These are critical factors, particularly in elderly patients with multiple comorbidities, where initial diagnoses may be unclear, or competing diagnoses may exist. Relying solely on ICD-10 data introduces some uncertainty, as diagnoses often evolve during a patient’s hospital stay. To minimize the risk of missing relevant cases due to miscoding, we included not only the ICD-10 codes for confirmed infections but also those used as working diagnoses or suspected infections. Additionally, we used the broadest possible level of ICD-10 classification to identify “infection” (Table S1). Early identification of the infection is crucial, as a consequence, the timing of EWS calculation may affect its performance in the risk stratification process, particularly in elderly, and highly comorbid patients. This underlines the relevance of more dynamic and flexible tools, particularly in patients with frailty and others at higher risk for deterioration.
Although there is no direct comparison of the performance of EWS based on the source of infection, previous studies have demonstrated a difference in prognosis depending on the site of infection and the type of microorganism [24, 25]. For instance, Oduncu et al. compared qSOFA, SIRS, and NEWS scores. Their cohort had a higher ICU admission rate (17.3% vs. 7% in our cohort) and higher 30-day mortality (18.1% vs. 10.1%). Although they did not directly compare the infection source with the performance of the scores, they did present outcomes based on the infection source. For example, in their cohort, respiratory infections accounted for 39% of cases, with a mortality rate of 23.2% and an ICU admission rate of 30.9%. UTI comprised 23.9%, with a mortality rate of 10.8% and ICU admission rate of 9%. Abdominal infections made up 17.3% of cases, with 12.5% mortality and 5% ICU admissions. Soft tissue infections accounted for 6.9%, with 6.3% mortality and 3% ICU admissions. Other infections made up 6.6%, with 29% mortality and 12.9% ICU admissions, while undetermined infections comprised 6%, with 32% mortality and 17% ICU admissions [26]. Notably, our cohort had a higher representation of urinary tract infections (30.7%). Despite this, their results, like ours, show that mortality varies depending on the infection source, further suggesting that sepsis prediction scores should consider the origin of infection for more accurate assessments.
This discrepancy raises a critical question: should we strive to develop a universal EWS that performs equally well across all infection foci, or should we tailor EWS to specific types of infections? A universal score would simplify clinical protocols but may compromise accuracy for certain infection types. On the other hand, specialized scores could provide more precise predictions but add complexity to clinical decision-making. For instance, our data show that the performance of EWS for predicting in-hospital mortality for LRTI falls between those for abdominal infections and UTIs. Given that abdominal and UTI impacts on respiratory variables are more comparable, the differences in EWS performance underscore the need for tailored approaches. Consequently, our results could contribute to the development of a new sepsis scoring system where the type of infection will be considered alongside other prognostic factors. One potential solution to this issue could be the implementation of a hybrid model, where a general EWS is used initially, followed by infection-specific adjustments once the infection source is identified. This approach could balance the need for both simplicity and accuracy. Additionally, machine learning algorithms could be employed to dynamically adjust the weight of different variables in the EWS based on real-time data, potentially providing a more nuanced and accurate risk assessment for diverse patient populations. Further research into the development and validation of such adaptive scoring systems is needed.
One of the limitations of our study was the sample size. We based the difference of 0.6–0.7 in the discrimination (AUC-ROC) of qSOFA in a cohort of UTI versus LRTI on information from Madrazo et al. and Kolditz et al. [27, 28]. However, this difference between AUC may not hold clinical significance. Furthermore, the small sample size in our study, particularly in some subgroups, resulted in limited statistical power, increasing the likelihood of a type II error. However, despite these limitations, we were still able to demonstrate notable differences within these smaller subgroups, such as in patients with abdominal infections. Thus, although the relatively small size may have precluded us from identifying more differences between groups, it does not affect the conclusion that the performance of the EWS depends on the type of infection. Importantly, these results highlight the need for further research and should encourage other research groups to investigate this area more comprehensively with larger cohorts to validate and expand upon our findings. Another potential limitation is that we only included patients with suspected infections at the ED, but did not include patients diagnosed with nosocomial infections. The study was conducted at a single, tertiary university hospital, which serves as a reference for the northern region. However, the large catchment region of our hospital leads to a diverse case-mix of both academic and non-academic care, which increases the generalizability of our findings to other, non-academic centers. Finally, concerning our outcomes, the use of all-cause in-hospital mortality as the primary outcome, instead of infection related mortality, might have led to an overestimation of the actual mortality attributable to infections, as patients could have died to various other causes. Nevertheless, our mortality rate aligns with those reported in previous studies [12, 29]. It is also important to note that the median length of stay in our cohort was only 4 days, largely due to our healthcare system’s focus on resolving as much as possible outside the hospital, supported by the necessary infrastructure to do so safely. This minimizes the potential for not infection-related factors to influence our results in-hospital mortality. Regarding one of our secondary outcome, the EWS used in any hospital may affect ICU admission based on local guidelines in place. However, at the ED in the UMCG we use the Emergency Severity Index (ESI) as triage tool and do not have an additional EWS. The decision to admit a patient to the ICU, is not based on triage urgency, but depends on the physician’s decision. The EWS in use at wards in the UMCG is a modified MEWS that includes the following additional criteria beyond the original model: (1) urine production < 75 mL in the last 4 h and (2) any concern raised by healthcare staff regarding the patient’s status. The UMCG-MEWS did not outperform other EWS systems in predicting ICU admissions in this cohort. This may reflect limitations in its design or compliance with its use. Although the UMCG-MEWS score informs the nurse when to call the physician, no protocol at UMCG ties triage urgency or MEWS directly to ICU admission. Hence, discrepancies between predicted and actual ICU admissions likely stem from variation in clinical decision-making and adherence to EWS. These observations highlight the complexity of relying on a single scoring system and the need for ongoing evaluation of performance in real-world settings.
One of the strengths of our study was the collection of prospective data, resulting in fewer missing values and higher quality data. Additionally, we included calibration in our analysis, a crucial component, often overlooked in similar studies. Calibration assesses the agreement between predicted and observed outcomes, which is essential since poor calibration can lead to risk misclassification. Even a model with good discrimination (e.g., high AUC) can be poorly calibrated if predicted probabilities do not align with observed event rates across risk levels. In this study, we aimed to assess both discrimination and calibration to provide a comprehensive evaluation of model performance (Appendix 2, Tables S-S7, Figures S1-S12).


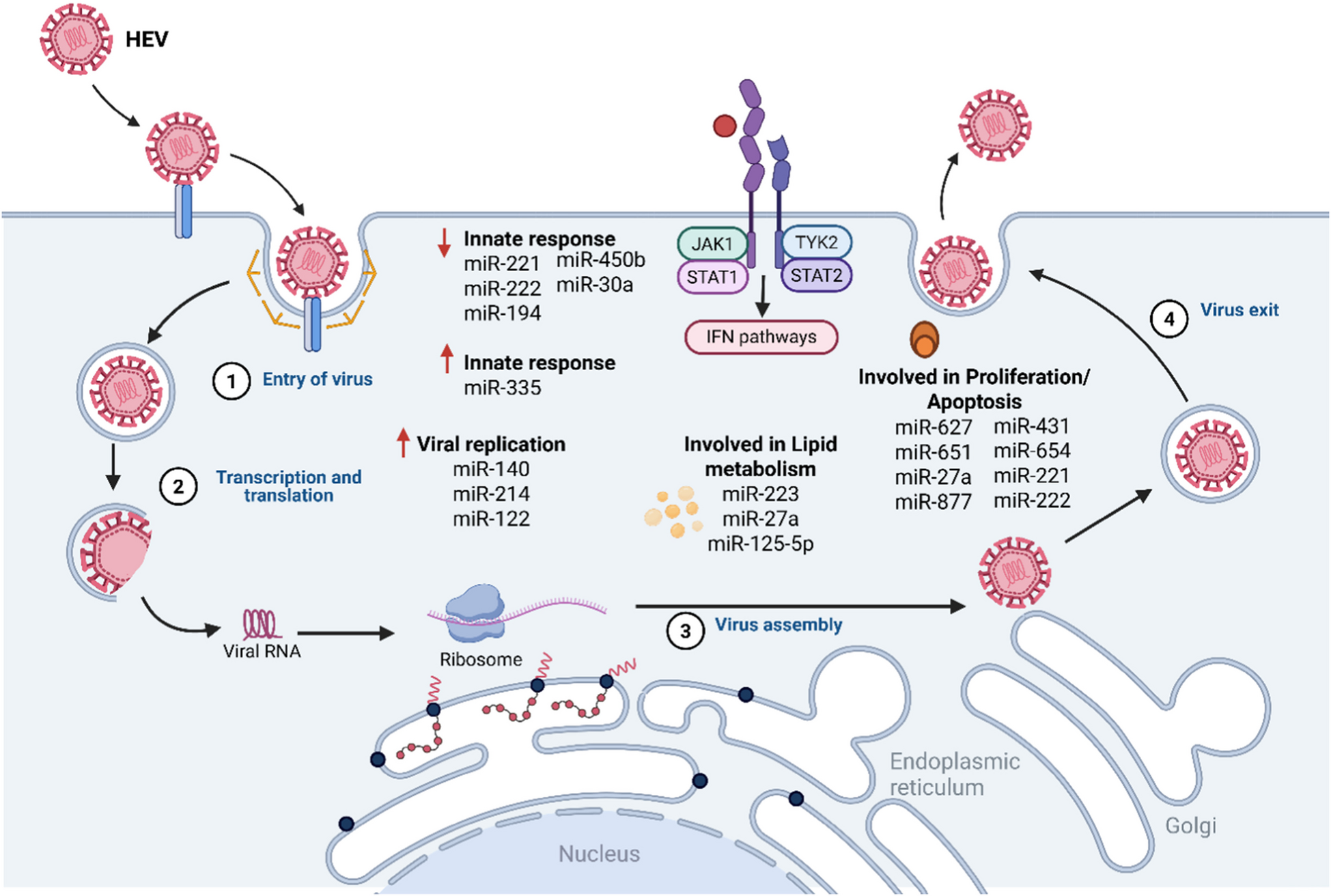

Comments (0)