
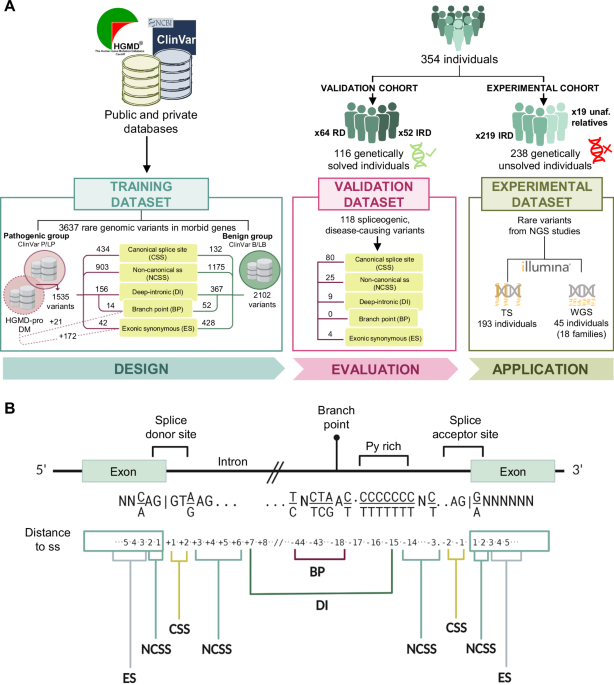
Remember me


Clinical implementation of diagnostic GS will require important procedural updates and modifications related to the patient care pathway (Fig. 3). For example, standard operating procedures (SOPs) for sample collection should be clearly defined (e.g., how to collect, type of blood vials, how to handle and potentially how to ship). Prior to extending diagnostics into research, ethical votes via the local medical ethical committees need to be granted. Patient involvement and counseling are required for extensive genome data analysis in a diagnostic setting. It is critically important to establish and maintain a level of trust and responsibility in the healthcare system in managing highly sensitive individual genome data.
Patient counseling beyond that of the current routine diagnostic procedure will need to include information related to the analysis and transmission of actionable gene data or even PRS, in addition to receiving informed consent (communication flow) to perform such analyses. Importantly, the extent of data analysis must be determined a priori using the following considerations: patient care infrastructure, access to disease experts, prevention programs for diseases with high genetic risks, and even to what extent health insurance will cover follow-up costs.
Given the complex integration of patients into different studies, it is important to establish the communication flow between the patient, physician/geneticist, other interacting clinicians, and the diagnostic institution. Transparent communication with the patient and the interacting clinicians on the data flow (where the data will be stored, who will have access, and under what conditions) is critical. There must also be a standard procedure for the information flow of the data (how to communicate results back to the patient), who will be allowed to obtain certain types of reports (healthcare professionals, relatives), and what clinical/preventive/management consequences can be drawn from the patient’s test results (Fig. 3).
Fig. 3: Complexity of the interaction of various individuals involved in the genome diagnostic process.
Before diagnostic GS can be initiated, the full complexity and dimension of GS have to be communicated with the patient and the referring physician. In unclear and unsolved cases interdisciplinary boards decide whether to extend diagnostics to GS. In the process of sample collection, several caretakers need to be involved besides the clinical geneticist to ensure high-quality samples and complete documentation. Information and consent of patients have to be discussed at the end of the diagnostic process, as to where to store data, and who gets access to it. Using diagnostically generated data for research requires careful consideration of each stage of the diagnostic process. This model could support policymakers in developing novel diagnostic core centers ensuring widespread scientific use of diagnostic data in the healthcare system. KLINSE: Clinical Information Office on Rare Diseases (https://www.medizin.uni-tuebingen.de/de/das-klinikum/einrichtungen/zentren/zentrum-fuer-seltene-erkrankungen-zse/klinse).
Thus, adequate infrastructure is required to support a highly complex network of interacting specialists that includes multidisciplinary boards and case managers for the management of samples, clinical information, informed consent, and letters of referral. Additional headcount includes genetic nurses for professional sample collection for the different studies as well as a documentarist to manage the FAIR principles for data availability and sharing (Findable, Accessible, Interoperable, Reproducible)14. Health insurance companies often claim that because sequencing costs are falling, the reimbursement of the entire analysis should decrease as well. It is dually important for them to recognize the increasing complexity of this process as well as the potential of genome data to significantly impact patient care and inform disease prevention.
In our institute, we do not offer carrier status analysis as a routine procedure, but it may be offered in certain family situations (e.g., consanguinity of parents). Finally, there is a general agreement that genetic risk conditions without treatment options and without prevention should not be analyzed.
Secondary findings (SF) and actionable genes (AG)One example of the importance of communication between patients undergoing GS analysis and providers is the communication of secondary findings which should be embedded in the counseling process and include specific recommendations about follow-up medical check-ups.
Across a broad range of indications, the overall frequency of secondary findings is approximately 3%15. SF are informative in a few ways: (I) When a detailed retrospective anamnestic or pedigree analysis is performed or a clinical review reveals clinical manifestation in the person examined or symptomatic patients in the family, one can reasonably posit that GS did not reveal an SF per se but instead confirmed a previously not recognized diagnosis in the family (as relatively common for cancer syndromes); or (II) GS reveals a true SF without symptomatic patients in the family thus revealing true novelty for the new person at risk.
In both diagnostic and research settings, we have successfully established a process where patients can opt-in for analysis and reporting of SF. When genetic counseling is provided, information about the predictive nature of SF, their possible clinical consequences (preventive medical check-ups, preventive medical therapy, recommendation for lifestyle adaption), and their potential relevance to family members are discussed, equipping patients with information to help them decide whether to receive information on eventual SF or not. In our practice, we are not able to discuss each potential SF in detail; however, we inform about disease groups (e.g., cancer, cardiologically relevant genes, and actionable genes involved in metabolism). We also explain the difference between monogenic SF and a polygenic risk score. In compliance with national legal regulations (GenDG; https://www.gesetze-im-internet.de/gendg/index.html), patients can withdraw their consent as long as the results have not been reported. If SF is detected, a second report is provided independently of the original diagnostic analysis. This independent reporting has been established as it most frequently requires changes in patient management by a different medical specialist.
In general, our organization offers patients the option of requesting additional analysis of SF in AG and, most recently, for selected PRS (e.g., breast cancer, diabetes mellitus). Exceptions are analysis of AG/PRS in patients with psychiatric symptoms such as acute depression or schizophrenia, or in patients with severely progressed neurodegenerative diseases. In principle, these rules also apply to children, however, based on discussion with our ethical board, in selected cases, we inform the parents about their potential risk for a monogenic condition. Of course, genetic counseling and written informed consent are always required. Since 2016, we have applied the ACMG59 gene list, further developed by the German Network on Actionable Genes (GNAG; https://gfhev.de/de/ueber-uns/kommissionen.html). We acknowledge that the ACMG board of directors does not recommend global screening for variants in these genes16. With the extension of the gene list in 2021 (ACMG v3.0-v3.2)17, we adopted the recommended 73 genes or gene variants in the list of the reported AG. Overall, more than 90% of all patients in Ge-Med decided in favor of testing for all SF. With the precedent ACMG59 list, about 5% of all patients harbored pathogenic/likely pathogenic findings, a number which declined with the ACMG v3.0 recommendations despite including more genes (for instance, in addition to the ACMG59 list we reported also MUTYH heterozygosity and biallelic HFE variants whereas with ACMG v3.0 some common HFE mutations and MUTYH heterozygosity are not reported anymore). This is in good agreement with a recent study of about 58,000 individuals from Iceland who report that 4% of their population carry at least one actionable genotype18. In our clinic, variants of unknown clinical significance (VUS) are generally not reported as SF. We also highlight that (actionable) genes (such as PMS2) may not always be completely covered in a diagnostic sense (Box 1).
Polygenic risk scoresIn addition to rare disease and familial cancer applications, genomic data can be used to generate a personalized risk assessment for common diseases as well as aid in predicting disease risk in healthy individuals. PRS have been developed to quantify the cumulative effect of multiple genomic loci on the predisposition to disease. To reveal this genetic architecture, large genome-wide association studies (GWAS) have been conducted and serve as a base for PRS development. An individual’s PRS is dependent on the risk alleles present which can be assessed by different technologies (SNP Array, GS). Currently, GWAS databases mostly consist of individuals of European ancestry and must be adapted when applied to individuals or populations of non-European ancestry19.
In European countries such as Germany, it is expected that the PRS for a certain disease will be normally distributed and stratified into risk groups from low to high. In 2018, Natarajan and coworkers demonstrated that PRS models could be derived from GS data20. In a large cohort of individuals with hypercholesterolemia, only 2% had monogenic mutations leading to hypercholesterolemia while 25% of patients with severe manifestation had a significantly increased PRS indicating the importance of PRS analysis for common diseases.
In Ge-Med, we sought to expand our GS service to well-established PRS for selected types of diseases to broaden the range of GS data analysis of common diseases. We calculated the PRS of 10 common diseases in a German cohort of 1000 unaffected individuals (suppl. Fig. 1). Up to 16% had at least one increased PRS, with two individuals (0.2%) even harboring four increased risks. It will be important to have ethical and clinical discussions about when and for whom these risks should be assessed as well as what diseases should be analyzed.
Our experience with Ge-Med has shown us that the full potential of disease-relevant data based on GS analysis can be achieved in a single workflow as one does not need to have an additional array of ES data for a patient. One also has flexibility in combining monogenic and polygenic risks, which can be easily and continuously adapted for novel PRS for various diseases. The potential future relevance of assessing PRS in the general population lies in risk prediction, stratified application of disease prevention programs, as well as informing diagnoses, predicting disease course, and potentially supporting treatment decisions21.
Over time, a better understanding of personal health and lifestyle data, in combination with environmental factors and genetic makeup, will allow for the most informed disease risk prediction. Considering this potential, it is clear that PRS will not be the only risk marker in this context but will rather be complemented by many clinical parameters. Thus, we include the body mass index (BMI) of individuals asking for their respective PRS in diabetes which will also be relevant in the extension of PRS to cardiovascular diseases.
It will also be important to define cut-offs for high-risk individuals, consider all risk factors over time, and assess the interactions between these risk factors. We are currently facing this challenge with female patients at high risk for breast cancer. We currently use CanRisk22,23,24 to integrate risk scores with other data such as family history, histology, and mutation profile, thus improving the risk estimate for breast cancer and facilitating recommendation of disease prevention programs according to the recommendations of the German Consortium for Hereditary Breast and Ovarian Cancer. For breast cancer, we have applied a risk score based on 313 variants25. We are also using an integrated risk model of BMI, age, and PRS for type-2 diabetes (T2D) and are developing a tailored disease prevention program in collaboration with our clinical partners for individuals with a high combined 10-year risk ( > 15%) or a high genetic risk, defined as PRS above percentile 90 together. While we have no data yet on if and how the transmission of this information to the patients does indeed influence lifestyle or medical management, we have taken the first steps to the implementation of PRS into a diagnostic process for two common diseases, breast cancer, and T2D.
PharmacogenomicsUsing the sequenced genome as a platform for pharmacogenomic (PGx) testing in clinical practice to understand how variations in the genome dictate the response to medications is another promising approach to leveraging the generated data for the benefit of the patient. We have not yet offered PGx analysis to our patients and/or relatives because this offering is not yet reimbursed by insurance and there is a lack of usage of the data among the medical community in Germany (except for dihydropyrimidine dehydrogenase deficiency) where testing is recommended in colorectal cancer before 5-FU treatment. This is likely to change, however, as countries begin developing guidance on how best to handle PGx. For example, The Netherlands has developed PGx guidelines and recommendations as part of the European Research consortium (U-PGx)26. The European Medicines Agency specifically addresses the utility of PGx to reduce medication side effects and to improve treatment response. Thus, PGx is likely to be integrated into the healthcare of other countries as it can lead to better outcomes for both individuals and healthcare providers through improved medication safety and efficacy and lowered medical costs.
Box 1Pro: Beyond targeted diagnostics, clinical GS can be applied for risk prediction and disease prevention through the detection of actionable genes and PRS.
Con: Actionable genes and PRS are not part of a diagnostics contract in nearly all countries and are not requested by all patients. Thus, a combined diagnostic-research setting is required which needs a medical framework and cannot be an automatism for all situations and in each institution.
StandardizationImportantly, the infrastructure and workflows that we developed to bring srGS into diagnostics have been accredited by Germany’s national accreditation body (DAkkS) according to DIN EN ISO 15189 as the formal structure for quality assurance. While laboratories performing NGS should be accredited according to EuroGenTest, in Germany, this is not mandatory under the requirements of the Genetic Diagnostics Act (GenDG). However, institutions carrying out genetic analyses for medical purposes have to meet quality requirements ensuring the suitability of qualified personnel, appropriate premises, documented procedures for handling of consumables, equipment and software, and pre-analytic measures. Implementation of NGS testing needs to cover quality assurance measures for wet laboratory, and data processing including primary, secondary, and tertiary analysis as well as defined pipeline quality control and validation cycles. Post-analytic measures comprise the requirements for the release of test results, standards for variant evaluation, data storage, and reporting of findings as well as quality assurance measures in terms of validating that the method is suitable for addressing a given medical question27. As for the latter point, we have benchmarked the ability of genome-based testing to detect single-nucleotide variants (SNVs) and small insertions and deletions (InDels) using the “genome in a bottle” (GIAB) sample NA12878. For the high-confidence regions, we observed a sensitivity of 99.6%/96.7%, positive predictive value (PPV) of 99.4%/99.4%, and genotyping accuracy of 99.9%/97.9% for SNVs and InDels, respectively (https://github.com/imgag/megSAP/blob/master/doc/performance.md). An in silico down-sampling analysis showed that the defined minimum diagnostic sensitivity of 95% (SNVs) and 90% (InDels) was still achieved with an average of 31x coverage. However, in a diagnostic context, we aimed for a minimum 38x mean coverage to avoid the need for resequencing due to variations in sample loading and to achieve a low number of ‘diagnostic gaps’ (regions with <20x coverage) in diagnostic core genes, e.g., for breast cancer (Box 2).
Box 2We strongly recommend testing the diagnostic pipeline including bioinformatic tools using a reference sample. With clinical GS special attention should be given to the detection rate of InDels and repeat structures. We aim for a minimum of 38x mean coverage.
Transcriptome sequencing (WTS)Recent work has demonstrated that RNA sequencing can be beneficial for variant interpretation in rare diseases. Specifically, studies have reported that RNA sequencing can increase the diagnostic sensitivity up to 7.5%, while in the research setting it provides an additional 16.7% sensitivity with improved candidate gene resolution and the ability to evaluate splicing effects, copy number gain or loss, and regulatory variations all using GS data28,29,30. Lee and colleagues found that 18% of all genetic diagnoses returned required RNAseq to determine variant causality31.
It is important to note that the systematic integration of comprehensive RNA analysis in diagnostic reports is not yet fully established and current limitations in RNA analysis need to be addressed to enhance its utility as a diagnostic tool in human genetics.
First, tissue specificity for numerous genes may limit the ability to investigate the gene of interest, though others have shown that up to 90% of all genes may be covered by RNAseq30,32. In our experience, at the diagnostic level, we only detect about 60-70% of all OMIM genes in blood to support clinical GS (suppl. Fig. 2). For RNA analysis, we sequence at least 50 Mio clusters using polyA enrichment and sequencing as 2x100bp paired-end reads, which presents a sensitivity similar to a library preparation strategy that uses ribosomal and globin depletion (own unpublished data, and ref. 33). Deeper sequencing, however, may increase the number of OMIM genes detected by RNAseq based on peripheral blood.
Second, despite the availability of commercial products for RNA isolation and enrichment from blood samples, no method is cost-effective allowing for the investigation of RNA splicing and non-coding RNA. Depletion of ribosomal RNA results in a higher detection of introns, making the detection of potential splicing aberrations more challenging33,34. Enrichment of polyA RNA is sensitive to RNA degradation and results in a high and variable amount of globin transcripts, reducing the cost-effectiveness of the workflow35,36. The combination of polyA enrichment and ribosomal RNA depletion leads to an increase in intronic reads, and results in the loss of non-polyA transcripts.
Third, there is significant variability of transcriptome profiles depending on nutrition37, infection38, medication39, sex40,41, and age42. This variability may limit current global RNA data analysis in the diagnostic context. We have thus developed specific questionnaires for patients to learn at least about the most important potential RNA expression influencers (Suppl. Fig. 3). Diagnostic software for RNA analysis is under heavy development43,44. Most importantly, however, current algorithms tend to include predictions of the deleteriousness of variants, including tissue-specific gene expression prioritization45, indicating that several of the current limitations will be overcome soon with novel software analysis tools.
Even if global RNA analysis is not yet feasible for use as a first-line diagnostic, targeted analysis of predicted splice sites and the search for loss of allelic expression can be integrated into genome interpretation strategies and have become a valuable second readout. We have developed and implemented a novel workflow that allows us to perform both GS and RNA sequencing in a single-diagnostic process allowing far more comprehensive genomic data interpretation than GS alone. We have sequenced over 1,000 transcriptomes (human and cell lines) and developed specific questionnaires for the patients to gather information on vaccinations, infections, medication, and even special dietary requirements which all influence expression patterns but so far not yet specifically defined genes to reduce the complexity of individual transcriptome data. In addition to the 1,000 diagnostic RNAseq data mentioned above, we have generated an additional 5,000 in the research setting which could be used as a control set. We further generated diagnostic reports based on RNA analysis for DNA variants that have the potential to impact splicing, or in cases where only a single mutation has been identified in an individual with a putative autosomal recessive disease. Global, overall transcriptome analysis across all cohorts needs still to be done (Box 3) .
Box 3Pro: WTS is useful for more precise analysis of predicted splice site alterations or when a second pathogenic variant is missing in the case of likely recessive diseases. In these cases, targeted WTS has the advantage of applying a routine protocol and is cheaper and faster than targeting a specific transcript of a gene, also considering the complexity of alternative spliced isoforms.
Con: Only about 50% of all OMIM genes are sufficiently expressed in blood to support clinical GS (suppl. Fig. 2). Gene transcription is highly sensitive to environmental factors and thus highly variable between humans. We administer questionnaires to patients to collect information on factors influencing expression. Due to this complexity, WTS should be used in selected cases and not as a primary diagnostic method. However, this is different in somatic cancer diagnostics for treatment decisions where we sequence WTS in parallel to ES/GS.
Comments (0)