Adverse drug events (ADEs), according to the World Health Organization (WHO), are defined as any injury or unfavorable condition sustained by an individual due to the intervention of drugs. It could be through a regular prescription, a drug overdose, or allergies, in contrast to adverse drug reactions (ADR), which are reactions caused by drugs during obvious drug use [1]. The process of reporting ADEs started over a long period, mainly through pharmacovigilance. Pharmacovigilance is a branch of research that follows up on medications throughout their lifespan to identify, evaluate, and comprehend any potential side effects and avoid harm or injuries that might result from them [1]. Clinical trials conducted during pre-approval surveillance are the basis for the conventional approach to reporting ADEs. However, one of the primary barriers to thorough monitoring of all ADEs is the limited number of volunteer patients willing to report their cases.
In the past few decades, though, the spontaneous reporting system (SRS) has been widely used to report drug ADEs. One major limitation of SRS is that it also suffers from underreporting up to about 90 % [2]. This issue could be due to the restrictions involved and the affected patients’ lack of courage in reporting the problem.
However, with the increased use of artificial intelligence (AI) and natural language processing (NLP) in medical text mining, there is more interest in automating the process of extracting ADEs from abundant unstructured clinical notes due to their significance in a real-life environment. ADE extraction research has been encouraged by several public challenges. They include the Text Analysis Conference (TAC) challenge 2017 [3], the national NLP clinical challenge (n2c2) 2018 [4], and the Medication, indication, and Adverse Drug Events (MADE 1.0) challenge 2018 [5]. These challenges have given room for researchers in the field of AI and NLP to develop different methods and approaches for the extraction of ADEs, their related attributes, and relations between them from clinical free text.
ADE studies can be divided into three categories: ADE detection, ADE prediction, and ADE understanding. ADE detection studies attempt to identify new and previously undetected ADE effects caused by an existing drug already used in the public domain. These studies employ data mining and NLP techniques on a public dataset derived from electronic health records or social media data. ADE prediction studies are the second category. These studies involve forecasting a new ADE signal for a drug before it happens to the patient. This category uses machine-learning-based methods to predict the possible drug effect based on the information obtained from other medications that share similarities with the new drug. The last category is ADE understanding studies. This category involves developing mechanisms for verifying and understanding how a particular drug causes ADE. This approach is popular in pharmacoepidemiology and pharmacometrics studies [1]. In this review, we included studies based on ADE detection and prediction.
We identify studies based on rule-based, machine learning, deep learning, hybrid, and large language model approaches to text mining and clinical text extraction. A rule-based method involves curating a set of rules to extract relevant information from textual data using regular expressions, linguistic pattern matching strings [6], and other techniques. The machine-learning approach is a statistical method of recognizing patterns in data, in contrast to rule-based methods. It involves using algorithms to classify data into various categories [7]. Deep learning, as a subgroup of machine learning, uses advanced algorithms based on artificial neural networks inspired by the human brain [8]. The hybrid approach combines two independent methods into one concrete method to solve a given problem, such as combining machine learning and rule-based systems. The large language models (LLMs) are transformer-based models trained on huge datasets and fine-tuned on downstream tasks.
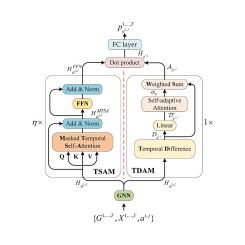
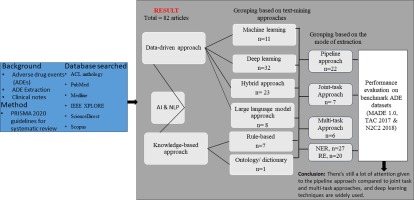
Moreover, we further group studies based on the mode of extracting ADEs, specifically the pipeline approaches [9], [10], [11], [12], joint task approaches [13], [14], [15], [16], and multi-task learning approaches [2], [17]. The pipeline approaches are the studies that developed separate models for ADE named entity recognition (NER) and relation extraction (RE) tasks, where the output of one model served as the input to the next model. The multi-task learning approach involves training the model on multiple related tasks, via hard or soft parameter sharing.[18]. The joint task approach, is a form of multi-task learning approach where two or more models are trained on related tasks softly sharing parameters [19], [15]. Fig. 1 depicts a taxonomy of ADE identification strategies.
Furthermore, to encourage more research innovations in adverse drug events extraction, we report top performing systems based on the above categories of approaches for extracting ADEs. The aim is to analyze the benchmark performances based on the popular public datasets for ADE extraction. This gives room for methods to advance the state-of-the-art in this field of research.
We found relevant systematic reviews that reported on the extraction of adverse drug events in the fields of AI and NLP using electronic health record datasets. Warrer et al. [20] conducted a review that covers research from 2001 until 2011 that uses NLP and AI techniques for ADE detection from clinical notes. Next is the work of Feng et al. [21], who conducted a systematic review to report methods that have been developed for detecting ADEs in outpatient hospital services using electronic health records and are published before 2017. Another work is the review by Ramos et al. [22], which reported studies with methods for detecting ADR in infants. The studies are grouped into three categories: active, passive, and combined. In addition, the review by Salas et al. [23] identified and reported systems that use AI in pharmacovigilance from 2015 to 2021, including for ADE and ADR detection, drug-drug interaction detection, processing safety reports, and identifying patients at high risk of ADR. Despite being instructive, these reviews do not go into the specifics of the AI and NLP approaches, methods, and datasets used to extract ADEs, their attributes, and relations from clinical notes, which is the primary goal of this systematic review. Supplementary Table A1 depicts a chronological summary of these surveys. To the best of our knowledge, this is the first review that identifies and reports studies for extracting ADEs, and groups them based on pipeline, joint task, multi-task and LLM learning implementation approaches.
The main contributions of this work are:
1.
A comprehensive survey of literature based on the adverse drug events extraction problem.
2.
Identification of the various methods developed, and their grouping based on the pipeline, joint task, and multi-task learning approaches, as well as based on the rule-based, machine, deep and LLM learning approaches.
3.
Identification of various benchmark datasets used for adverse drug extraction problems.
4.
An analysis of various methods highlighting their advantages and disadvantages for the ADE extraction problem.
5.
Report on the state-of-the-art performance of this research direction.
6.
Future research directions in this area based on the findings that require further investigation.
The organization of the remainder of this work is as follows: the next section defines the problem then explains the method of conducting this review, from the database search to the selection of the included papers. The following section is the result section, which contains information about the final included works and an analysis of the review. The next section is a performance comparison of various approaches on some benchmark datasets. The discussion section follows afterwards, then the future research directions, and finally the conclusion of the work.
Statement of significance.
Problem: Discovering various approaches and modes of ADE extraction, datasets used and the state-of-the-art performance in them, and future research opportunities.
What is Already Known: Clinical narrative document contains patient information including ADEs. Extracting ADE information combines the dual tasks of named entity recognition and relation extraction. Research in NLP have demonstrated various approaches for handling these challenging tasks.
What This Paper Adds: This work surveyed the recent proposed approaches for ADE extraction, critically highlighting their advantages and disadvantages. The work further grouped them into pipeline, joint task, multitask learning, and LLM approaches, and compared the performance of these approaches on popular benchmark datasets. Challenges and future research directions have been identified for further investigation to improve state-of-the-art performance in this field of research.
ADE extraction is a dual task involving NER and RE. This task begins by identifying named entities within a sequence of tokens, denoted as S=, where n represents the sequence length. The goal is to identify a set of positive entities E= that have one or more relations with ei where ei ∈ E., and a set of relations denoted as R=.
Given the challenging nature of this task, various NLP challenges and publicly available datasets have been developed. Among the popular ones are MADE 1.0, TAC 2017, and the 2018 n2c2 challenge datasets. These datasets are characterized by complex scenarios, including annotation inconsistencies, imbalanced classes, ambiguous entities, and multiple and long sequence relations, among other challenges. Refer to Supplementary Table A6 for a detailed description of the datasets, including task performed, dataset size, features extracted and the challenges.
For instance, Fig. 1 in Appendix B, example (a) illustrates a typical sample of an ambiguous entity where “diarrhea” is annotated as the reason for an ADE in sentence (a) but annotated as an ADE in sentence (b). Example (b) highlights the challenge of long sequences and multiple relations, where a relation exists between “Dilantin [DRUG]” in sentence 1 and three entities “fever [ADE]”, “weakness [ADE]”, and “diarrhea [ADE]” in sentence 4. Furthermore, Example (c) demonstrates a case of disjoint/discontinuous mention with “platelet count low [ADE]” having the token “(” in between “platelet count” and “low,” which is connected to the string “less than 50*10^9 /L.”.


留言 (0)