
Remember me
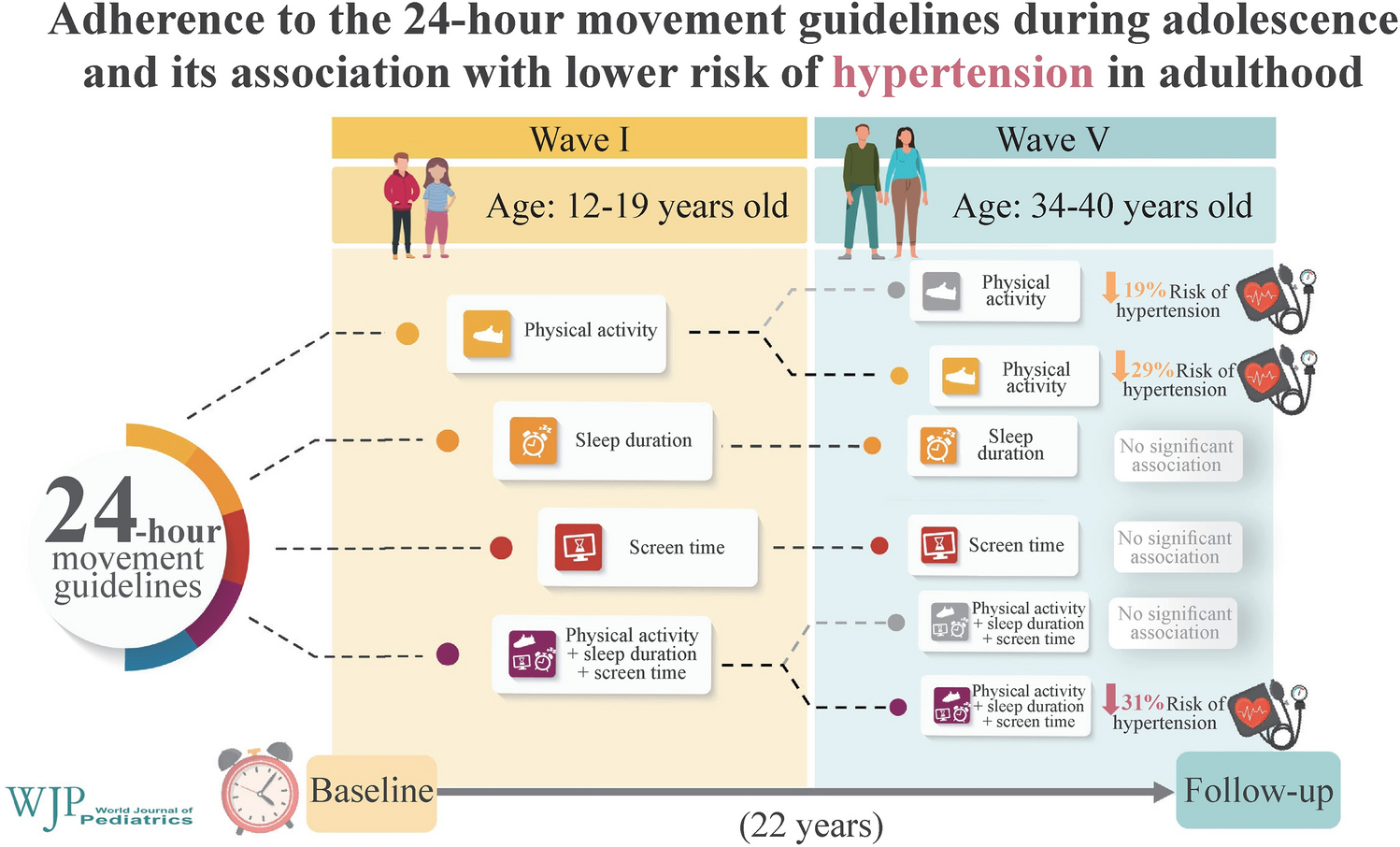


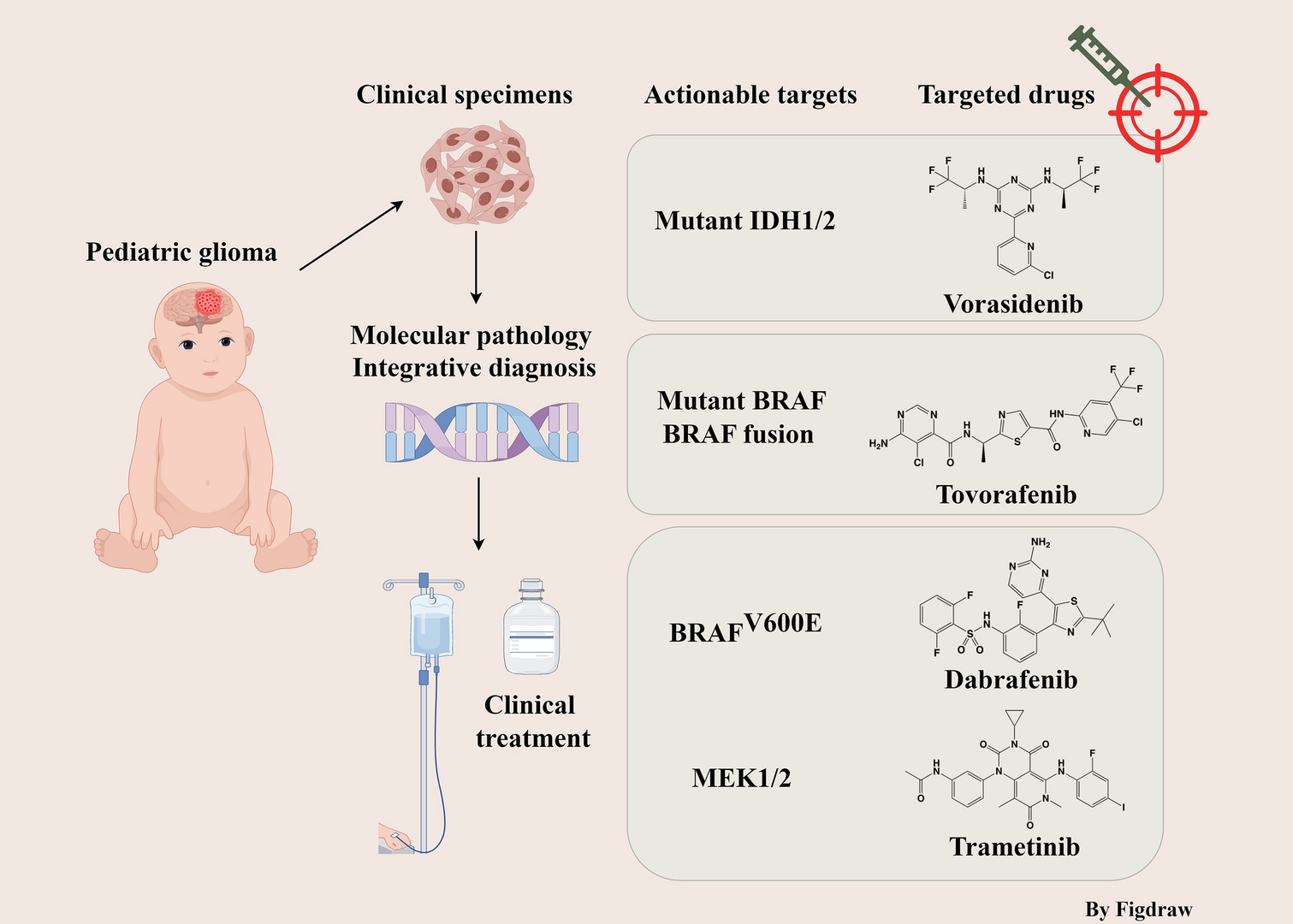
The metabolite dataset in the study was first summarized with highly correlated features removed, and then explored via unsupervised analysis. Median and range values for each metabolite were computed. A boxplot of the scaled and centered data, including 46 features, is shown in Supplementary Fig. S1. Analytical methods were then applied to the data to filter out highly correlated and irrelevant features, avoid overfitting, select the optimal feature signature for the MMA screening, and develop an optimized model. The correlation between features was assessed by Pearson correlation analysis and the highly correlated features were targeted for removal. Utilizing a convenient cutoff of correlation coefficient = 0.89, six features (C18:1OH, C16OH, C14:1, C12:1, C18OH, and C14OH) were found to be highly correlated to another feature in the dataset. Thus, these features were removed from the dataset for the downstream analysis to arrive at 40 features. The correlation matrix is presented in Supplementary Fig. S2. Next, we compared the two groups using the Wilcoxon test which assesses whether the mean values for each metabolite differ significantly from each other for the two classes. The results of the Wilcoxon test are depicted as violin plots in Supplementary Fig. S3 and with extended details in Table 1.
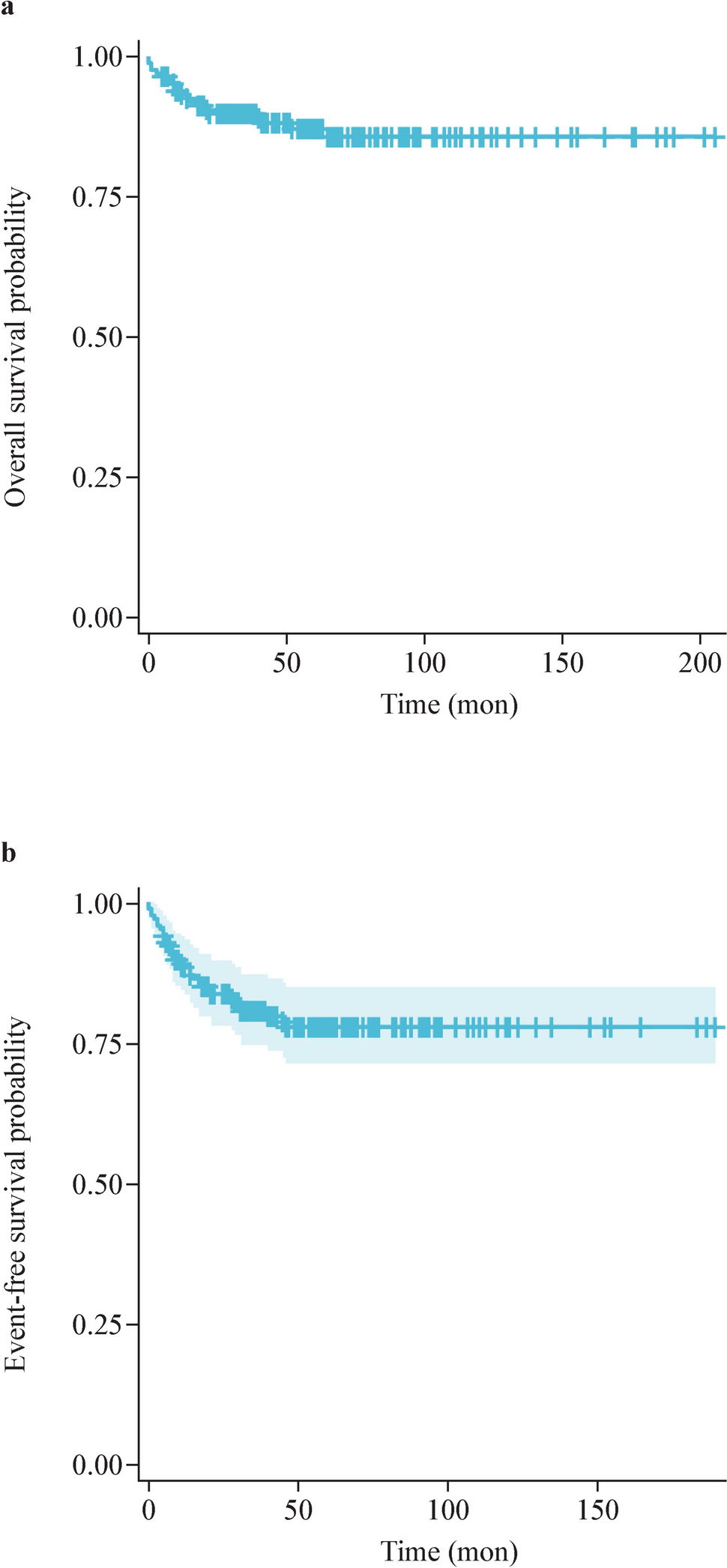
Table 1 Metabolites concentration levels and Wilcoxon test statistic comparing MMA-rejected (FP) and MMA-confirmed (TP) groupsUnsupervised analysis by uniform manifold approximation and projection, t-distributed stochastic neighbor embedding, and principal component analysesThe unsupervised methods t-SNE, UMAP, and PCA were carried out on the data. T-SNE was utilized to calculate a visualization of the structure of the data. The t-SNE-derived visualization of the 40 features revealed distinct group-specific separation (Fig. 2a). The figure shows the MMA-confirmed samples (red dots, n = 33) are clustered together and yet interspersed and enclosed within MMA-rejected samples class space (blue dots, n = 600).
Fig. 2
Unsupervised analysis results of t-SNE, UMAP, and PCA. a t-SNE visualization of the n = 40 analytes data. Class screen-TP/MMA-confirmed is shown as pink dots and class screen-FP/MMA-rejected is shown as blue dots. b UMAP visualization of the n = 40 analytes data. Class screen-TP/MMA-confirmed is shown as pink dots and class screen-FP/MMA-rejected is shown as blue dots. c PCA score plots for the PC1, PC2, and PC3. d Loading plots. UMAP uniform manifold approximation and projection, t-SNE t-distributed stochastic neighbor embedding, PCA principal component analyses, TP true positive, FP false positive, MMA methylmalonic acidemia, PC principal component, C0 free carnitine, C2 acetyl-carnitine, C16 hexadecanoyl-carnitine, VAL valine, MET methionine, PRO proline, TYR tyrosine, C3 propionyl-carnitine, PHE phenylalanine, C18 octadecanoyl-carnitine, C18:2 octadecadienoyl-carnitine, C10:2 decadienoyl-carnitine, C16:1OH 3-hydroxy-hexadecenoyl-carnitine, C8:1 octenoyl-L-carnitine, C3DC + C4OH malonyl-carnitine + 3-hydroxybutyryl-carnitine, C5:1 tiglyl-carnitine, C6DC methylglutaryl-carnitine, C10:1 decenoyl-carnitine, C10 decanoyl-carnitine, C8 octanoyl-carnitine, C5DC + C6OH glutaryl-carnitine + 3-hydroxyhexanoyl-carnitine, LEU leucine, CIT citrulline, C4 butyryl-carnitine, PHE phenylalanine, C6 hexanoyl-carnitine, ORN ornithine, ALA alanine, C14:2 tetradecadienoyl-carnitine, GLY glycine, C2 acetyl-carnitine, TYR tyrosine, C18:1 octadecenoyl-carnitine, C16 hexadecanoyl-carnitine
UMAP analysis was performed on the data before and after the correlation analysis. UMAP is a method utilized as a non-linear dimensionality reduction scheme as well as to find intrinsic structure and cluster members of a dataset; it can also be used to analyze different types of data. When performing UMAP analysis, a weighted k-nearest neighbor graph is first calculated, and then a layout in lower dimension is created. After that, the data can be graphed, visualized, and its global structure examined in the reduced-dimensionality space. Similar to the t-SNE results, UMAP shows clustering and enclosure of the positive class within the negative class space (Fig. 2b).
PCA achieved the following explained variance per component (PC1, PC2, and PC3): 27%, 12%, and 10% for a cumulative explained variance of 49% (Fig. 2c and d). Similar to t-SNE and UMAP, PCA shows clustering and enclosure of the positive class within the negative class space, thus more advanced machine learning methods can be utilized. Overall, the unsupervised results emphasize the need to employ supervised classification methods with further sophistication, suggesting that machine learning techniques could be employed to separate the classes.
Feature selectionFor feature selection, we used automatic feature selection methods that proceed to build a set of models and identify the features important in building an accurate classification model. The method we applied was SBF, which involved model fitting after applying univariable filters. This method is able to pre-screen the predictors using simple univariable statistical methods, but only use those that pass some criterion in the subsequent model steps. The following features were selected: ALA, GLY, MET, ORN, PHE, PRO, C0, C2, C3, C14, C16, hexadecenoyl-carnitine (C16:1), 3-hydroxy-hexadecenoyl-carnitine (C16:1OH), C18, octadecenoyl-carnitine (C18:1), C3/C0, C3/C2, C16/C3, and C3/MET. This was the feature set that resulted in the best model classification performance in the downstream modeling step.
For comparison, we also applied LVQ [36] and RFE with the RF algorithm. LVQ can be utilized to rank feature importance in generating a predictive model. This, and the related method of self-organizing maps, were developed by Kohonen et al. [37]. Using the varImp function in the caret package, we computed feature importance ranking for the 40 metabolites. A fivefold cross-validation was repeated 100 times. The most important features were ranked as C3/C2, C3/C0, C3/MET, C16/C3, MET, and C3, which is in concordance with the use of these features in clinical practice. Supplementary Fig. S4a shows the rankings of all 40 features.
Another automated method that we utilized was RFE, wherein a subset of features can be explored and the RF algorithm evaluates the model. All 40 features were selected in our analysis. The variables vs. ROC plot (Supplementary Fig. S4b) shows that using n = 18 variables achieves slightly better results. For the RFE algorithm, the selected features were CIT, GLY, MET, VAL, C0, C2, C3, malonyl-carnitine (C3DC) + 3-hydroxybutyryl-carnitine (C4OH), C5, C5DC + 3-hydroxyhexanoyl-carnitine (C6OH), C14, C16:1, C16:1OH, C18, C3/C0, C3/C2, C16/C3, and C3/MET.
Classification modeling by evaluating algorithms and stackingWe explored the performance of 14 classification models (Fig. 3a) utilizing the SBF feature selection features subset to identify candidate models for the stacking step. Results were obtained via a fivefold cross-validation, repeated 100 times. Most models achieved similar specificity, except for sparseLDA. The sensitivity results ranged from about 60% to 90% sensitivity, except for sparseLDA, which achieved a sensitivity of over 95%.
Fig. 3
Model assessments and stacking ensemble result. a Model assessments of ROC, sensitivity, and specificity of the 14 models to classify screen-positive MMA patients. b Stacking ensemble result included the algorithms RF, C5.0, sparse linear discriminant analysis, and autoencoder deep neural network stacked with the algorithm stochastic gradient boosting as the supervisor, using AUROC and FPR at 100% sensitivity. Results were obtained via a fivefold, 100 times repeated cross-validation utilizing the SBF feature selection derived feature set. ROC receiver operating characteristic curve, AUC area under the curve, MMA methylmalonic acidemia, AUROC area under the receiver operating characteristic curve, gbm stochastic gradient boosting, RF random forest, glmboost booted generalized linear model, LogitBoost boosted logistic regression, treebag bagged CART, dnn deep neural network, svmLinear support vector machines with linear kernel, lda linear discriminant analysis, sparseLDA sparse linear discriminant analysis, rpart CART, glm generalized linear model, knn k-nearest neighbors
The models were ranked by sensitivity and specificity and a set of four models combining the top two models in each category (RF and C5.0 for specificity, and sparseLDA and dnn for sensitivity) were stacked with gbm as the supervisor algorithm. Before the stacking, we confirmed that the predictions of the sub-model were not highly correlated (correlation coefficient > 0.89) as in this case; they would be making the same or very similar predictions, thus reducing the benefit of combining the predictions via the stacking approach. The additional three feature selection schemes: no feature selection, RFE-ROC, and LVQ were evaluated (Supplementary Fig. S5a, c, and e). The top-performing models in each of the three additional feature selection schemes are shown in Supplementary Table S1.
The best result was achieved using RF, C5.0, sparseLDA, and dnn, stacked with gbm as the supervisor. Evaluated in fivefold cross-validation repeated 100 times, the stacking approach achieved an AUROC of 97%, a sensitivity of 92%, and a specificity of 95%. When sensitivity was set to 95%, 99%, and 100%, the models achieved an FPR of 6%, 35%, and 39% respectively (Fig. 3b).
In comparison, we performed the stacking utilizing an additional three input feature sets: all the 40 features, the features selected by LVQ, and the features selected by RFE. These input sets resulted in inferior classification outcomes (Supplementary Fig. S5b, d, and f).
Comments (0)