Procedure
This study received approval from the Institutional Review Board (IRB) of the corresponding author's affiliated institution, ensuring compliance with human research ethics. Written informed consent was obtained from both participants and their parents. The survey was conducted as part of a psychological screening initiative for students by the local schools, and review personnel underwent appropriate training.
Moreover, to ensure the quality of the data, we excluded invalid questionnaires before formal analyses. Data were considered invalid if one or more question response was missing. Based on the above screening criteria, we excluded 78 invalid samples (1.3%) and retained 5958 valid samples.
Participants
For this study, data were collected in twelve schools in China, including middle school, high school, and secondary vocational schools (students of the secondary vocational-technical school are considered high school students in the following study since they had completed their middle school education). A total of 5958 middle school students completed the PHQ-9, spanning the age range of 11–19 years (in the adolescent stage). The mean age of the participants was 13.484 (SD = 1.627), and the sample included 3109 boys (52.17%) and 2850 girls (47.83%). Of the total sample, 2216 were high school students (37.2%), and 3742 were middle school students (62.8%).
Measures
Mental health problems were measured by the PHQ-9. The PHQ-9 is a modified version of the PHQ and consists of nine questions. It scores each of the nine symptoms of the DSM-IV criteria according to the frequency of symptoms, namely, the number of symptoms occurring in the two weeks before testing. The scale has four options for each item, ranging from 0 = never to 3 = almost every day, for a total score of 0 to 27.
Statistical analysis
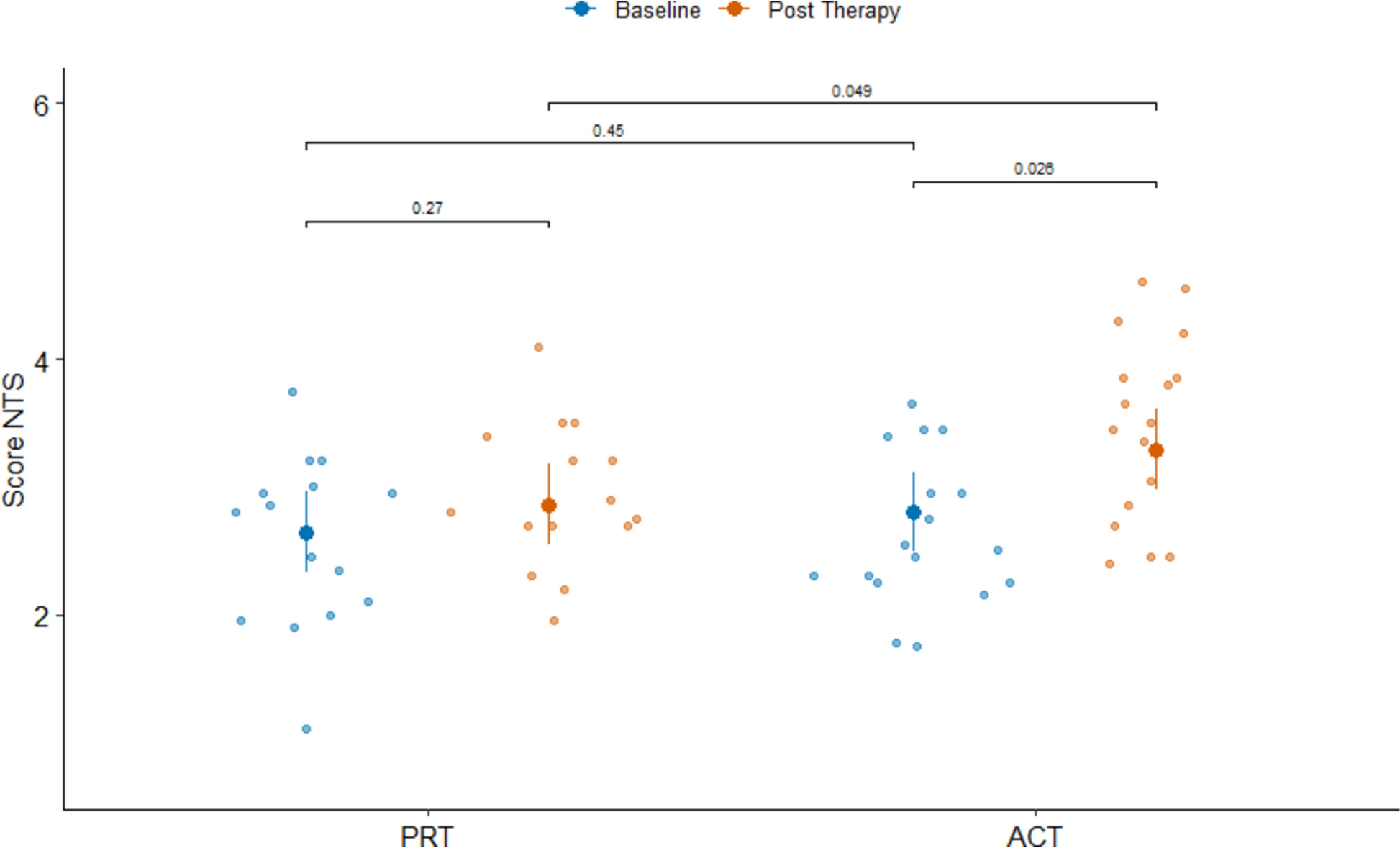
Statistical analysis was performed using R studio 4.2.2 and IBM SPSS Statistics 29.0 software. The current study had some key goals. First, for normality test: the kurtosis of each item in the scale ranged between 2.220 and 6.711, and the skewness ranged between 1.799 and 2.698. The kurtosis of the total score was 3.381, and the skewness was 1.872. The kurtosis was less than 7, and the skewness was less than 2, indicating that the data were basically normally distributed [35]. Second, the PHQ-9 was assessed to determine whether it met the assumptions of item response theory (unidimensionality, monotonicity, and local independence). Third, the model that best fit the data was selected. Fourth, the functionality of items was assessed using item discrimination, threshold, and item fit. Finally, DIF analyses were used to examine whether there was measurement invariance of depressive symptoms based on PHQ-9 measures across gender and grade levels.
IRT assumption checkUnidimensionality
To explore the robustness of this assumption, we used three methods. A scale was considered one-dimensional if a factor accounted for at least 20% of the variance [36]. Based on this, this study conducted an exploratory factor analysis using the “fa” function in the “psych” package [37] in R to determine whether the scale was unidimensional. In addition, we used the ratio of eigenvalues and confirmatory factor analysis (“lavaan” package) to determine whether the scales were unidimensional [38]. As a rule of thumb, if the ratio of the first eigenvalue to the second eigenvalue is greater than 3, it indicates unidimensionality [39]. The confirmatory factor analysis is guided by the following indicators, namely, the comparative fit index (CFI; ≥ 0.95 for good, ≥ 0.90 for acceptable), the Tucker–Lewis index (TLI; ≥ 0.95 for good, ≥ 0.90 for acceptable), the root mean square error of approximation (RMSEA; ≤ 0.06 for good, ≤ 0.08 for acceptable), and the standardized residual root (SRMR; ≤ 0.06 for good, ≤ 0.08 for acceptable) with its 90% confidence interval.
Monotonicity
The monotonicity index is Hi and is interpreted as follows: low quality: 0. 3 < Hi < 0. 40, moderate quality: 0. 40 < Hi < 0. 50, and high quality: Hi < 0. 50 [40]. In our study, the “mokken” package [41] in R software was used to calculate monotonicity with the “check. monotonicity” function.
Local Independence
In this paper, local independence is measured in two ways, with Yen's Q3 statistic [42] and Cramer's V statistic. A previous study stated that a value of Q3 above 0.36 suggests moderate deviation and dependence [43]. Cramer’s V is a measure of goodness of fit that determines the independence between variables, and a value below 0.2 indicates independence. For the evaluation of local independence, this paper uses the “residuals” function in the “mirt” package [44].
Model fit
IRT differs from CTT in that IRT uses data to fit models and mathematical models to estimate item parameters, participant traits, and other measurement information, while three polytomous IRT models are selected for comparison based on the characteristics of the PHQ-9 in this paper: the generalized partial credit model (GPCM), the rating scale model (RSM) and the graded response model (GRM). Consequently, the “mirt” function is used in the “mirt” package for the Akaike information criterion (AIC), Bayesian information criterion (BIC), Hannan–Quinn criterion (HQ), and likelihood ratio test (LRT) calculations to compare models and to estimate items and individual parameters.
Functional assessment of items
The discrimination parameter is an indicator measuring the sensitivity and discriminative power of each item in a measurement tool to the latent traits of the examinees. Threshold parameters play a crucial role in capturing the transition points between response options and indicate the ability levels at which individuals have a 50% probability of shifting from one response option to the next. For example, the first threshold parameter marks the boundary at which participants move from selecting the first response option (e.g., “never”) to choosing the second option (e.g., “several days”). In addition, the fit of the item was tested by \(X^2 - RMSEA\), and if the RMSEA was less than 0.6, the item was considered to have good fit. Additionally, we calculated the factor loadings for each item and the amount of information it contained.
Differential item functioning
The best-fit model was used as the basis; at the same time, this paper weighed the p-value using the “DIF” function from the “mirt” package and effect size examined, with the groupings based on gender and educational year.
In this study, gender and grade differences were examined by calculating the likelihood-ratio test (IRT-LR) for DIF. Due to the large sample size of the study, p < 0.001 was selected as the DIF indicator. For each item of the PHQ-9, in the interim, we further checked the effect size by two formulas: \(ABS \, ((2 \, * \, (\alpha_g - \alpha_} )/ \, (1.7*\alpha_} \, *\alpha_} )) \, * \, LN \, (2))\) for the discrimination parameter (\(\alpha\)) and \((\beta ) = \beta_ - \beta_}}\) for the threshold parameter. It was considered statistically significant when the effect size was > 0.4.
ROC curve analysis
The primary outcome variable is the area under the ROC curve (AUC) [45]. The AUC is interpreted as the probability that a randomly selected respondent will be correctly assigned to the appropriate group [46], directly reflecting the overall accuracy of the instrument in screening for depression. An AUC of 0.5 indicates random performance, while a value of 1 indicates perfect performance. Specifically, values ranging from 0.9 to 1 indicate excellent predictive accuracy, values from 0.8 to 0.9 indicate good accuracy, values from 0.7 to 0.8 indicate fair accuracy, values from 0.6 to 0.7 indicate poor accuracy, and values from 0.5 to 0.6 indicate unacceptably poor accuracy [47, 48].


Comments (0)