
Remember me

Detection, and analysis of, spontaneous synaptic currents is a frequently chosen method by experimental neuroscience researchers to evaluate the properties of synapses (Biane et al., 2021; Williams and Featherstone, 2014; Vyleta and Smith, 2008). Recordings of spontaneous synaptic currents or potentials are technically simple to acquire but can be laborious to analyse. Whilst individual synaptic currents at typical central synapses are reported to be approximately 10 pA (Auger and Marty, 1997; Glasgow et al., 2019), this is likely to be an overestimate as only the larger synaptic currents are detectable above the noise and vary substantially between labs, even where the conditions of the experiments are largely consistent. Discerning synaptic currents from background noise can be a particularly challenging task and typically involves some element of subjective manual selection by an experienced researcher. The challenges in the analysis process are exemplified when the researcher is required to scrutinize hundreds, if not thousands, of events, increasing not only the duration of the analysis but also the chance for human error.
To avoid the burden of manually screening hours of recording time to identify synaptic currents, several semi-automated solutions have been developed to break the process down into two tasks: (1) automatic detection of plausible candidate synaptic currents, and (2) manually scrutinizing the detections, for example, labeling the flagged candidate events as true or false positive detections. The initial automatic step has largely been achieved using one of two main approaches: those that require a template waveform of a synaptic current and those that do not. The template approach computes some measure of “likeness” of the recording at each time point to the template waveform. The “likeness” of the template can represent how well it fits to the data as it slides from one sample point to the next along the recording in the time domain (Clements and Bekkers, 1997; Jonas et al., 1993). Alternatively, “likeness” can be derived by deconvolution and represents how well frequency components in the template waveform match those in the recording at each point in time in the recording. FFT-based deconvolution involves converting the recorded wave and a convolution kernel (i.e., a template waveform of the synaptic current) to the frequency domain, dividing them, and then transforming the result back to the time domain. The result is a detector trace that contains what resembles a series of sharp spikes, each of which indicates the time of onset of a synaptic event. Generally speaking, frequency domain deconvolution is more robust than time domain template matching in cases where synaptic currents are (partially) overlapping (Pernía-Andrade et al., 2012). The developments of these event detection methods (amongst others, e.g., Merel et al., 2016) have both helped to improve the sensitivity of detecting small but “true” candidate synaptic currents, and provide some screening of large, but otherwise implausible waveforms in the recordings.
Whilst automatic detection methods proceed much faster than manually screening the recordings, the classification of the synaptic currents based on those detection criteria alone is seldom sufficient in accuracy to convince users that manual intervention is not required. Many users, experts through years of manual analysis, do not trust automated or semi-automated approaches due to the output event selection not conforming to the opinion of the user. Although most commonly used software packages implement one or more of the above automatic detection methods, they also enable users to follow this up by editing the detection and/or classification of flagged candidates. However, expert manual classification of candidate synaptic currents introduces other issues, particularly with respect to the ability to reproduce how recordings are analyzed and the results obtained from them. Furthermore, many of the automatic detection methods depend heavily on setting a detection threshold (Ankri et al., 1994; Maier et al., 2011), the decision of which is effectively a compromise between true positive and false positive detection rates and therefore also influenced by the workload anticipated by the user to screen candidates during manual classification. A solution to these problems is to harness recent developments in rapid machine learning methods to learn and emulate our classification strategy. Not only does this have the potential to save users time and effort by dispensing with most (if not all) manual screening tasks, but it also opens the possibility of using common or shared models for event classification. Since computers are not nearly concerned with how many candidates need classifying, we can also compromise less on the choice of the detection threshold by setting the threshold lower.
An the task of classification can be automated using computers via an approach known as machine learning. Machine learning aims to fit models to data using statistical algorithms. There are two broad categories of machine learning, and then a multitude of classifications thereafter, which are reviewed extensively elsewhere (Greener et al., 2022). At the most basic level, machine learning can be supervised, requiring user-labeled training data, or unsupervised, where the model fitting is done independent of user-labeled training data. The advent and development of machine learning offer a potential solution to increase the accuracy and reliability of synaptic event detection whilst also decreasing the time required to perform this step. The use of machine learning in synaptic event detection is expected to remove both human errors and avoid the possibility of unconscious human bias when analyzing data from different experimental conditions. Indeed, synaptic event detection software utilizing machine learning has emerged recently (Zhang et al., 2021; Pircher et al., 2022). However, several forms of machine learning can require extensive training sets and be exceptionally computationally demanding, limiting their applicability in a basic research environment. Furthermore, the existing tools are not distributed with a graphical user interface to facilitate users to engage with the process of training a machine learning model.
The problem of manually screening candidate synaptic events is essentially a classification problem, which humans solve presumably by considering many visual features in the waveform (e.g., shape, scale, etc.). Random forest classification algorithms are particularly well suited to such binary classification problems, where a set of (largely uncorrelated) features of the events can be readily defined and measured. Briefly, this algorithm consists of generating multiple decision trees with variations between them. Whereas a single decision tree tends to be overfitted to the training dataset and thus change dramatically on a new dataset, the ensemble classification from multiple decision trees in a random forest is less prone to overfitting. The problem of overfitting is partly overcome by generating each decision tree from a replica of the data generated by random sampling with replacement (i.e., bootstrap resampling) from the initial data. Additionally, only a random subset of the predictors, alternatively called features, for the final classification is applied within each decision tree. Not only does this further overcome overfitting bias, but it also aids in lessening the impact of predictor over-emphasis. In the specific example of synaptic event detection, the dataset would be the pool of possible events, and the predictors could be amplitude, decay, halfwidth, etc. Thus, when applied to synaptic event detection, random forest classification can offer more robust ways of classifying events. Random forest classification algorithms are just that—classification algorithms, not detection algorithms, and therefore they require candidate events to first be detected. One particularly robust detection methodology is a deconvolution-based methodology first proposed by Pernía-Andrade et al. (2012). In this approach, FFT-based deconvolution is achieved in the frequency domain, whereby the resultant deconvolution wave represents how well the frequency components of the recorded signal match the event template at each point in time. A threshold is then set on this deconvolution wave, and events are proposed if the peak of the deconvolution wave passes this threshold. FFT is an implementation of the discrete Fourier transform (DFT) in which the relationship between the time domain and the frequency domain is revealed; however, it is much more computationally efficient.
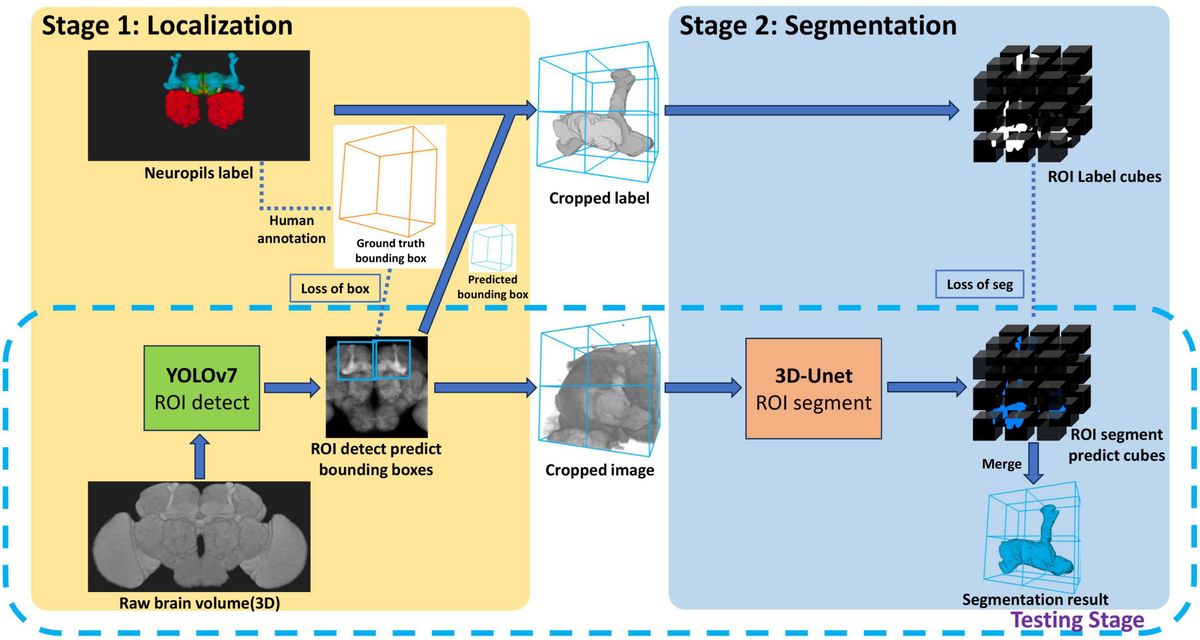
In this article, we show that, following FFT-based deconvolution, a simple machine learning paradigm can effectively be applied to the problem of classifying synaptic events during the analysis of spontaneous synaptic currents. Specifically, FFT-based deconvolution is used initially to identify candidate events before either training a random forest-based machine learning model or applying a previously trained model to the classification problem on new data. Importantly, the users have the option to control the generation of the model to reproduce their classification in a reproducible way. The software was developed in MATLAB and is accompanied with a cross-platform graphical user interface (GUI) that is intuitive to use and open source. In terms of software development, Eventer provides a framework with opportunities for tuning the existing Random Forest implementation (e.g., feature set) or even adding different types of machine learning for classification (Zhang et al., 2021; Pircher et al., 2022; Wang et al., 2024; O'Neill et al., 2024). In Section 3, Eventer is shown to be able to accurately reproduce manual detection of synaptic currents and do so in only a fraction of the time. Furthermore, the use of a single conserved model trained in Eventer can increase the consistency of analysis between users. As such, the online model repository and website created to enable users around the world to deposit models of their own and use models of others are highlighted. This article outlines the user workflow for Eventer, provides a basic description of how it works, evaluates its ability to overcome some of the issues around consistency and reproducibility of analysis, and discusses various machine learning approaches that have been described recently for the purposes of synaptic event detection.
1.1 Eventer workflows: GUI 1.1.1 InputThe GUI for the Eventer synaptic event detection analysis software was written in MATLAB's “Appdesigner.” MATLAB-based GUI can be compiled for most commonly used operating systems, thus making Eventer cross-platform. In addition to being cross-platform, Eventer also supports a wide range of the most commonly used formats in electrophysiological experiments (Table 1). Multiple file format support is largely provided by the “ephysIO.m” code written by Penn A. (2024).
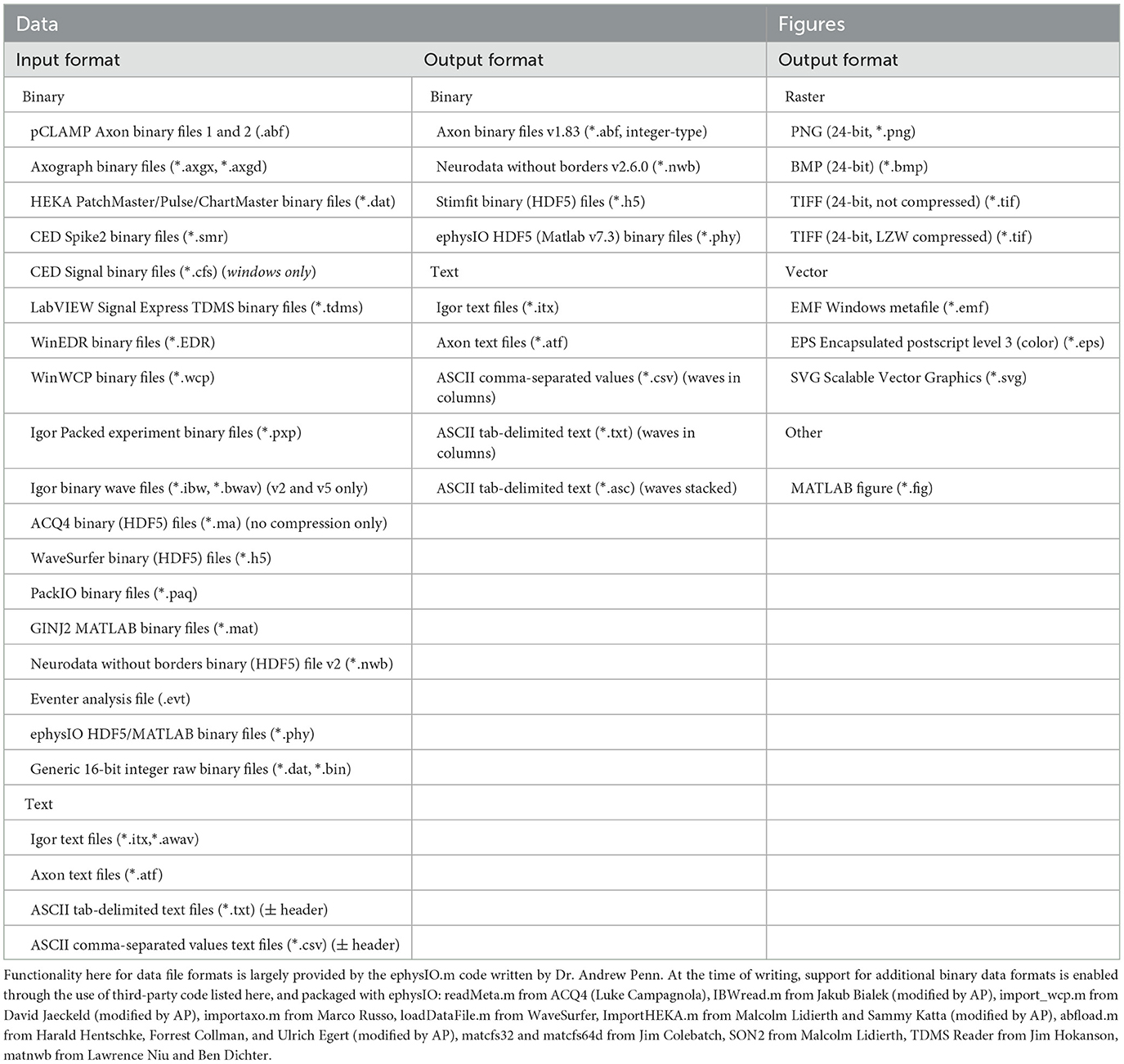
Table 1. The supported file formats for data input, output and figures within Eventer.
A suggested workflow for working with Eventer is then presented in Figure 1. Before selecting the raw data file, the user is advised to consider whether the data file being loaded contains either continuous or episodic acquisition. Episodic data with each epoch consistent in duration, or continuous data, can then be split into waves. It is not possible to split the data once it's been loaded. Splitting a data file has several specific benefits that can all be considered part of the processing of data before analysis; otherwise, a continuous data recording is loaded as a single wave.
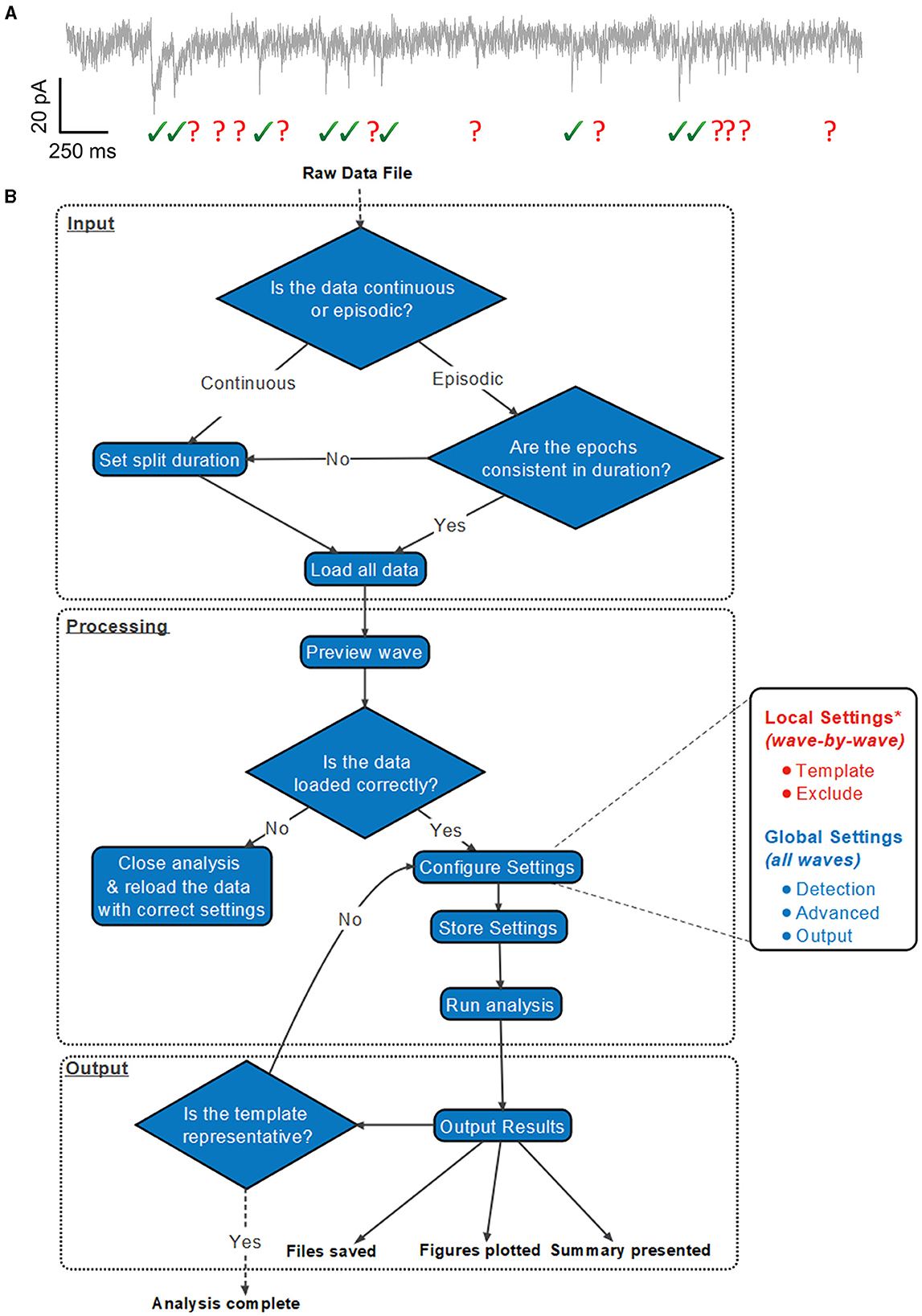
Figure 1. Exemplary analysis run workflow using Eventer. (A) Exemplary synaptic recording trace illustrating the difficulty in reliably manually selecting candidate events from the background noise. (B) Example analysis run illustrates how users are anticipated to work with Eventer. Work sections are largely split into three distinct regions: input, processing, and output. During the input, a raw data file must be selected, and a decision must be made to split the data if necessary. In the processing stage, local and global settings can be adjusted before running the analysis. Data are then presented and saved in the output phase. It is then possible to iterate the analysis and refine the event template, or train a machine learning model and use this for the classification of candidates detected in test datasets. *Local settings can be applied to all waves, as per the global settings in the GUI, if desired.
1.1.2 ProcessingOnce a data file has been loaded, Eventer will load a preview of the first wave, whether or not the recording is split. This preview allows the user to determine if the data have been correctly loaded. If not, the data should be reloaded; otherwise, the user can proceed to configure the analysis settings. Users can change the local, wave-by-wave, or global settings, which apply to all waves.
Both the Template and Exclude waves are considered local settings, so changes made here only apply to the wave currently selected unless specified otherwise to apply to all waves. In the Template panel, a user can define time constants of the rise and decay of the synaptic event if they are known or bring up a pop-up window to allow time constants to be measured from an exemplary user-selected event as shown in Figure 2 (top). In the Exclude panel, users can instead choose to exclude regions of the data that they do not want to be included in the subsequent analysis. If that data are from continuous data and split to a value the same as the interval between repeating recording artifacts such as test pulses or stimuli, these can be excluded from the analysis here.
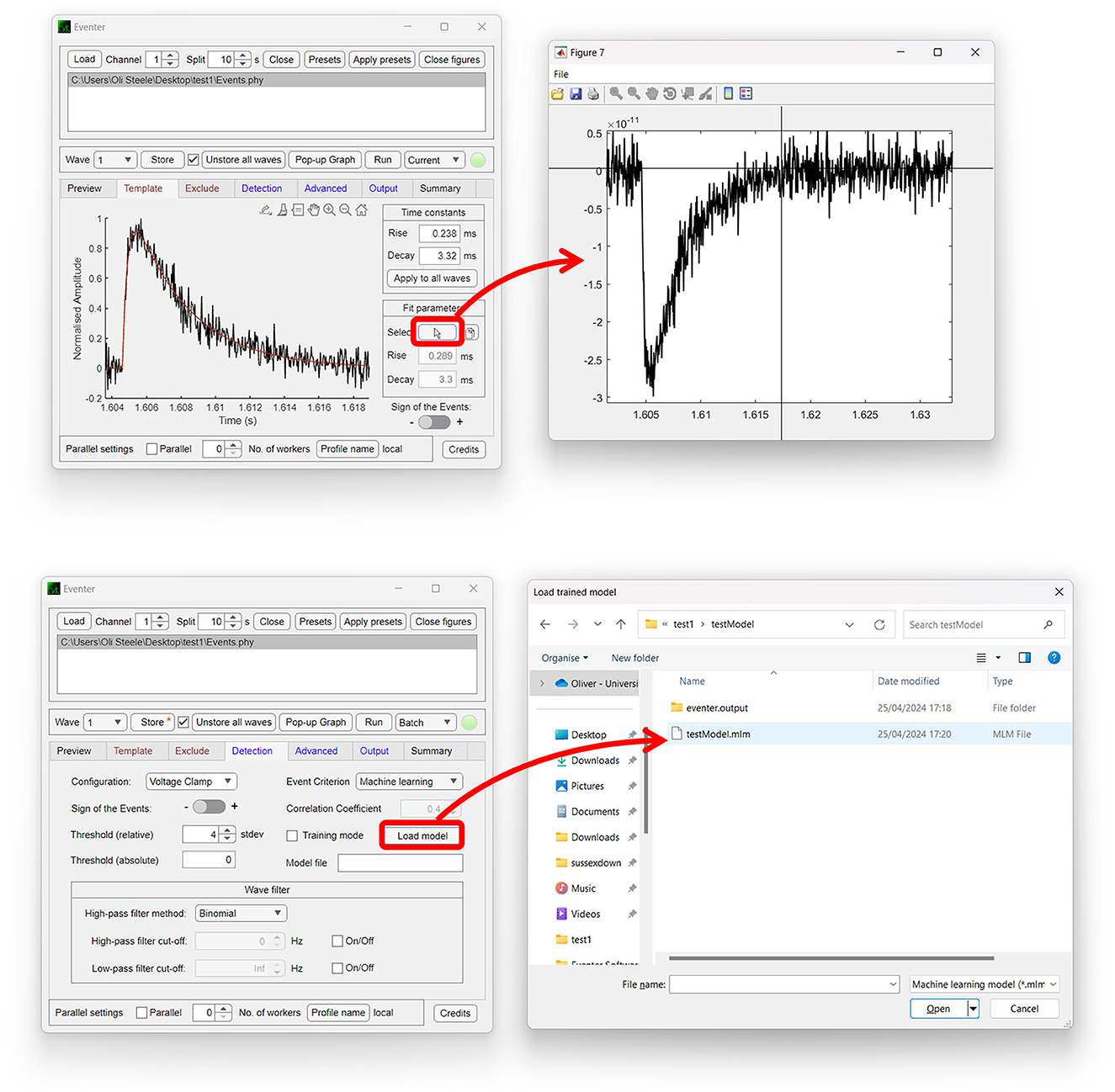
Figure 2. Easy-to-use graphical user interface of Eventer event detection software. Eventer features a clean, easy-to-use graphical user interface. (Top) The template panel is shown here, where users can select exemplary events to generate their parameters from. (Bottom) The detection panel is shown here, where users can select different event criterion methodologies, such as machine learning and Pearson's, and also load saved models through the opening of a file dialog window.
The global settings are outlined on the Detection, Advanced, and Output panels. The Detection panel allows the user to select settings relevant to event detection mode itself, including filtering methods, threshold level, and event criteria. The threshold allows users to specify a threshold, either set as standard deviations of the background noise of the deconvolution wave (i.e., detector trace), or an absolute threshold value of the deconvolution wave, for initial event detection. If the event criterion is set to Pearson's, a correlation coefficient can be set here also. If, however, the event criterion is set to machine learning, a previously trained model can then be loaded, as shown in Figure 2 (bottom); otherwise, training mode can be enabled, whereby users can train a machine learning model of their own. Note that no thresholding of the correlation coefficient is applied when using the machine learning approach, the Advanced panel includes several settings outlined further in the manual, available online (Eventer, 2022). Finally, the Output panel allows users to define several output-specific settings, such as the format to save figures and data in (Table 1).
If the user is happy with the settings and the settings are stored, the user can then choose whether to analyse the single wave or a user-selected batch of waves. It is also worth noting at this point that users can take advantage of the parallel processing capabilities included as part of Eventer to speed up analysis dramatically by accessing multiple cores at once.
1.1.3 OutputFollowing the completion of the analysis, Eventer then displays a summary of the results in the Summary panel. Files, and figures, are also saved in the desired output format, as specified before (Table 1). Finally, a range of summary plots are then plotted for the user to rapidly interpret the output of analysis and the suitability of the template fit. It may be advised that if the fit is not appropriate here, adjust the time constants with those in the Summary section and iteratively re-run the analysis until the template fit is appropriate (Figure 1).
1.2 Eventer workflows: analysisIn addition to the intuitive GUI, Eventer utilizes a novel event detection methodology depicted in Figures 3, 4. Eventer initially performs FFT-based deconvolution, and then in the frequency domain, the resultant deconvolution wave is a measure of similarity to the event template at each point of the recording. The time points of peaks in the deconvolution wave exceeding a set threshold, expressed either as an absolute value, or a scale factor of standard deviations of the noise, indicates the start times of candidate events. A Pearson's correlation coefficient is then calculated for each candidate event with respect to the event template. Eventer will then either declassify events with a Pearson's correlation coefficient below a user-defined threshold (between −1 and +1) if the event criterion is set to Pearson's before outputting results, or measure additional event features (depicted in Figure 4) if set to Machine Learning mode.
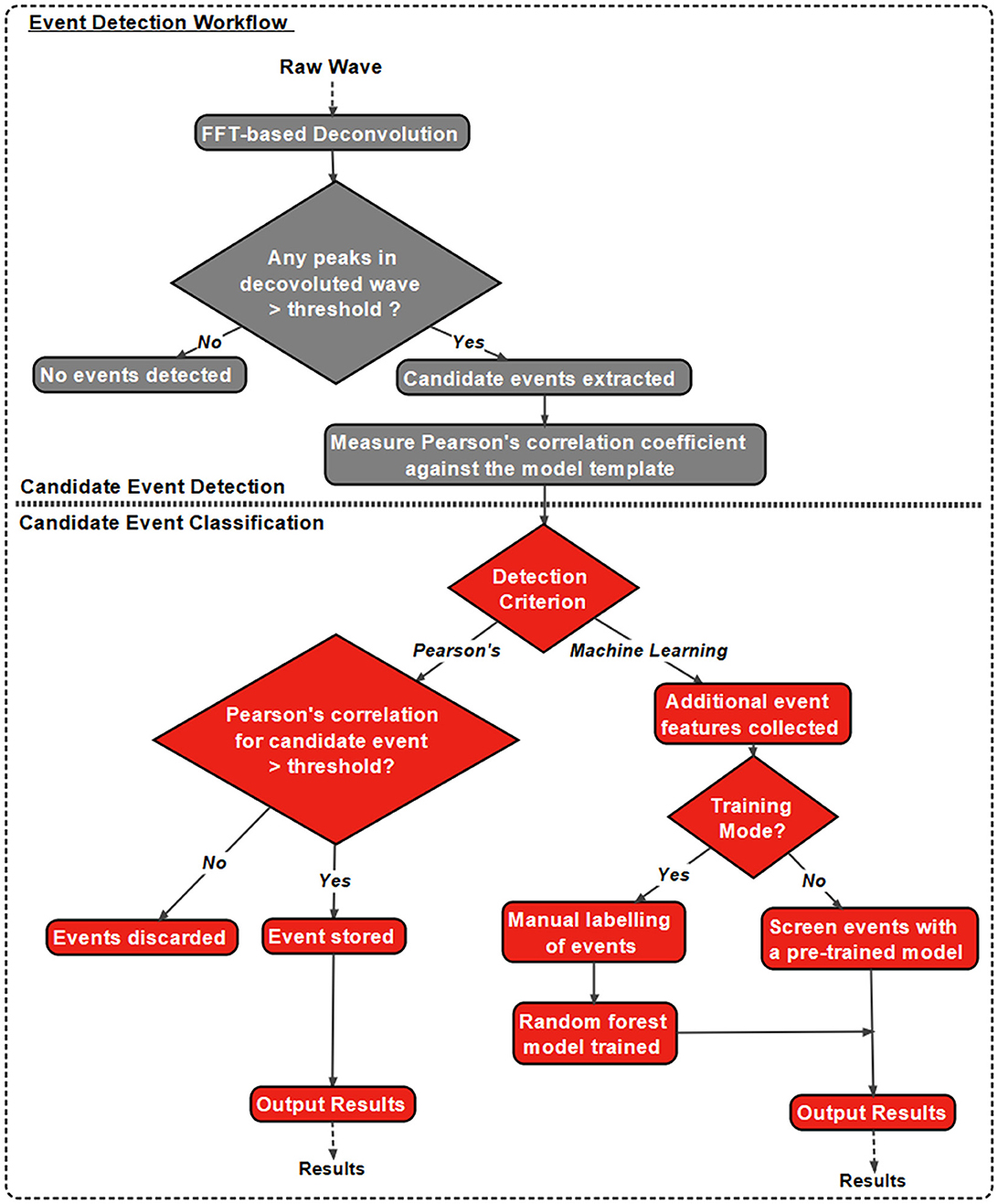
Figure 3. Eventer features a novel event detection protocol. Raw waves are initially deconvoluted by fast Fourier transform (FFT)-based deconvolution and compared to the event template. The resultant deconvolution wave (a.k.a. detector trace) depicts how similar, in the frequency domain, the data are at each point to the event template. If candidate events are above the user-defined candidate events are then made available for classification; otherwise, they are discarded. At this point, Pearson's correlation coefficient for each event against the model template is recorded. Next, dependent on the user-selected detection criterion, candidates will either be screened and saved if above the set Pearson's threshold and output as results, or additional event features will be computed if in machine learning mode. If in training mode, manual labeling of candidate events occurs to train a random forest model; otherwise, a pre-trained model can be loaded and passed over candidate events before outputting the results.
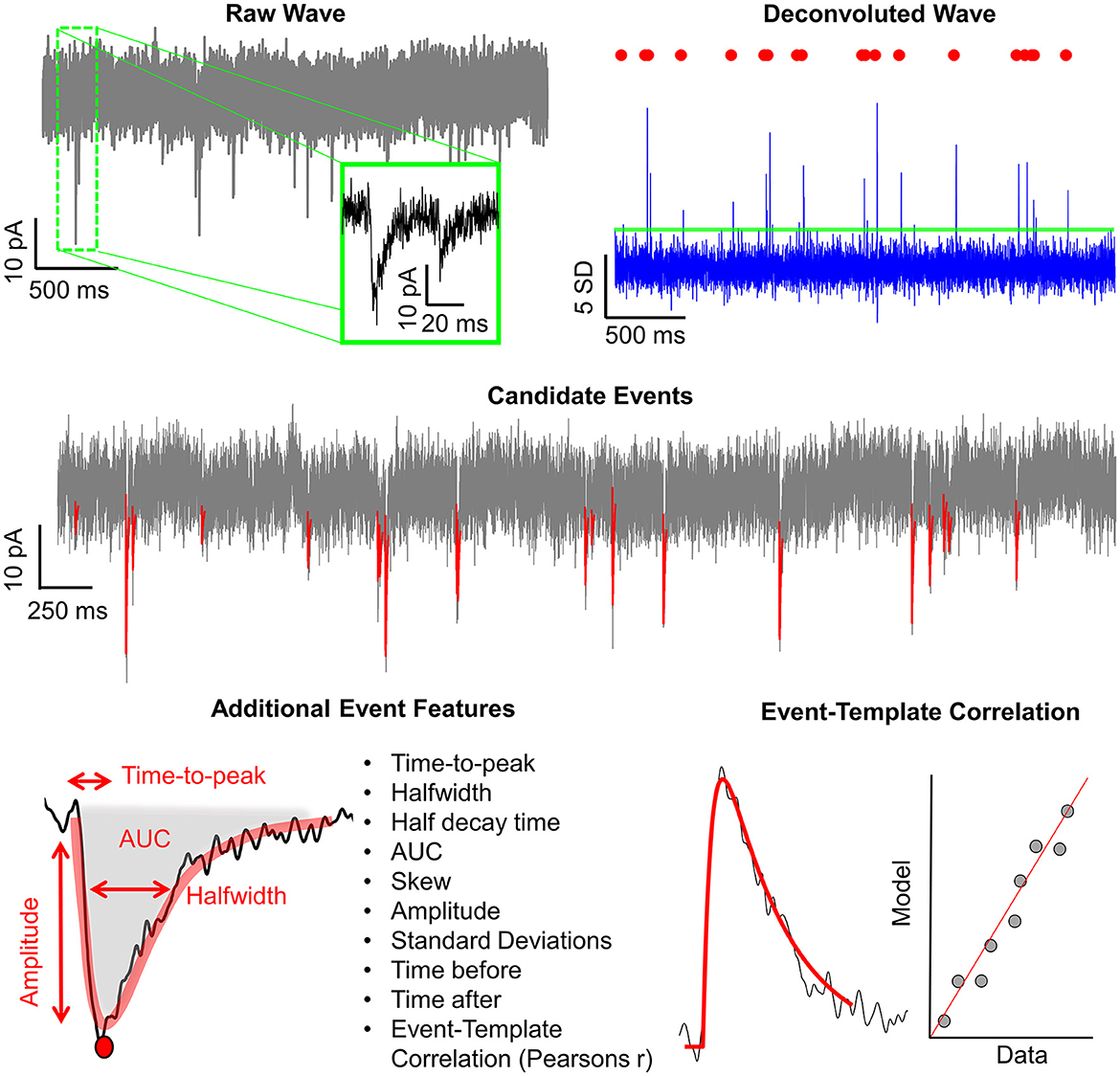
Figure 4. Graphical depiction of the analysis workflow. Shown here is a graphic representation of each of the relevant steps of Eventer-based event detection. Initially, a raw wave undergoes fast Fourier transform (FFT)-based deconvolution and comparison against the event template (top), at which point candidate events are selected if they are above a set threshold (middle). If set to machine learning mode, then additional event features are measured, including Pearson's correlation, and used to train a random forest model. Otherwise, when in Pearson's mode, if events have a Pearson's correlation coefficient below the set threshold, then these events are discarded before the results are output.
In Machine Learning mode, the user has the option to specify whether this run executes in training mode, whereby the user will then be provided with a pop-up window to manually label candidate events selected by the FFT-based deconvolution. The user's classification will then be used to train a random forest machine learning model, which could then be run over new data. If not in training mode, a previously trained model can be loaded and run, with events being screened with the preferences included implicitly in the trained model.
2 Methods 2.1 Simulated events 2.1.1 AccuracyData used for the accuracy tests presented in Section 3.1 and Figure 5 were generated by adding simulated miniature excitatory postsynaptic current-like waveforms to real whole-cell recording noise using the custom “simPSCs_recnoise.m” script and the “noiseDB.abf ” data file, which are all available online at the acp29/Winchester_EVENTER repository on GitHub (Penn A., 2024). The background recording noise from CA1 pyramidal neurons in organotypic hippocampal slices (see Methods section in Elmasri et al., 2022a,b) was acquired with a MultiClamp 700B amplifier (Molecular Devices), low-pass filtered (4 kHz, low-pass Bessel filter), and digitized (40 kHz) with a USB-X Series Multifunctional DAQ interface (NI USB-6363, National Instruments) interfaced through python-based, open-source data acquisition software, ACQ4 software (v0.9.3) (Campagnola et al., 2014). The salt compositions of extracellular and intracellular solutions are described in Elmasri et al. (2022a,b). Ionotropic glutamatergic and GABAergic channels were pharmacologically inhibited with (in μM): 10 NBQX, 50 APV, and 10 Gabazine, respectively, to isolate background noise during whole-cell recordings (e.g., stochastic ion channel openings, instrument noise, etc.).
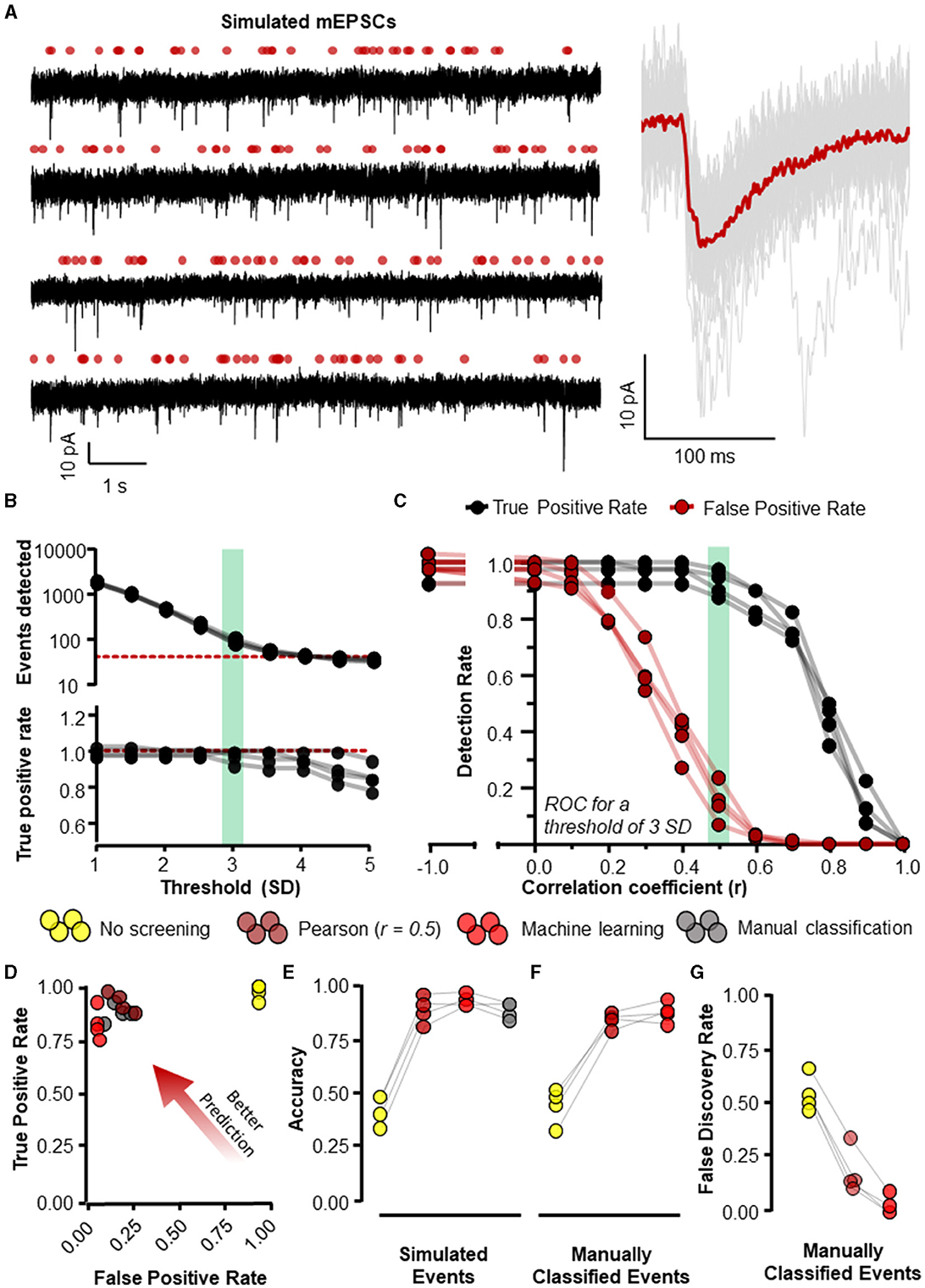
Figure 5. Eventer accurately detects synaptic events. Eventer was able to accurately classify simulated events, either those that were simulated or those that were classified by manual selection. (A) The four waves represent simulated events (of variable amplitude and time course) added to real whole-cell recording noise and used as data to assess the accuracy of Eventer (left). The right of the panel shows the mean ensemble average of the 40 simulated events in red plotted over the individual events in gray from the first simulated wave. (B) (top) The total number of events detected in each of the simulated waves decreases as the threshold of the signal in the deconvolution wave increases. The red dotted line represents the number of simulated events in the waves (bottom). The true positive rate of event detection decreases as the threshold of the deconvolution wave is increased above 3. (C) The true positive rate (TPR) shown in black and the false positive rate (FPR) shown in red are plotted as a function of the correlation coefficient (r) in Eventer with the threshold of the deconvolution wave set at 3 standard deviations. (D) Graph showing how the results of different classification methods occupy ROC space, with scores in the bottom-right indicating poor prediction/classification (through high false positive and low true positive) and top-left indicating better prediction/classification (through low false positive detections but high true positive detections). (E) Depicts an overall score of accuracy of Eventer to select simulated events. (F) An overall score of accuracy by comparing the events selected by each parameter relative to manual classified events. (G) The main benefit of Eventer machine learning is a large reduction in the false discovery rate when trying to reproduce manual classification of synaptic events. Statistical results for this figure are documented in Table 2.
For each of the eight simulations generated, 40 events were individually simulated using randomly sampled amplitude and kinetics and added to 9.9 s of whole-cell recording noise. The procedure to simulate each event went as follows: A value for the amplitude (in -pA), rise time constant, and decay time constant (both in ms) were generated by exponential transformation of the random number sampled from a normal distribution (with mean and standard deviation) of N(2.46, 0.35), N(−0.31, 0.60), and N(1.48, 0.46), respectively. These distribution parameters were chosen based on the log-normal distributions of miniature excitatory postsynaptic current (mEPSC) parameters obtained when analyzing recordings of CA1 neurons (without NBQX and with 1 μM Tetrodotoxin) in our lab. The only other constraint on the parameters of the simulated events was that the sampling for the decay time of the event was repeated if its time constant was less than or equal to its rise time constant. The rise and decay time constants were used to generate a synaptic-like waveform using the sum-of-two exponential model and then peak-scaled (Roth and van Rossum, 2009). The sample point for the event onset was drawn from a random uniform distribution across the total number of simulation samples (396,000) and represented as a value of 1 in a vector of zeros. No limits were placed on how close events could be to each other. The event waveform was then simulated at the random time of onset by fast Fourier transform (FFT) (circular) convolution using the equal-length vectors defining the event onset and the synaptic-like waveform. The resulting vector was scaled by the event amplitude and added to the equal-length vector of whole-cell recording noise. The procedure was repeated 40 times in total for each of eight different whole-cell noise and with different random seeds. To analyse the simulations with the machine learning method in Eventer, half of the simulated waves (n = 4) were used exclusively for training four different machine learning models, and the other half of the waves (n = 4) were analyzed and used exclusively for the accuracy evaluation tests.
Four different classification methods were compared: Pearson's correlation coefficient (r) threshold of 0.5, machine learning using random forests, manual classification by an expert user, and no screening/classification (i.e., r = −1). Other non-default settings used for analyses the conditions were rise and decay time constants of 0.44 and 6.12 ms for the template, and a detection threshold of three times the standard deviation of the noise in the deconvolution wave, which was filtered with high- and low-pass cutoffs of 1 and 200 Hz.
The Matlab function “ismembertol” was used to identify matching times of event onset (within 1.2) for events that were detected and/or classified vs. those that were originally simulated (Figures 5B–E) or manually classified (Figures 5F, G). With this information, the following receiver operating characteristics (ROC) were computed. A true positive (TP) was determined as a detection classified as true that was indeed a simulated event. A false positive (FP) was a detection classified as a true event but was not. A true negative (TN) was a false detection correctly classified as false, whilst a false negative (FN) was where simulated events were incorrectly classified as false. From these values, it was then possible to calculate the following metrics. First, a false positive rate (FPR), interpreted as the rate at which Eventer incorrectly classifies an event to be a true synaptic event, was calculated as follows;
False positive rate (FPR)= FPFP+TNTrue positive rate (TPR), interpreted as the rate at which Eventer correctly classified an event as a true synaptic event, was calculated as follows:
True positive rate (TPR)=TPTP+FNAn overall measure of accuracy was then calculated as follows:
Accuracy= TP+TNTP+TN+FP+FNFinally, a false discovery rate (FDR), interpreted as the proportion of all of the events classified by Eventer as true events that are in-fact not events, was calculated as follows:
False discovery rate (FDR)= FPFP+TPThe computations are documented in a script, “invcompE.m,” which is available online at the acp29/Winchester_EVENTER repository on GitHub (Penn A., 2024).
2.1.2 Speed and parallel computing performanceThe performance test in Figure 6A was performed on the simulated waves, as detailed in Methods 3.1.1 and illustrated in Figure 4A. Here, the simulated waves were then analyzed with three detection methods: Pearson, machine learning (pre-trained model), and manual classification of events, in which a threshold of 3 standard deviations and a Pearson's r of 0.4 were set and used across all repeats (five per condition). The total time taken for Eventer to complete detection was then recorded in seconds.
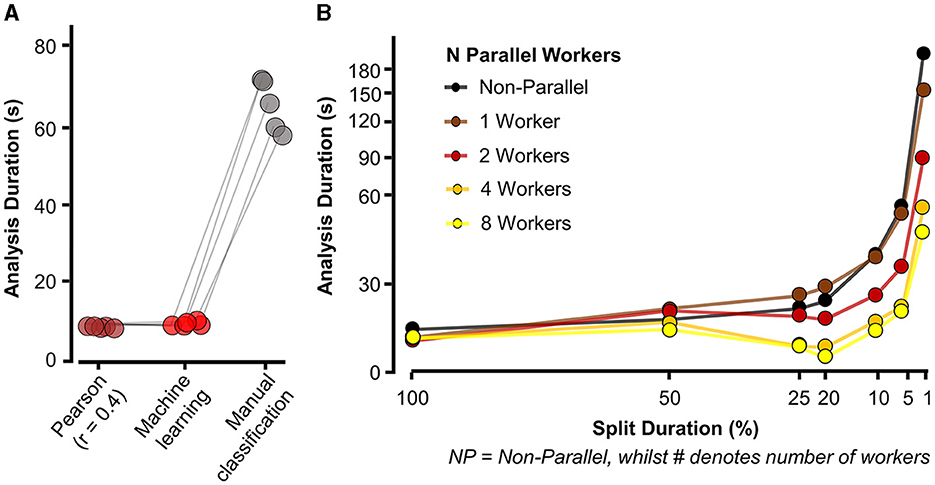
Figure 6. Eventer increases speed of synaptic event detection via parallel processing. (A) Eventer with machine learning or Pearson's correlation coefficient threshold for classification was considerably faster than manual classification. (B) Speed (in seconds) taken for analysis to complete and display results for a 100-s-long recording with simulated events occurring at a frequency of 3 Hz on top of physiological recording noise, with multiple split percentages and numbers of parallel workers. X-axis plotted on logarithmic scale. Split duration is plotted in reverse order, with the left (100%) indicating no split and the further right suggesting an increasing degree of splitting the data. For example, 5% split of 100 s would equate to 20 × 5-s waves being generated.
Simulated events used for the performance tests in Figure 6B were generated with white noise (RMS = 2 pA) using the “simPSCs.m” script, which is available at the acp29/Winchester_EVENTER repository online on GitHub (Penn A., 2024). We simulated a single 100-s wave containing 300 events from log-normal distributions for amplitude, rise time constant, and decay time constant with a mean of 20 pA, 0.4 ms, and 4 ms, respectively, and a coefficient of variation of 0.5 (i.e., 50%). Inter-event intervals were constrained to have a proximity of no <1.5 ms. To evaluate performance using different settings in Eventer, the 100-s simulation was split with the following denominations (in seconds): 1, 5, 10, 20, 25, and 50, which were then plotted as percentages of the total time. The number of workers (i.e., physical cores) dedicated to parallel processing was then changed from 0 (non-parallel, with figure plotting) to 1 (non-parallel, but without figure plotting), 2 (two parallel physical cores without figure plotting), 4 (four parallel physical cores without figure plotting), and 8 (eight parallel physical cores without figure plotting). The time taken to analyse the data (from selecting “run” to the display of summary results) was then recorded in seconds and plotted against the recorded split percentage and number of workers. All events, across all conditions, were detected with the same data and template settings, although, other than the number of events, our experience is that the properties of the events and the noise have relatively minor impact on the performance of Eventer. The computer used for testing Eventer parallel performance had a Ryzen 7 3800X 4.2 GHz 8 core processor with 32GB DDR4 3200 MHz random access memory (RAM), 1TB non-volatile memory express (NVMe) solid-state drive (SSD), and was operated using Windows 11.
2.1.3 ConsistencyIn the third experiment assessing the consistency of analysis between users, analysis was conducted on real recordings of mEPSCs from CA1 neurons in organotypic hippocampal slices, in which voltage-gated sodium channels were inhibited with 1 μM tetrodotoxin and ionotropic GABAergic channels were pharmacologically blocked with 50 μM picrotoxin. Organotypic hippocampal brain slices were prepared using methods and with ethical approval as described previously (Elmasri et al., 2022a,b). Recordings were performed with a cesium methanosulfonate-based intracellular recording solution containing the following (in mM): 135 CH3SO3H, 135 CsOH, 4 NaCl, 2 MgCl2, 10 HEPES, 2 Na2-ATP, 0.3 Na-GTP, 0.15 C10H3ON4O2, 0.06 EGTA, and 0.01 CaCl2 (pH 7.2, 285 mOsm/L). Artificial cerebrospinal fluid (aCSF), perfused over organotypic hippocampal slices at 3 ml/min during recordings, was maintained at 21°C, balanced to ~305 mOsm/L, and bubbled with 95% O2/5% CO2 continuously, contained the following (in mM); 125 NaCl, 2.5 KCl, 25 NaHCO3, 1.25 NaH2PO4, 1 MgSO4.7H2O, 10 D-glucose, 2 CaCl2, and 1 sodium pyruvate (pH 7.4). Three 30-s recordings were analyzed, each by a separate group of five postgraduate neuroscience students (15 in total) who had a basic familiarity of synaptic event detection. Each student was asked to select event parameters and manually classify events, and the details of their individual classification were compared with the same for each of the other students within their group by calculating Matthew's correlation coefficients (MCC).
The equation for the Matthew's correlation coefficient is illustrated below:
MCC= TP× TN-FP×TN(TP+FP)×(TP+FN)×(TN+FP)×(TN+FN)All students were then given a single model and asked to pass this model over the same recording without changing their chosen event parameters, and the comparisons using MCC were repeated.
2.1.4 StatisticsGraphs in figures were created either in GraphPad Prism (version 8) or GNU Octave (version 8.3). The Statistics-Resampling package (version 5.5.10) in GNU Octave was used to perform null hypothesis significance testing, specifically using the “bootlm” (for the tests in Figure 5) and “randtest2” (for the tests in Figure 7) (Penn A. C., 2024). Using “bootlm,” p-values for two-way ANOVA without interaction were calculated by wild bootstrap resampling of the residuals (with Webb's six-point distribution). With the same function, post-hoc test p-values for pairwise differences were computed using the studentized bootstrap-t method, and the family-wise type 1 error rate was controlled using the Holm–Bonferroni step-down correction. The confidence intervals reported in Table 2 by “bootlm” are asymmetric studentised 95% confidence intervals after wild bootstrap. For the permutation test in Figure 7, the “randtest2” function with paired argument set to true was used to permute the allocation of the sets of event times for each subject between the manual and machine learning conditions and calculate a two-tailed p-value from the permutation distribution of intra-group pairwise differences in Matthew's correlation coefficient. See the Data availability statement for information on how to access and reproduce the statistical analysis. All statistics reported in the text are mean ± SD.
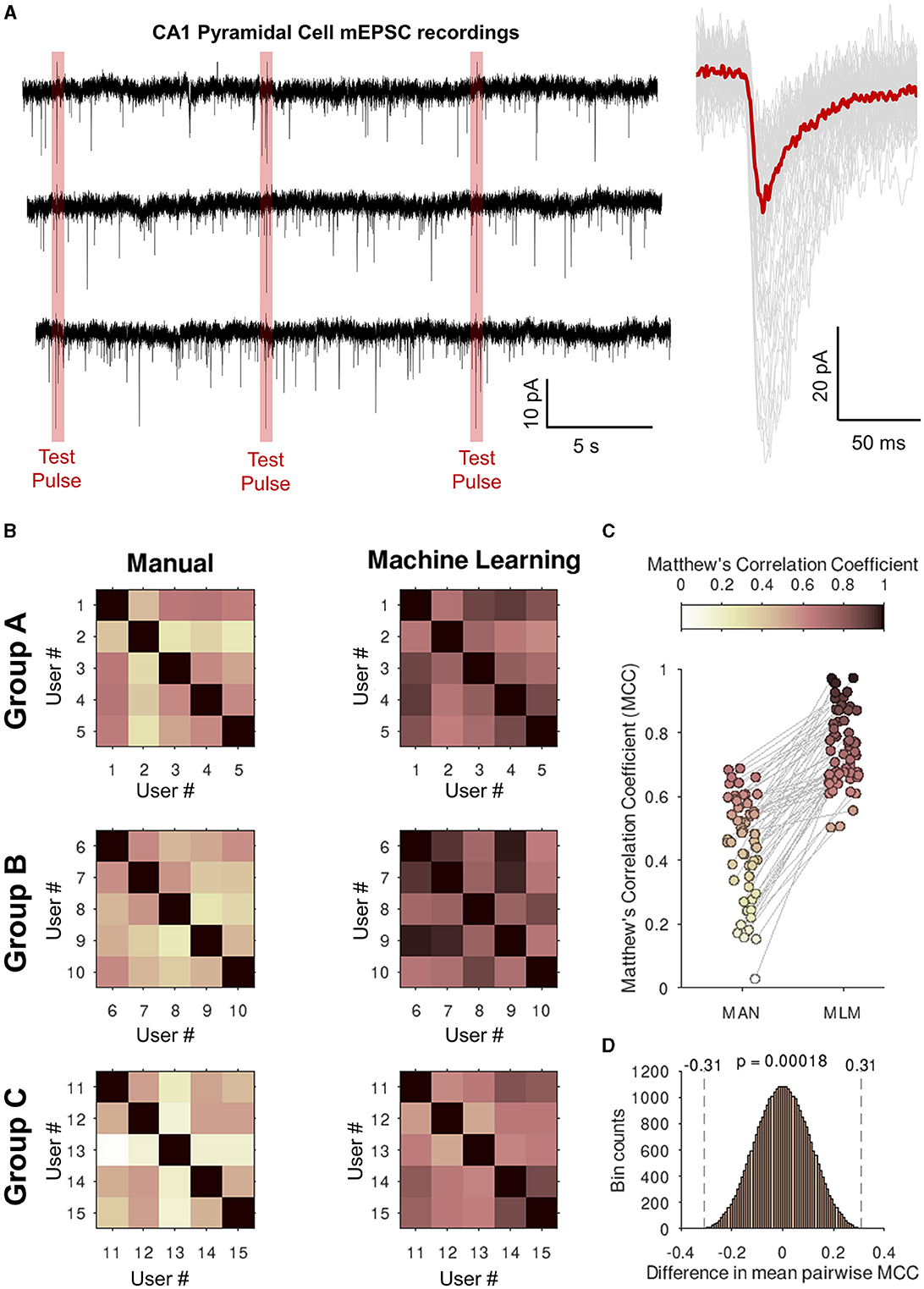
Figure 7. Eventer increases consistency of analysis between users when classifying synaptic events with a single machine learning model. (A) (left) Whole 30-s traces of miniature excitatory postsynaptic currents (mEPSCs) recorded from CA1 pyramidal neurons in organotypic hippocampal slices that students in the groups below (Groups A–C). Highlighted in red are the voltage step test pulses to observe changes in access resistance that were excluded from the analysis. (Right) Individually detected events are shown in gray with the ensemble average overlaid in red. (B) Three groups (Groups A–C) of five students were asked to detect and classify events as either true events or false positive detections. Shown in the upper-right half of the grids Matthew's correlation coefficients (MCCs) are plotted against the users' own classifications for the intra-group pairwise comparisons (left, Manual). The users then all loaded a machine learning model generated by a single expert user and then re-ran the event classification (right, machine learning). (C) Values of the off-diagonal MCC scores are plotted for each pair of student comparisons. (D) Permutation distribution for the difference in MCC scores between manual and machine learning classification.
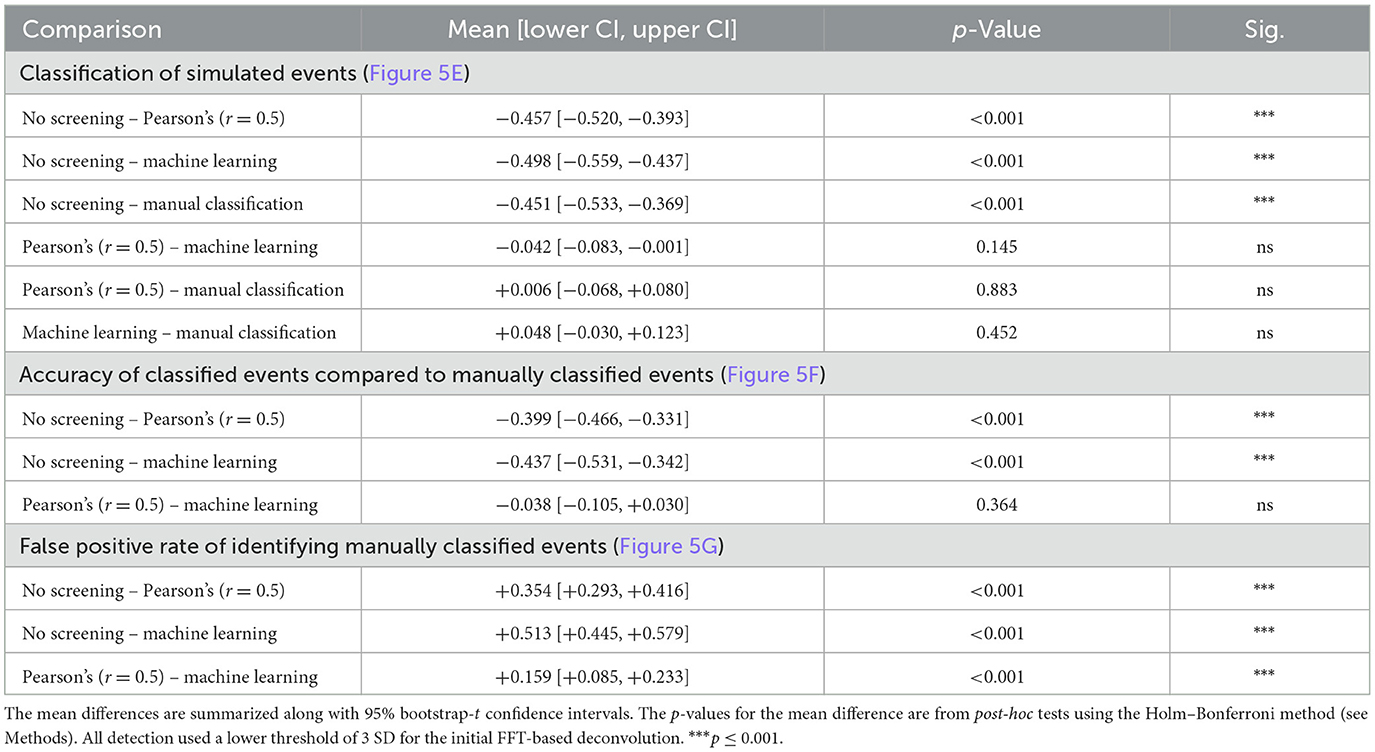
Table 2. Statistical results for Figure 5.
3 Results 3.1 Eventer enables accurate detection and classification of synaptic eventsTo evaluate the accuracy of Eventer for the detection and classification of synaptic-like waveforms, we simulated recordings, each consisting of 40 events generated by FFT convolution and added to a unique 9.9-s segment of recording noise measured by whole-cell patch clamp in CA1 neurons whilst pharmacologically blocking synaptic receptors (see Section 2.1.1 for details). The root-mean-square deviation (RMSD, calculated in rolling 100 ms windows) of the recording noise was 2.43 pA (SD = 0.085 pA), and the log-normal distributions used for random sampling for the amplitudes, rise time constants, and decay time constants for the events had a mode [2.5%−97.5% percentiles]: 10.4 [5.9–23.2] (–)pA, 0.51 [0.23–2.38] ms, and 3.55 [1.78–10.82] ms, respectively. A further four independent simulated recordings were created for the purposes of training machine learning models (Figure 5A).
Event detection in the simulated waves was conducted with the multiple modalities of event detection and classification that exist in Eventer. The most rudimentary form uses threshold-crossing of the detector trace after FFT-based deconvolution (Pernía-Andrade et al., 2012), without any further screening or classification (i.e., switching off Pearson's correlation coefficient in Eventer to −1). In order to compare classification methods, we first established a detection threshold for the deconvolution, that is sensitive enough to detect all (or most) of the simulated events whilst also providing opportunity for alternative screening or classification of candidate events. The number of events detected dropped steeply as the detection threshold was raised from 1 to 3 standard deviations of the noise, and more slowly for thresholds of 3 to 5 standard deviations (Figure 5B). However, a decline in the rate of true positive event detections became increasingly apparent at thresholds of about 3 and above (Figure 5B). Whilst higher thresholds for deconvolution (e.g., 4 SD) can provide good accuracy in the tests we describe hereafter (Pernía-Andrade et al., 2012), they do not yield a sufficient number of candidate events for further tuning the classification process. Therefore, a threshold of 3 standard deviations (SD) was used for the subsequent tests. Eventer can compare candidate events detected by the FFT-based deconvolution, discarding those events where the Pearson's correlation coefficient drops below a set threshold. We found that setting higher thresholds for the correlation coefficient reduces the number of false positive classifications, albeit at the cost of missing true positive events (Figure 5C). Indeed, the TPR dropped rapidly as the threshold for the correlation coefficients exceeded 0.5 (Figure 5C). We next examined the receiver operating characteristics (ROC) with these settings (3 SD with or without r = 0.5) compared with those using a detection threshold of 3 SD and manual or machine learning event classification.
Manually classifying candidate events after deconvolution resulted in very similar FPR and TPR scores compared to screening using the Pearson's correlation coefficient threshold of 0.5 (Figure 5D). However, the threshold of r = 0.5 may not always be optimal for event screening in any given context and could vary depending on the variability of event time course kinetics and signal-to-noise ratio. A benefit of using Eventer is the option to reproduce the accuracy of manual event classification by using a trained machine learning model; thereby, users can avoid arbitrarily setting a threshold for the matching of the template time course with the events. To test the machine learning capabilities of Eventer, four machine learning models were generated by training four independent waves created using different segments of background noise recordings and the same data-generating process as the test simulations with different random seeds (see Section 2.1.1). Each model was trained on 83–107 candidates (detected by the FFT-based deconvolution), of which 37–40 represented the originally simulated events. The out-of-bag classification error for the trained models, which is used to estimate the prediction error of the r
Comments (0)