

記住我



Brain–computer interface (BCI) technology realizes direct communication and control between the brain and electronic devices based on cortex electrical signals. By not relying on conventional brain output pathways, BCI opens up entirely new ways for the human brain to communicate and control information with the outside world (Maslova et al., 2023). There are many patterns of brain electrical signals in BCI: electroencephalogram (EEG), electrocorticography (ECoG), functional magnetic resonance imaging (fMRI), and positron emission tomography (PET) (Sharma et al., 2023). The EEG is extensively applied to collect brain signals in BCI systems since it is inexpensive, portable, and non-invasive, and has relatively high temporal resolution (McFarland and Wolpaw, 2017; Padfield et al., 2019). Common EEG-BCI systems include steady-state visual evoked potential (SSVEP), event-related P300, N400, motor imagery (MI), and slow cortical potential.
Over the past 2 decades, many researchers have focused on the research of BCI based on motor imagery (MI) (Pfurtscheller and Neuper, 2001; Chepurova et al., 2022) and have confirmed its application as neurorehabilitation (Brusini et al., 2021; Choy et al., 2023), neuroprosthetics (Neuper et al., 2006), and gaming (Laar et al., 2010). Motor imagery might be seen as a mental rehearsal of a motor act without any overt motor output and could activate certain brain regions (Pfurtscheller and Neuper, 2001). Sensory stimulation, motor behavior, and mental imagery could change the functional connectivity within the cortex and result in an amplitude suppression [event-related desynchronization (ERD)] or in an amplitude enhancement [event-related synchronization (ERS)] of mu and beta rhythms. Mu rhythm is in the range of 7–13 Hz, and the beta rhythm is in the range of 13–30 Hz, both originating in the sensorimotor cortex (Blankertz, 2008).
The classical EEG-BCI system mainly consists of signal acquisition, signal processing, classification recognition, and feedback/application. The signal processing includes signal preprocessing, feature extraction, and feature selection. The main purpose of signal preprocessing is to remove artifacts. Feature extraction means extracting features from clean EEG signals and common extraction methods include discrete wavelet transform (DWT) (Zhou et al., 2018), empirical mode decomposition (EMD) (Mohamed et al., 2018), power spectral density (PSD) (Rodríguez-Bermúdez and García-Laencina, 2012), Hilbert transform (Zhou et al., 2018), and common spatial pattern (CSP). Feature selection could eliminate irrelevant or redundant features so as to reduce the number of features, improve model accuracy, and reduce running time.
The basic principle of the CSP algorithm is to use the diagonalization of the matrix to find a set of optimal spatial filters for projection so as to maximize the difference between the variance values of the two types of signals and obtain a feature vector with a high degree of differentiation (Blankertz et al., 2007; Benjamin Blankertz et al., 2008; Blankertz, 2008; Vidaurre et al., 2009). The CSP is widely used to extract features (Blankertz et al., 2007; Li et al., 2011; Tangermann et al., 2012; Baig et al., 2017; Li et al., 2017). For the MI-BCI system, the effectiveness of CSP is highly affected by the frequency band and time window of EEG segments and channels selected (Blankertz, 2008; Miao et al., 2017a,b).
In general, before feature extraction using CSP, EEG signals are filtered within a fixed broad frequency band, e.g., 8–30 Hz (Jin et al., 2019; Jin J. et al., 2020) and 4–40 Hz (Zhang et al., 2015, 2021; Jiao et al., 2019, 2020). However, given the intrasubject variability in the frequency band of reactive components (Pfurtscheller et al., 2006), selecting subject-specific optimal frequency bands contributes to the extraction of discriminative features. The existing studies have confirmed that variants of CSP [SBCSP (Quadrianto Novi et al., 2007), FBCSP (Ang et al., 2008), DFBCSP (Thomas et al., 2009), and SFBCSP (Zhang et al., 2015)] could improve the classification rate of MI by optimizing the optimal frequency band using mathematical statistics.
Most existing studies utilize a fixed time segment to extract features by CSP, which results in suboptimal feature extraction since the time interval when the brain responses to the mental tasks occur may not be accurately detected. Therefore, an appropriate time window of EEG should be preselected to cover the interval when the EEG pattern is activated and remove those unrelated sampling points. The correlation-based time window selection (CTWS) was developed for MI-based BCIs (Feng et al., 2018). The two Parzen window-based method was proposed to select the discriminative feature subset and subject-specific time segment (Wang et al., 2020). Furthermore, the effectiveness of CSP is highly affected by the frequency band and time interval of EEG segments.
The frequency band and time interval selection mainly include heuristic ways and the mathematical optimization method. On the one hand, some studies use the heuristic method to optimize features in multiple time windows and bandwidths (Ang et al., 2012; Zhang et al., 2019; Miao et al., 2021; Yuan et al., 2021). The main purpose is to optimize the selection of the frequency band and time interval and then carry out feature extraction. On the other hand, the main idea of the mathematical optimization method is to divide time intervals and frequency bands, obtaining multiple sub-bands and time segments. Then, the high-dimensional feature sets are constructed by extracting features on sub-bands and time segments through the CSP algorithm and selecting features through mathematical optimization or statistical methods. Most commonly, the time-frequency feature selection by LASSO includes TSGSP (Zhang et al., 2019), CTFSP (Miao et al., 2021), and mutual information (Ang et al., 2012).
Apart from frequency band and time window optimization, another important issue to consider is the determination of an appropriate EEG channel combination for the spatial pattern. Channel selection can improve performance and user comfort while reducing the cost of the system (Xu et al., 2021). Recently, numerous channel selection methods, working toward either selecting the most effective channels or eliminating noisy channels, have been proposed for motor imagery EEG applications (Jin et al., 2019; Jin J. et al., 2020; Qi et al., 2021; Faye and Islam, 2022).
The above-mentioned methods are targeted at frequency band, time interval, time-frequency feature optimization, and channel selection to improve the performance of MI-BCI. Furthermore, there are also studies to optimize the features of the spatial-frequency domain or time-frequency-spatial domain. Multi-view learning aims to improve the learning performance of target tasks by using the relationship or mutual learning between view data (Xu et al., 2013). According to different perspectives of specific learning tasks, it can be divided into the multi-view classification method (Yu et al., 2014; Bekker et al., 2016), multi-view clustering method (Zhao et al., 2014; Wang et al., 2016), and multi-view feature selection/dimensionality reduction method (Yuan et al., 2021; Qiang et al., 2022). The multi-scale optimization (MSO) method was proposed by introducing multi-view feature selection to optimize filter bands over multiple channel sets within CSPs (Jiao et al., 2020). Moreover, a novel framework termed the time window filter bank common spatial pattern with multi-view optimization was proposed (Huang et al., 2021).
Likewise, some studies have been mainly centered around investigating either frequency band and time window selection or spatial-frequency optimization. Few studies focus on joint optimization of time-frequency-spatial features. In this study, a novel framework termed multi-domain feature joint optimization (MDFJO) based on multi-view learning is proposed to select the discriminative features. Our contributions are summarized as follows:
1. We investigated the joint optimization of the filter bands and time intervals over multiple channel sets within CSPs by multi-view learning.
2. On the basis of selecting features, the feature sparsification strategy was studied to reduce the feature dimensionality.
3. Two public motor imagery EEG databases were used, and the performance of the proposed method was compared with existing methods to verify its effectiveness.
The rest of the article is organized as follows. The proposed MDFJO method is illustrated in the Method section. The experimental results are described in detail in the Results section. In the Discussion section, we analyzed the parameters and discussed the potential extensions of our method for future studies. Finally, a summary of this study is given in Section 5.
2 MethodIn this part, EEG data, channel selection, and feature extraction methods are described, followed by a detailed presentation of the proposed method MDFJO. Furthermore, the parameters of the proposed method and the comparison method are selected. First, two EEG public datasets for validation of the method are described below.
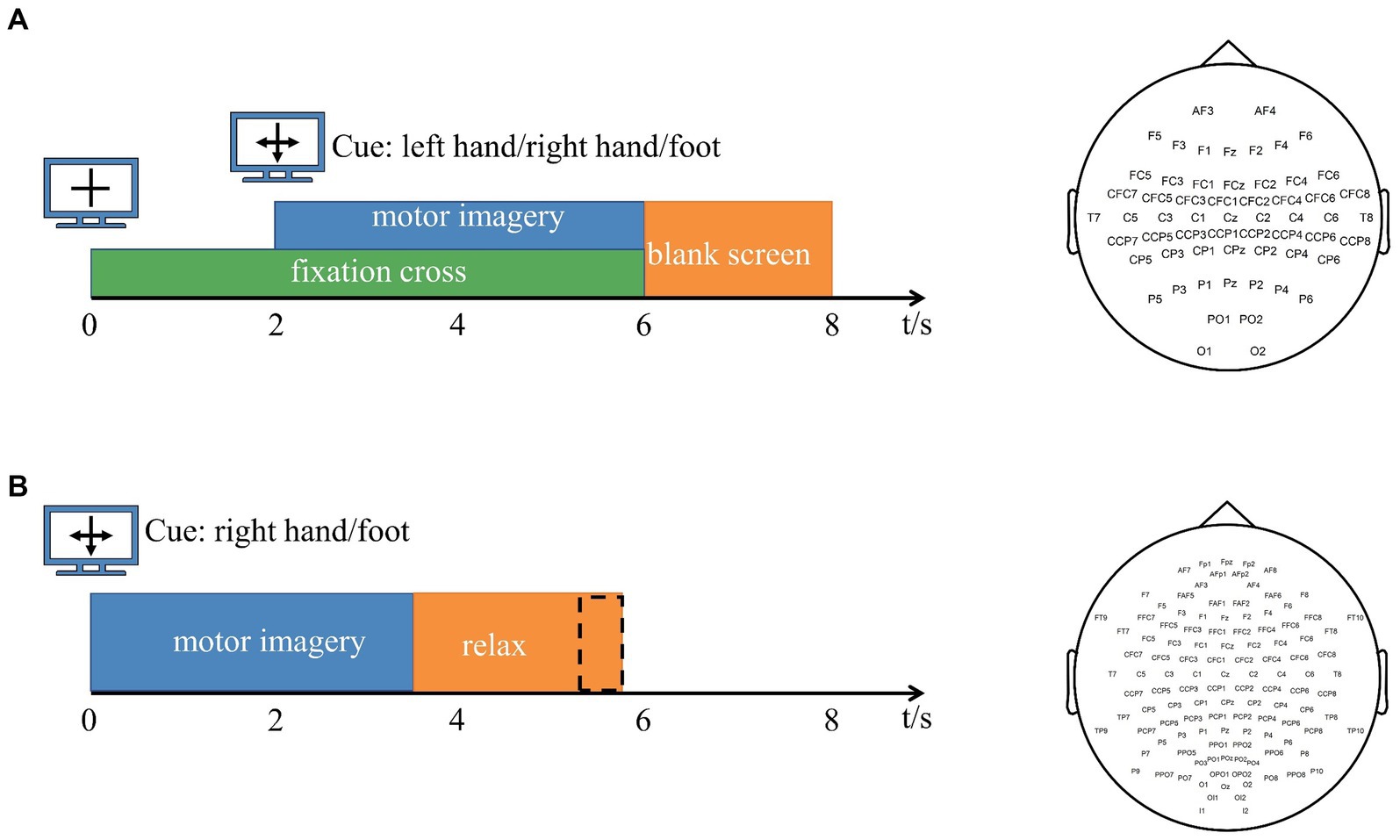
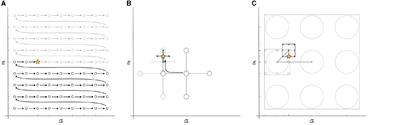
2.1 EEG Data1. Data 1: The dataset is derived from BCI Competition IV dataset 1 (Tangermann et al., 2012). The EEG signals of seven participants (“a,” “b,” “c,” “d,” “e,” “f,” and “g”) were recorded, and the number of channels was 59. The data of each participant included calibration data for 200 trials and test data for 200 trials, and the calibration data were used in this study. In each trial, each participant performed a pre-set motor imagery task (right hand and left hand or foot) for 4 s. For subjects “a” and “f,” the motor imagery task involved the left hand and foot. Other subjects performed left- and right-handed motor imagery tasks. The sampling frequency is 100 Hz. The timing scheme of the paradigm and channel arrangement are shown in Figure 1A.
2. Data 2: BCI Competition III dataset IVa (Blankertz et al., 2006) was used for experimental method validation in this study. The EEG signals of five subjects (“aa,” “al,” “av,” “aw,” and “ay”) were included, and the number of channels was 118. The raw data are downsampled to 100 Hz. Each participant performed 280 trials. In each trial, each subject performed a pre-set motor imagery task (right hand and right foot) for 3.5 s. The timing scheme of the paradigm and channel arrangement are shown in Figure 1B. Both channel arrangement conforms to the 10–20 international standard lead system.
Figure 1. (A) Experimental paradigm and channel arrangement for BCI Competition IV dataset 1. Arrows pointing left, right, or down have been presented as cues for imagining left hand, right hand, or foot movements. After a fixation cross was presented for 2 s, the directional cue was overlaid for 4 s. Then, the screen was blank for 2 s. The number of channels is 59. (B) Experimental paradigm and channel arrangement for BCI Competition III dataset IVa. Within 3.5 s of the visual cues display, the subjects performed the right hand or right foot motor imagery according to the cue. The presentation of target cues is intermitted by periods of random length, 1.75 to 2.25 s, in which the subject could relax. The number of channels is 118. The channel arrangement of Data 1 and Data 2 follows the 10–20 international standard lead system.
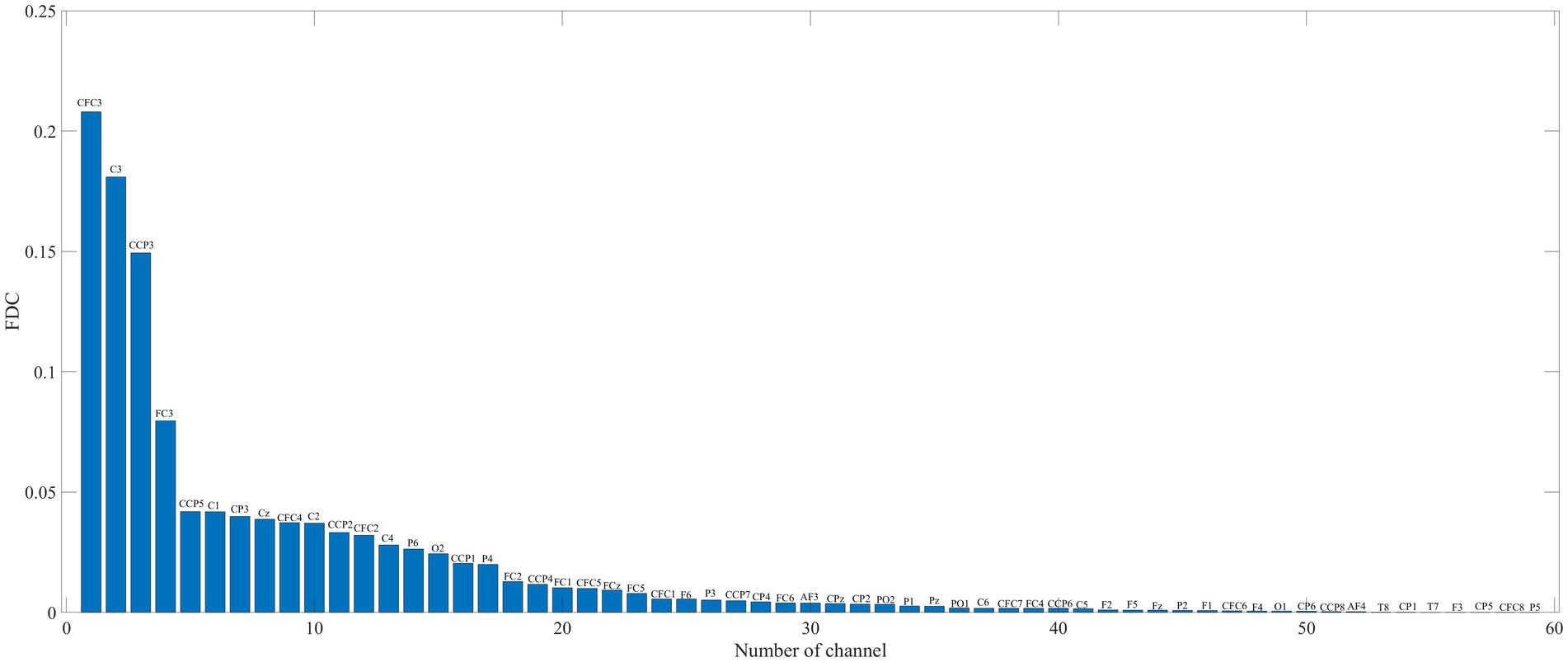
2.2 Channel selection and feature extractionThe continuous EEG data for each dataset are segmented into single-trial data, and then common average reference (CAR) is applied for the spatial filter to enhance the signal-to-noise ratio (McFarland et al., 1997). Furthermore, a fifth-order Butterworth band-pass filter (4–40 Hz) is used for filtering the EEG signal (Jiao et al., 2019, 2020). Channel selection aims to select the channel combination with the most feature difference for a specific subject to obtain better classification performance. The FDC is regarded as the channel selection method. The discriminative power of each channel is calculated by the FDC value between the two classes. First of all, time segmentation is conducted by using rectangular time windows (100 points) and the length of signal (250 points) for Data 1 (100 Hz × 4 s) and Dataset IVa (100 Hz × 3.5 s), respectively. The 50% overlapping is used in neighboring t-segments for two datasets. Pch,t=log(var(xch,t)) is calculated as the feature of each segment, where xch,t is signal data of the t-segment for channel ch. Pch,t denotes log-power. Then, the FDC value between two classes is ϕch,t=(m1−m2)2/(var(Pch,t1)+var(Pch,t2)) , where m1 and m2 are means of Pch,t of all trials in two classes, Pch,t1 and Pch,t2 denote log-power of two classes, respectively. Finally, the maximum FDC of all t-segments is taken as the FDC value of each channel. The FDC values of all channels are arranged in descending order, and the channels corresponding to the first FDC values are selected in this study.
The common spatial pattern (CSP) is an efficient feature extraction algorithm that has been widely utilized in MI-based BCI systems. CSP is realized by the simultaneous diagonalization of two classes of signal-covariance matrices. After removing the mean value of the preprocessing data, the single-trial EEG data were represented as a matrix Xd∈RM×T , where M is the number of channels and T is the time point for each channel. Xd,d∈ represents the EEG signal of class d. CSP seeks projection vectors by maximizing the ratio of the transformed data variance between two classes. The optimal spatial filters W=[w1,…,w2m]∈RM×2m were formed with the first and last m projection vectors. Finally, the EEG data of each trial X were projected by W to obtain the new signal Z=WTX . In this study, m = 1. Feature vector fp is expressed as follows:
fp=log(var(Zp)),p=1,…,2m (1)The two types of features were obtained by the CSP algorithm, and the features and corresponding labels were imported into the classification algorithm to train the classifier. A support vector machine (SVM) classification method with a radial basis function kernel is applied (Chang and Lin, 2007).
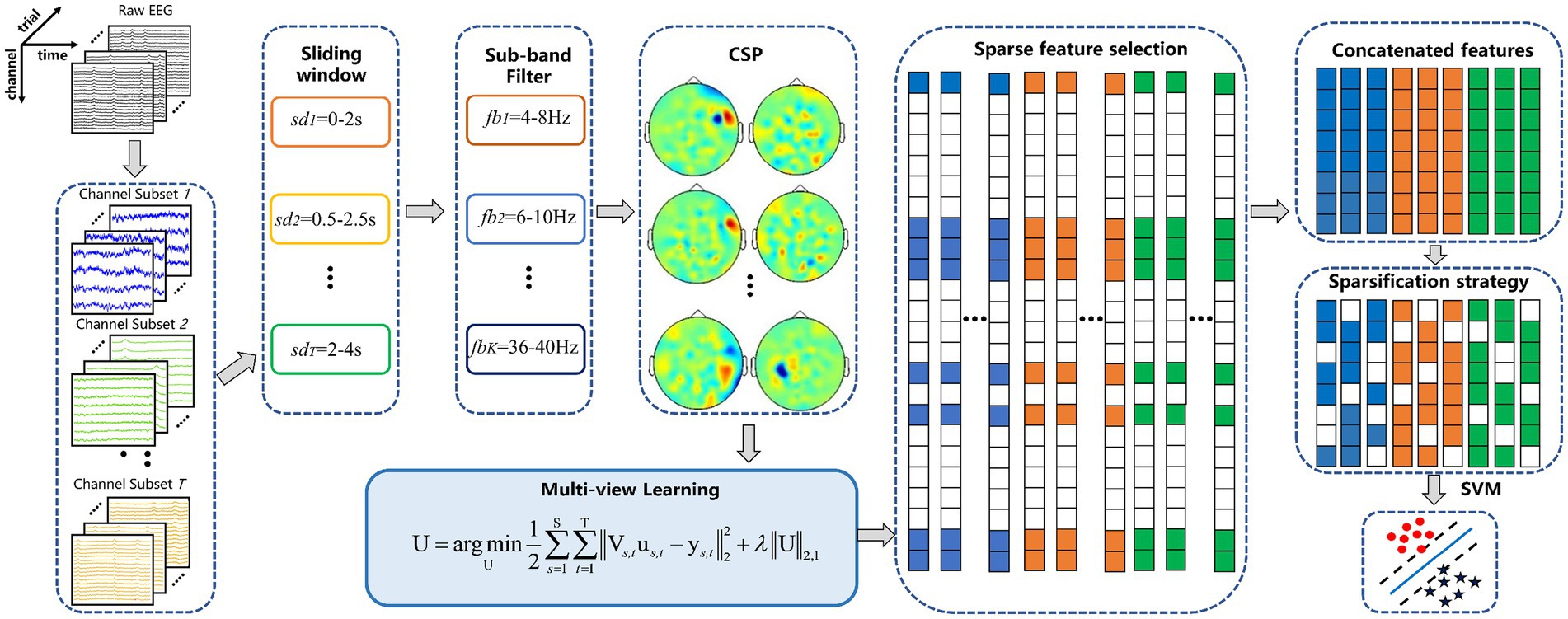
2.3 Multi-domain feature joint optimizationThe proposed MDFJO method mainly includes a channel pattern division based on FDC, sub-band division, and time interval division, which is feature selection based on multi-view learning and feature sparsification strategy and MDFJO method implementation steps.
2.3.1 Channel pattern division based on FDCThe FDC was used to compute the channel weights and sort the channel in descending order. The subject b from Data 1 is taken as an example, and its FDC value is shown in Figure 2. All channels were decomposed into a three-channel mode. More specifically, the first 16 channels are selected in descending order as a channel combination mode, namely, channels CFC3 to CCP1. According to the above principle, we get a combination mode of 32 channels, namely, channels CFC3 to CP2. Furthermore, all channels are regarded as in a combination mode. In this study, there were three modes, s1 = 16 and s2 = 32. The third mode is to use all the channels, for Data 1, s3 = 59, and Data 2, s3 = 118.
Figure 2. FDC value of subject b from Data 1. Channel labels are displayed on each bar.
2.3.2 Sub-band and time interval divisionThe EEG signals in each channel mode are divided into time interval with a time window length of 2 s and an overlap time length of 0.5 s. For Data 1, each channel mode has five time intervals, namely, t1 = 0–2 s, t2 = 0.5–2.5 s, t3 = 1–3 s, t4 = 1.5–3.5 s, and tT = 2–4 s. For Data 2, there are only four time intervals, namely, 0–2 s, 0.5–2.5 s, 1–3 s, and 1.5–3.5 s because the length of motor imagery time is 3.5 s. After that, the EEG signals in the 4 to 40 Hz frequency band in each time window were filtered by 4 Hz bandwidth and 2 Hz overlap frequency width. Thus, 17 filtering sub-bands are obtained. The frequency band of 4–40 Hz is divided, the bandwidth is 4 Hz, the overlap rate is 50%, that is, 4–8 Hz, 6–10 Hz, 8–12 Hz…, 36–40 Hz, totaling 17 sub-bands. Subsequently, the CSP features were extracted from each sub-band EEG signal.
2.3.3 Feature selection based on multi-view learningIn the real world, an object is often described by multiple views. For example, an image has various heterogeneous features through different descriptors, such as RGB, LBP, HOG, and SURF. Different views represent different aspects of an object and can provide more information than a single view. In the past decades, according to different perspectives of specific learning tasks, it can be divided into multi-view classification method (Yu et al., 2014; Bekker et al., 2016), multi-view clustering method (Zhao et al., 2014; Wang et al., 2016), and multi-view feature selection/dimensionality reduction method (Yuan et al., 2021; Qiang et al., 2022). In the multi-view learning process, the collected multi-view dataset is apt to be high-dimensional, which is prone to dimension disasters. Hence, it is necessary to remove redundant features in multi-view data. Therefore, the multi-view feature selection has received wide attention.
The multi-view learning-based sparse optimization was proposed to jointly extract robust CSP features with L2,1-norm regularization, aiming to capture the shared salient information across multiple related spatial patterns. The method is termed as the multi-scale optimization (MSO) (Jiao et al., 2020). The MSO considers the optimization of the CSP feature set extracted from the spatial pattern and sub-band group and does not consider the influence of time window division on the multi-view learning model. The characteristics of CSP are affected by spatial pattern, frequency band, and time interval. On the basis of the MSO method, we consider time factors to optimize filter bands and time intervals over multiple channel sets within CSPs by multi-view learning. The novel framework is termed multi-domain feature joint optimization (MDFJO).
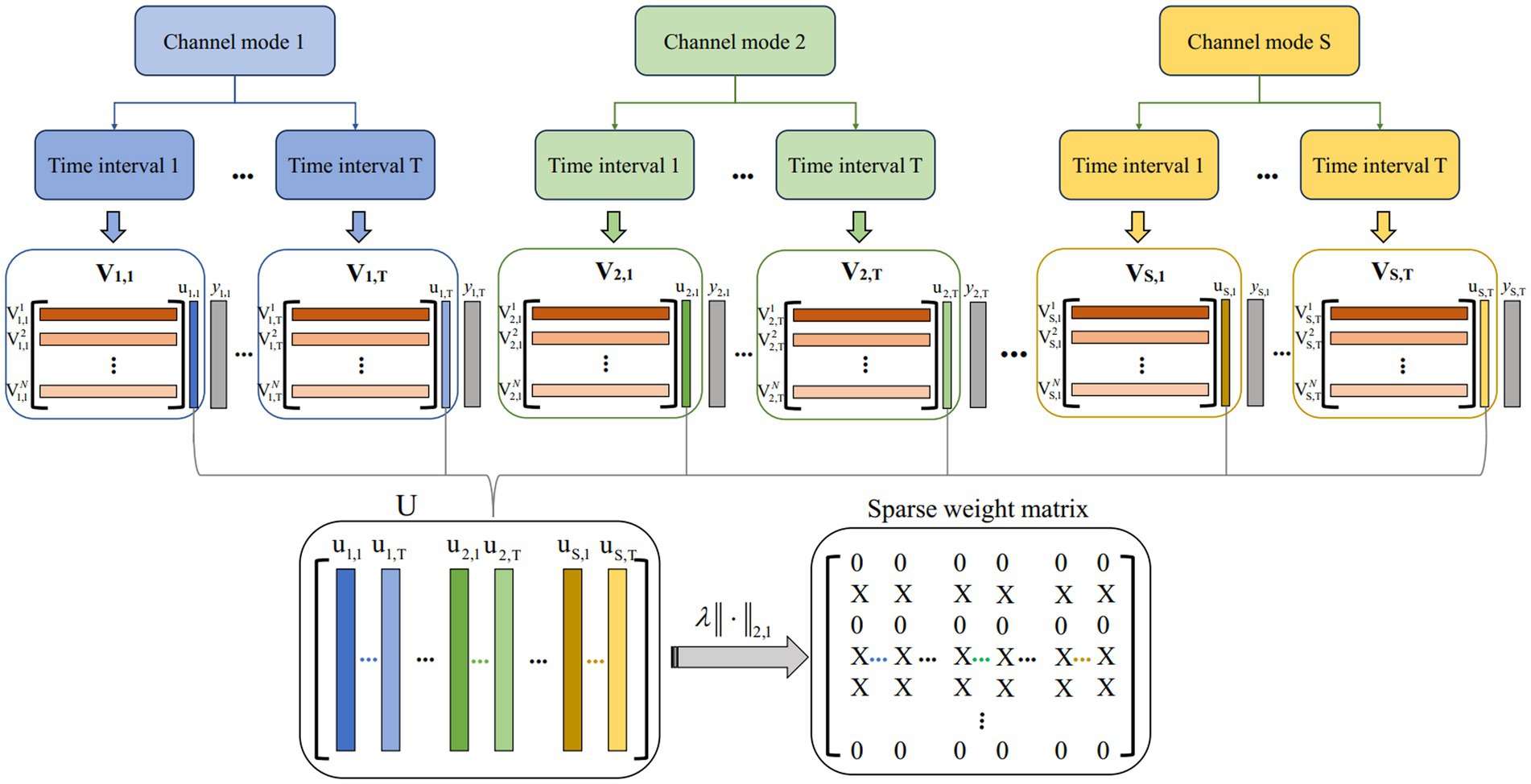
The multi-view model architecture based on L2,1 is shown in Figure 3. Suppose Vs,t∈RN×2mk represents the CSP feature matrix in the t-th time interval over s-th channel mode. The number of filters is m = 1, and k = 17 is the number of sub-bands. N is the total number of trials N = [N1; N2], where N1 is the total number of class 1 trials and N2 is the total number of class 2 trials. The channel mode is s = 1,2,…,S. The number of time intervals t = 1,2,…,T. The proposed multi-view learning model with L2,1-norm regularization is represented as follows:
U=argminU12∑s=1S∑t=1T||Vs,tus,t−ys,t||22+λ||U||2,1 (2)where us,t∈R2mkrepresents the weight vector obtained in a single view with s and t. U=[u1,1,…,u1,T,u2,1,…,u2,T,uS,1,…,uS,T] is weight matrix obtained from all views. ys,t∈RN is denoted as a class label with spatial pattern s-th and time window t-th. It should be noted that since each view in this study shares a common class label vector, the above convex optimization problem could be solved by the accelerated gradient descent method. The MATLAB toolkit “MALSAR” was developed to solve the above convex optimization problem and used the subfunction “mtleastR.m” to solve the above model (Zhou et al., 2011). ‖U‖2,1 is obtained by first computing the L2-norms of the rows us,t and then the L1-norms of vector (||u1||2,||u2||2,…,||uT||2).This encourages some rows of U to be zeros, thereby ensuring that CSP features corresponding to the non-zero rows will be selected across multiple views. Finally, the sparse weight matrix is obtained after the matrix U is regularized by L2,1-norm regularization.
Figure 3. Multi-view model architecture based on L2,1. S and T represent the number of channel mode and time intervals, respectively. Vs,t represents the CSP feature matrix in the t-th time interval over s-th channel mode. U is obtained from all views by a solving model. The sparse weight matrix is obtained after the matrix U is regularized by L2,1-norm regularization.
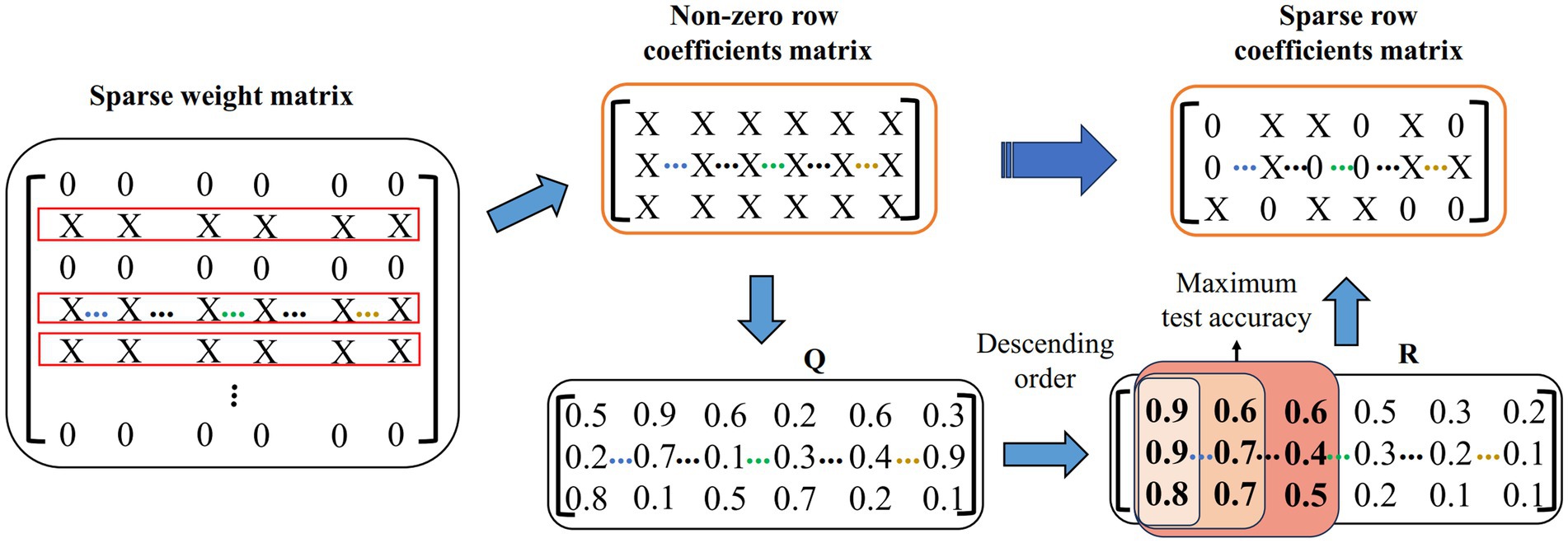
2.3.4 Feature sparsification strategyWe propose a feature sparsification strategy to further reduce the feature dimension. The demonstration of the feature sparsification strategy is shown in Figure 4. First, the non-zero row coefficients are extracted from the sparse weight matrix. Suppose that the matrix of all real values corresponding to X in the non-zero row coefficients is Q. Second, the weight vector of each row in Q is sorted according to the absolute value, forming a matrix R, and then it takes Ns times to calculate the test accuracy by extracting the corresponding feature set with column-by-column superposition. Finally, the corresponding features of the maximum test accuracy are calculated. For example, the features corresponding to the first three columns of coefficients (the red area coefficient in Figure 4) have the highest test accuracy. The sparse row coefficient matrix is obtained by keeping the coefficient corresponding to the maximum test accuracy and other coefficients set to 0.
Figure 4. Feature sparsity strategy demonstration. Q represents the true value of X in a non-zero row coefficient matrix. R means by descending each row in Q.
The feature sparsification strategy will further sparsify the frequency band features on the time scale to reduce redundant information and computational cost. The most discriminative features are selected to improve the classification accuracy.
2.3.5 Implementation steps of the MDFJO methodFigure 5 shows the overall block diagram of the proposed method. The proposed method can be described in detail as follows:
Step (1) The FDC was used for the preprocessing EEG data to rank the channel weights and divide channels into S channel combinations.
Step (2) According to the 5-fold cross-validation method, the EEG signals were divided into five parts, four of which were used as training samples, and the remaining one was used as test samples.
Step (3) For each channel combination mode, the CSP features of EEG signals in k sub-bands are calculated for each time window and the feature matrix Vs,t∈RN×2mk is obtained.
Step (4) The multi-view learning problem is solved by the accelerated gradient descent method to get U, and each non-zero row is sorted according to feature weight value.
Step (5) The optimal CSP feature set is obtained by the feature sparsification strategy.
Step (6) The features selected by all views are collected to train the SVM classifier and identify the class labels of the test samples.
Step (7) Repeat steps 3–6 until the 5-fold cross-validation is complete and output the average accuracy of the 5-fold test samples.
Figure 5. Framework diagram of the proposed MDFJO for the motor-imagery-related EEG classification. The method mainly includes channel pattern division, sub-band division, and time interval division, feature extracted by CSP and feature selection based on multi-view learning, feature sparsification strategy, and identification of test samples by SVM.
Algorithm 1 is the multi-domain feature joint optimization (MDFJO) based on multi-view learning for motor imagery EEG classification.
The methods proposed in this article are compared with the following methods:
1. CSPs (s = 16, 32, and full channels): The CSP algorithm is used for feature extraction in three different channel modes of EEG, respectively. The frequency band was 4–40 Hz, and the time length was 0–4 s for Data 1 and 0–3.5 s for Data 2.
2. FBCSPs (s = 16, 32, and full channels): The time length is the same as CSP, and the sub-frequency bands are divided into 4–8 Hz, 6–10 Hz, 8–12 Hz…,36–40 Hz. CSP features are extracted for the whole-time interval in each sub-frequency band in different spatial patterns, and there is no time interval decomposition in this method. Then, the mutual information-based best individual feature (MIBIF) selection algorithm is used. CSP features of the frequency band are automatically selected. Based on the descending order arrangement of the mutual information value of the whole feature vector, the feature vectors corresponding to the first four sub-frequency bands are selected for subsequent training and testing.
3. SFBCSPs (s = 16, 32, and full channels): The time length and sub-band division are the same as FBCSP, and the Lasso is used for feature optimization in the fixed channel mode.
4. DFBCSP: The time and frequency band divisions are the same as FBCSP, and C3 is used to calculate Fisher’s score on each sub-band. Fisher’s score is sorted in descending order, and the corresponding features of the first four sub-bands are selected for subsequent training and testing.
5. MSO: The channel mode is consistent in Jiao et al. (2020). For the two datasets, the time is 0.5–2.5 s. The sub-band division is consistent with FBCSP. Multi-view learning is used to select the sub-band features in different spatial patterns.
The Wilcoxon signed-rank test is a non-parametric statistical test used to compare the difference between two correlated or paired samples, with the advantage that it does not require the assumption of a normal distribution of the data and is suitable for small samples and discontinuous data. Therefore, the Wilcoxon signed rank test is often used to calculate the differences between two EEG processing methods (Jin J. et al., 2020; Qi et al., 2021). Given the small sample size in this study, the statistical significance of each method versus MDFJO is assessed via the Wilcoxon signed-rank test.
It should be noted that the test results of the comparative methods in this article are based on the principles and parameters of the above methods and are not directly compared with the results of the literature.
2.5 Selection of hyperparametersIn the process of data analysis, several hyperparameters need to be determined. Among them, there are the regularization term sparsity γ in SFBCSP, the regularization term ρ of L2,1 norm in the multi-scale optimization method MSO. In this study, the regularization term λ of L2,1 norm and the number of featured Ns at the time level. In order to construct a better model, 5-fold cross-validation is used to determine the value of the hyperparameter. For each hyperparameter value, the corresponding training feature subsets are divided into five equal parts of which four copies are used to train the classification model, and the remaining one is used as a test set to evaluate the performance of the model. This process is repeated five times, and a 5-fold cross-validation average accuracy is obtained. The optimal value of the hyperparameter is determined for the highest average accuracy. The alternative set of hyperparameters is specified as follows: For SFBCSP, γ∈ . For the MSO, ρ∈ . For the MDFJO, λ∈ and Ns∈ .
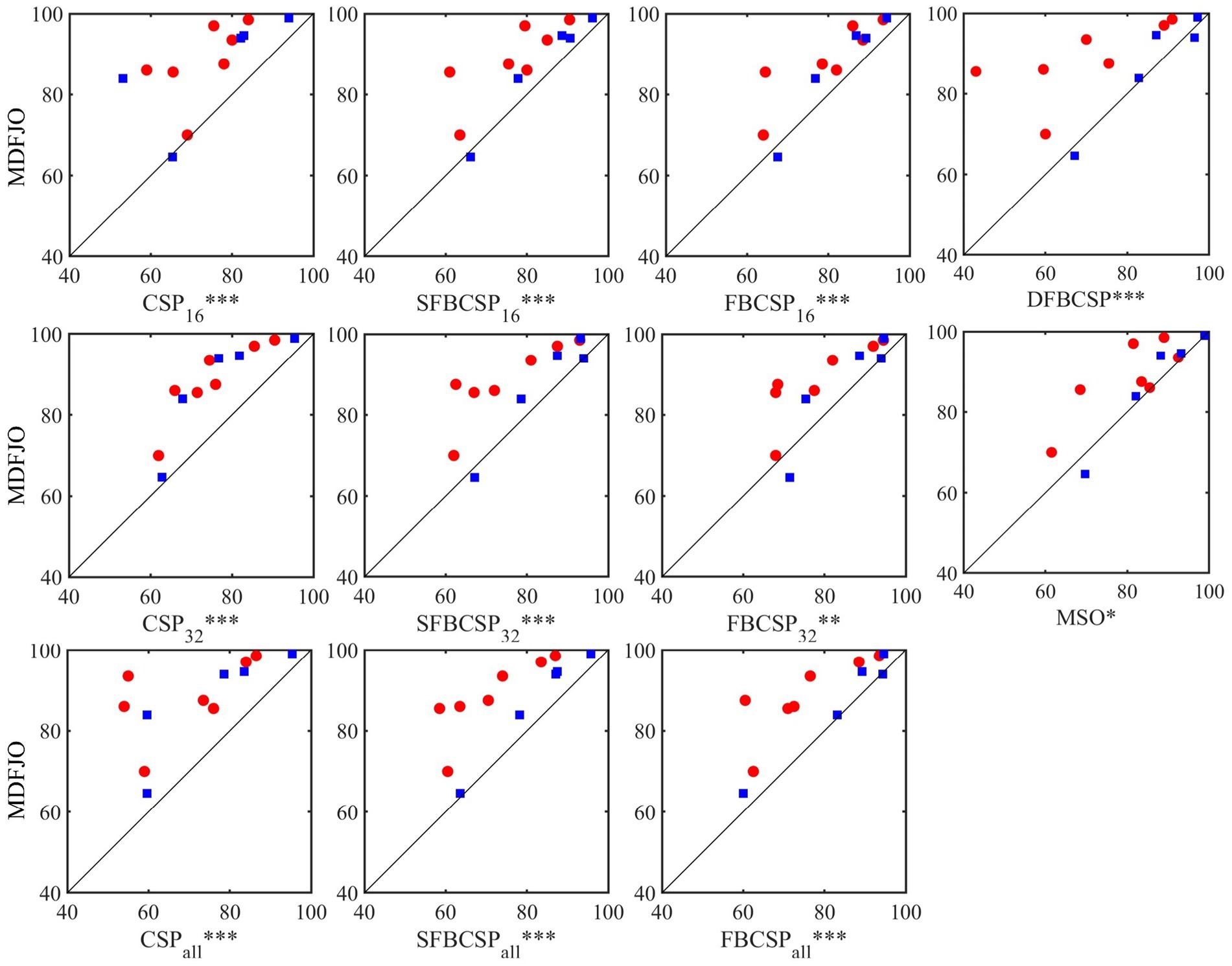
3 Results 3.1 Classification performanceThe results of the proposed method MDFJO are compared with those of the traditional CSP, SFBCSP, FBCSP, DFBCSP, and MSO in different spatial patterns. Figure 6 shows the test results of MDFJO and all comparison methods in all subjects. The red circle and blue box represent the test results of all subjects in Data 1 and all subjects in Data 2, respectively. The results obtained by each method applied to the subjects are the average accuracy of 5-fold cross-validation. The Wilcoxon signed-rank test was used to analyze the statistical differences between MDFJO and each method. Finally, the classification result of MDFJO was significantly better than MSO (p < 0.05), FBCSP32 (p < 0.01), and other methods (p < 0.001). It is concluded that the classification performance of MDFJO is better than other methods.
Figure 6. Test results of MDFJO and all comparison algorithms in all subjects (* p < 0.05, ** denotes p < 0.01, *** denotes p < 0.001). The red circle and the blue box represent the test results of all subjects in Data 1 and all subjects in Data 2, respectively.
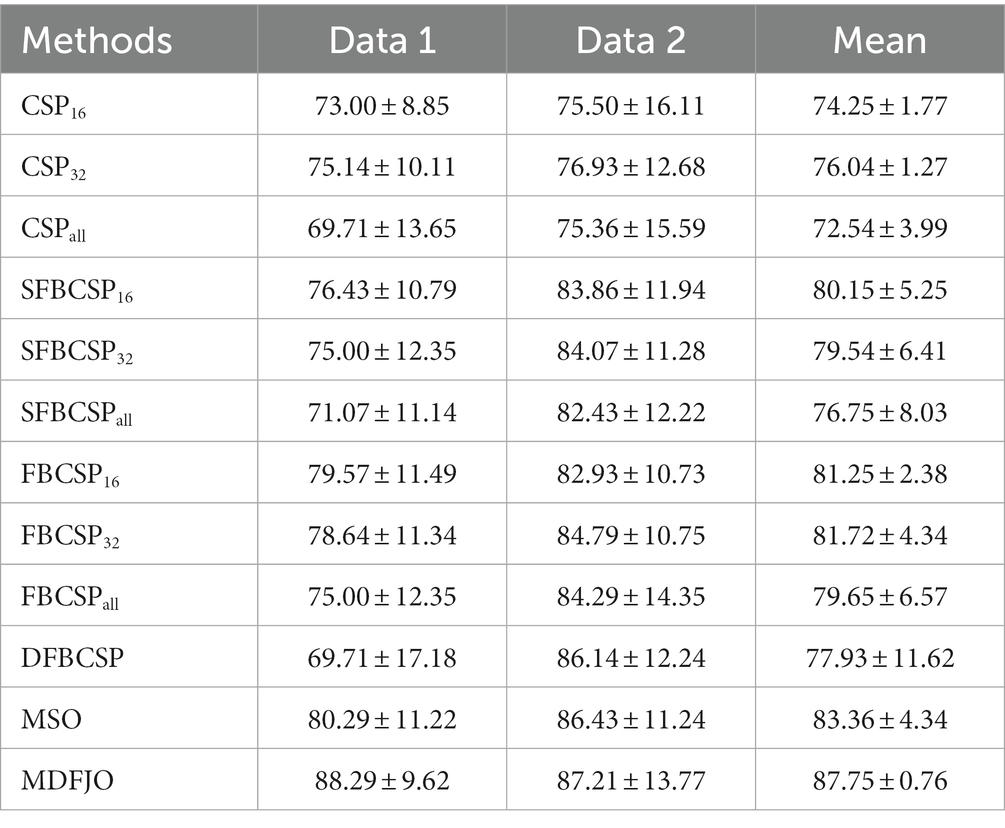
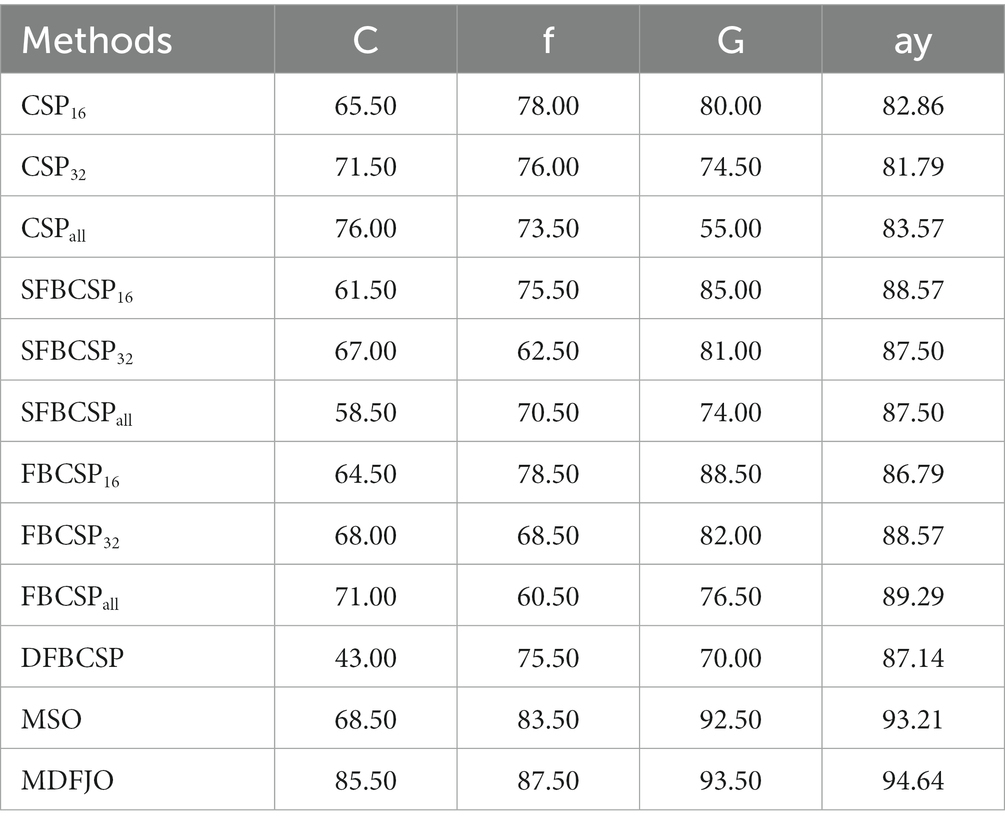
Table 1 shows the average classification accuracy (%) of the proposed MDFJO and the existing methods on each dataset. As can be seen from Table 1, the average classification accuracy of the MDFJO in Data 1 and Data 2 is 88.29 and 87.21%, respectively. For Data 1 and data 2, the average classification accuracy of MDFJO is 87.75%, which was, respectively, higher than that of CSP16, CSP32, CSPall, SFBCSP16, SFBCSP32, SFBCSPall, FBCSP16, FBCSP32, FBCSPall, DFBCSP, and MSO improved by 13.50, 11.71, 15.21, 7.60, 8.21, 11.00, 6.50, 6.03, 8.10, 9.82, and 4.39%. These results indicate that the MDFJO could further improve the accuracy of the EEG classification in a motor imagery task.
Table 1. Average classification accuracy of MDFJO and existing methods on each dataset (%).
Furthermore, it can be concluded from Table 1 that the average accuracy obtained by CSPall, SFBCSPall, and FBCSPall are, respectively, lower than the results obtained by the 16–32 channel mode of the corresponding methods. Specifically, the average test accuracy of CSPall (72.54%) was lower than that of CSP16 and CSP32 (1.71 and 3.50%). For SFBCSPall, the average test accuracy of 76.75% was lower than that of SFBCSP16 and SFBCSP32, which were 3.40 and 2.79%, respectively. For the method FBCSPall, the average test accuracy was 79.65%, which was lower than 1.60 and 2.07% for FBCSP16 and FBCSP32. The results show that channel selection of EEG can effectively improve classification accuracy.
In addition, the average test accuracy obtained by MDFJO on the two datasets is 4.39% higher than that obtained by MSO. One of the possible reasons is that MSO extracts sub-band features from the combined spatial pattern of multiple channels without using multiple time information. Therefore, the MDFJO can further improve the accuracy of motor imagery.
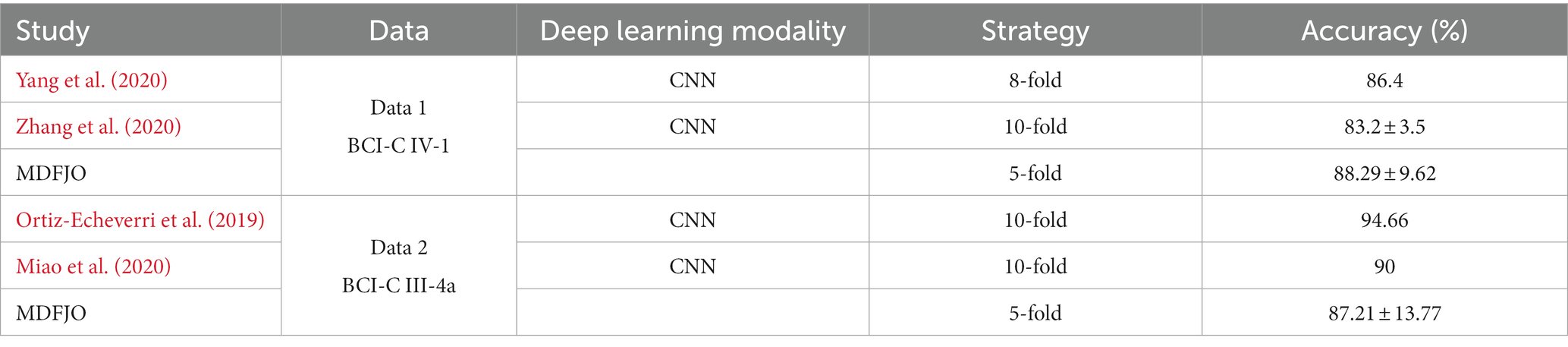
We performed a comparison of the classification performance of MDFJO with convolutional neural networks (CNN), as shown in Table 2. For Data 1 (BCI Competition IV dataset 1), the classification accuracy of our proposed MDFJO is 88.29 ± 9.62%, while the results of Yang et al. (2020) and Zhang et al. (2020) are 86.4 and 83.2 ± 3.5, respectively. For Data 2 (BCI Competition III dataset Iva), as can be seen from Table 2, the classification performance of the proposed method MDFJO is smaller than Miao et al. (2020) and Ortiz-Echeverri et al. (2019). A possible reason is that Data 2 has 118 channels, while Data 1 has 59 channels. Furthermore, Data 2 has 280 trials of the right hand and foot. The convolutional neural network (CNN) method is more suitable for data with a larger sample size and achieves better classification performance. However, the proposed MDFJO is more suitable for classification with a small number of trials for each subject.
Table 2. Comparison of classification accuracy for MDFJO and CNN on each dataset.
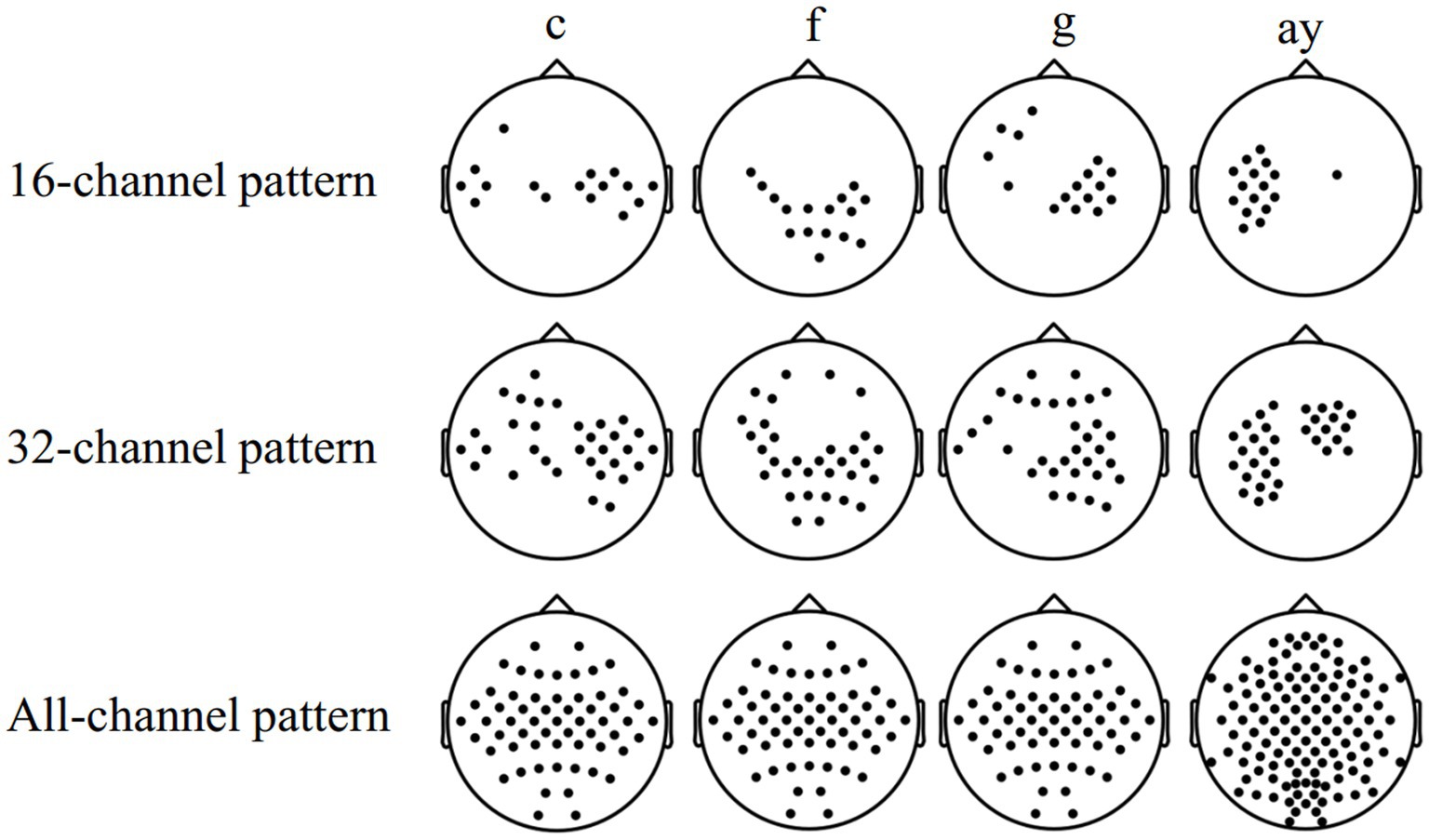
3.2 Combination of selected channelsTable 3 shows the comparison of the average classification accuracy (%) of subjects “c,” “f,” “g,” and “ay” in the MDFJO and the existing method. The 5-fold cross-validation accuracies of the MDFJO in subjects “c,” “f,” “g,” and “ay” are 85.50, 87.50, 93.50, and 94.64%, respectively. The three selected channel patterns obtained by using FDC are shown in Figure 7. For the subjects “c” and “g,” the motor imagery task involved the left and right hand. The chosen 16 and 32 channel patterns are also located in the central zone region of the sensorimotor cortex. Similarly, for subject “f,” the motor imagery task involved the left hand and right foot, and the 16 and 32 channel patterns are mainly distributed in the central and right-center regions of the sensorimotor cortex. For the subject “ay,” the imagery task was the imagination of the right hand and foot, and the two selected channel modes are mainly located in the left-sided region. In summary, the selected channels roughly matched the cortical activation regions generated by the corresponding motor imagery task.
Table 3. Comparison of average classification accuracy (%) of subjects c, f, g, and ay with the proposed method and the existing method.
Figure 7. Three selected channel patterns obtained by using FDC, namely, the 16-32-all channel pattern mode.
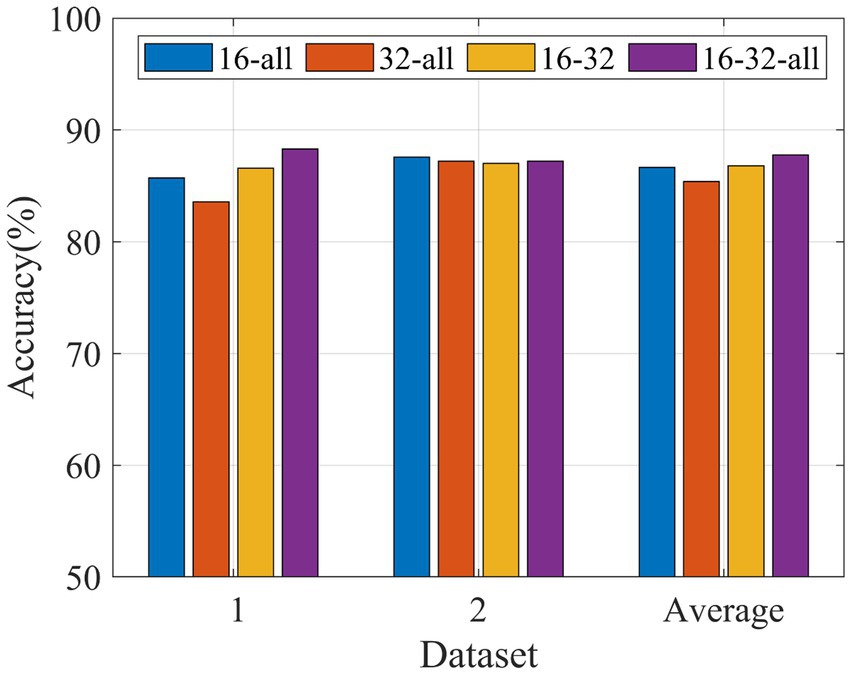
3.3 Results of different channel combination modesIn order to study the classification performance of three different channel combination patterns based on MDFJO on two datasets, a 5-fold cross-validation is performed for each method, as shown in Figure 8. For Data 1, the average test accuracy of MDFJO based on channel mode 16-32-all is much higher than that of other channel mode methods. For Data 2, the MDFJO method of 16-32-all is slightly lower than the channel combination method of 16-all. Although the performance of each channel combination method is different, the average test accuracy of the MDFJO method based on the 16-32-all channel mode is larger than other combined channel modes.
Figure 8. Classification accuracy comparison of MDFJO based on different combinations of channel patterns (16-all, 32-all, 16–32, and 16-32-all).
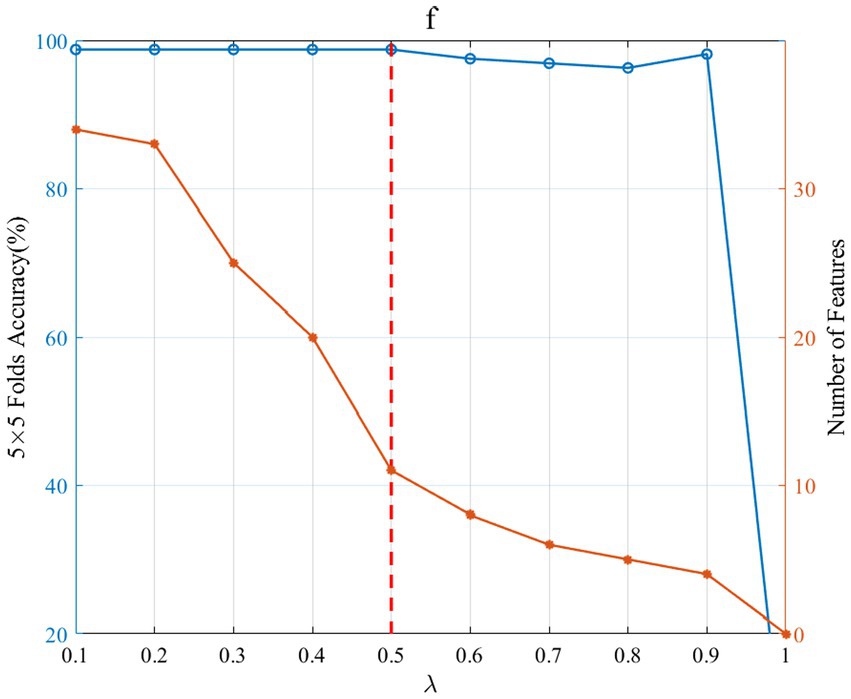
4 Discussion 4.1 Parameter analysisIn the multi-view optimization model, the regularization coefficient λ has a great influence on the feature selection and the 5-fold cross-validation accuracy of the selected features. In this study, we investigated the feature group corresponding to the optimal λ so as to obtain the best test accuracy. Figure 9 shows the effect of λ change on the selection number of sub-band features and the 5-fold cross-validation accuracy. λ controls the number of selected features. Larger λ values result in fewer non-zero rows of the sparse matrix U in (2). A smaller λ value makes the sparse matrix U have more non-zero rows and thus more features. As can be seen from Figure 9, as λ grows, the number of selected sub-band features decreases, and when λ is 1, the number of selected features is 0. Thus, the larger λ value corresponding the higher classification accuracy should be selected as the optimal regular term λ . In this way, the sparsity of feature selection can be maintained without loss of accuracy. For subject “f,” the optimal λ value is 0.5, and the corresponding number of sub-band features is 11.
Figure 9. Effect of λ change on the selection number of sub-band features and the 5-fold cross-validation accuracy. The left blue ordinate is the 5 × 5 fold accuracy (%), and the right orange coordinate is the number of features. The blue curve and the orange curve, respectively, represent the change in 5 × 5 fold accuracy and the number of features. The red vertical dashed line indicates that when λ is 0.5, the accuracy is maximum and the number of features is small.
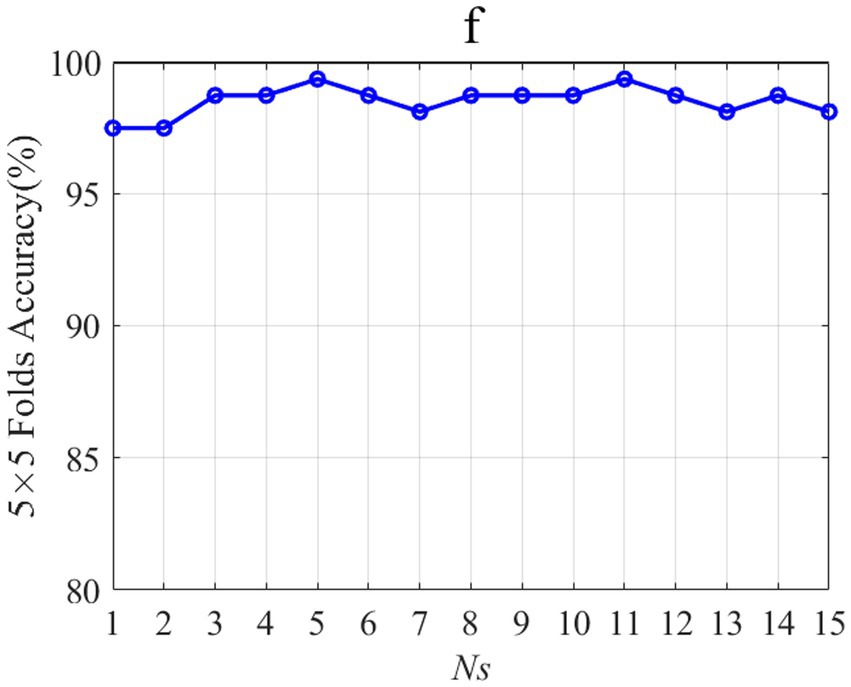
Figure 10 shows the influence of Ns change on the accuracy of 5-fold crossing validation accuracy. Ns is the number of weights on 15-time segments of the three-channel patterns. The feature corresponding to the smaller Ns with the highest average accuracy is considered the optimal feature. When Ns is 5 and 11, the 5-fold crossing validation accuracy is the highest. Considering that when Ns is 5, the selected features are the least, so Ns is 5 for subject “f.” It should be noted that subject “f” is only taken as an example to demonstrate the parameter selection method, and other subjects’ parameter selection methods are the same as subject “f.”
Figure 10. Influence of Ns on the accuracy of 5-fold cross-validation.
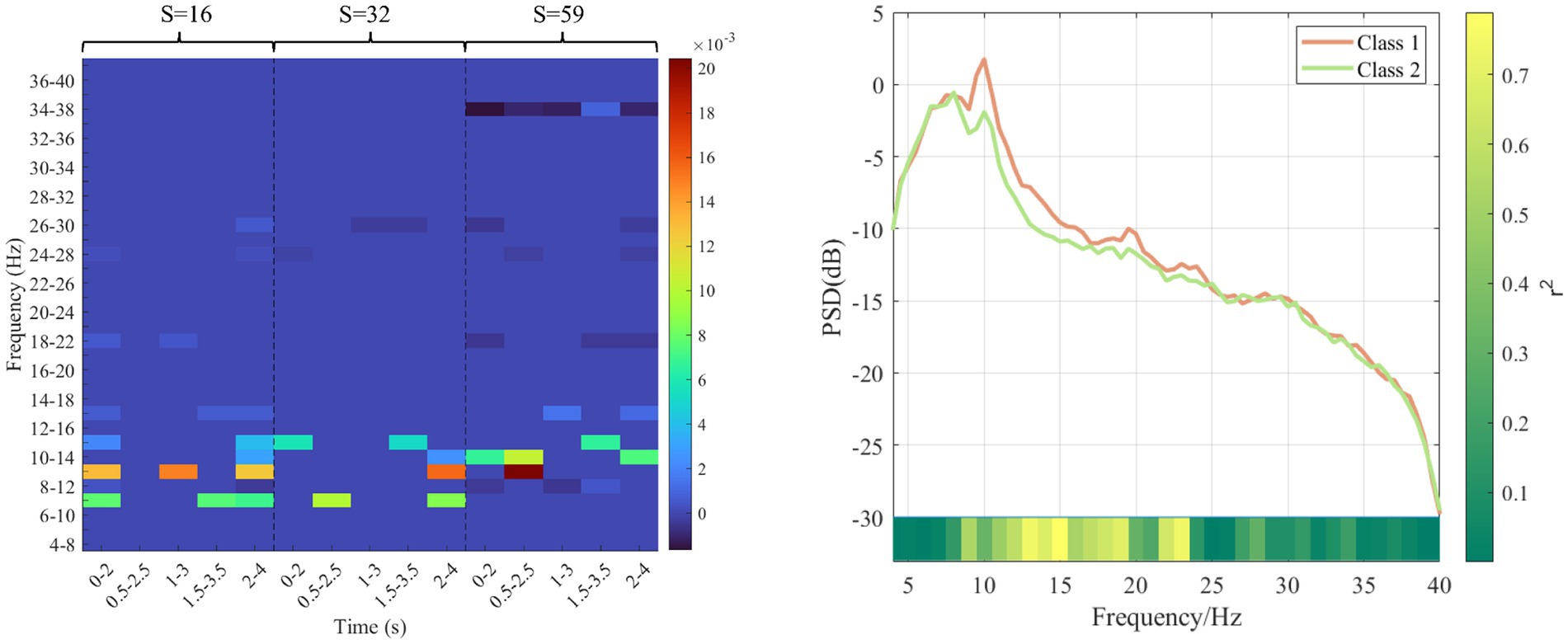
4.2 Analysis of corresponding features of sparse matrixAs for subject “f,” the sparse matrix obtained based on MDFJO is shown in the left subgraph of Figure 11. The highest weight values are mainly concentrated at 6–16 Hz. To verify the effectiveness of the selected sub-band features, the average power spectral density is yielded for the two classes of data of 80 training trials, as shown in the right subgraph of Figure 11. Orange and light green lines represent the average power spectral density curves of the two classes. In this study, r2 is used to represent the difference between the two classes of power. A larger r2 indicates a larger difference between the two classes of power spectrum values. For two classes of power spectrum vectors X1 and X2. The r2 can be expressed as follows:
r2=(L1L2L1+L2mean(X1)−mean(X2)std(X1∪X2))2, (3)where L1 and L2 are, respectively, represented as the dimensions of two classes of power spectrum vectors. The color block at the bottom of the right subgraph of Figure 11 represents the size change of r2. It can be concluded that when the frequency is in the range of 8–20, there is a large difference in the spectral density of the two classes of power, which indirectly indicates the dilution validity of the selected sub-band features in the sparse matrix in Figure 11.
Figure 11. Sparse matrix and average power spectral density of subject f. The left subgraph is a sparse matrix. The darker red color represents a higher weight value. The right subgraph is average power spectral density. Orange and light green lines represent the average power spectral density curves of the two classes. The bottom color bar represents a r2 value.
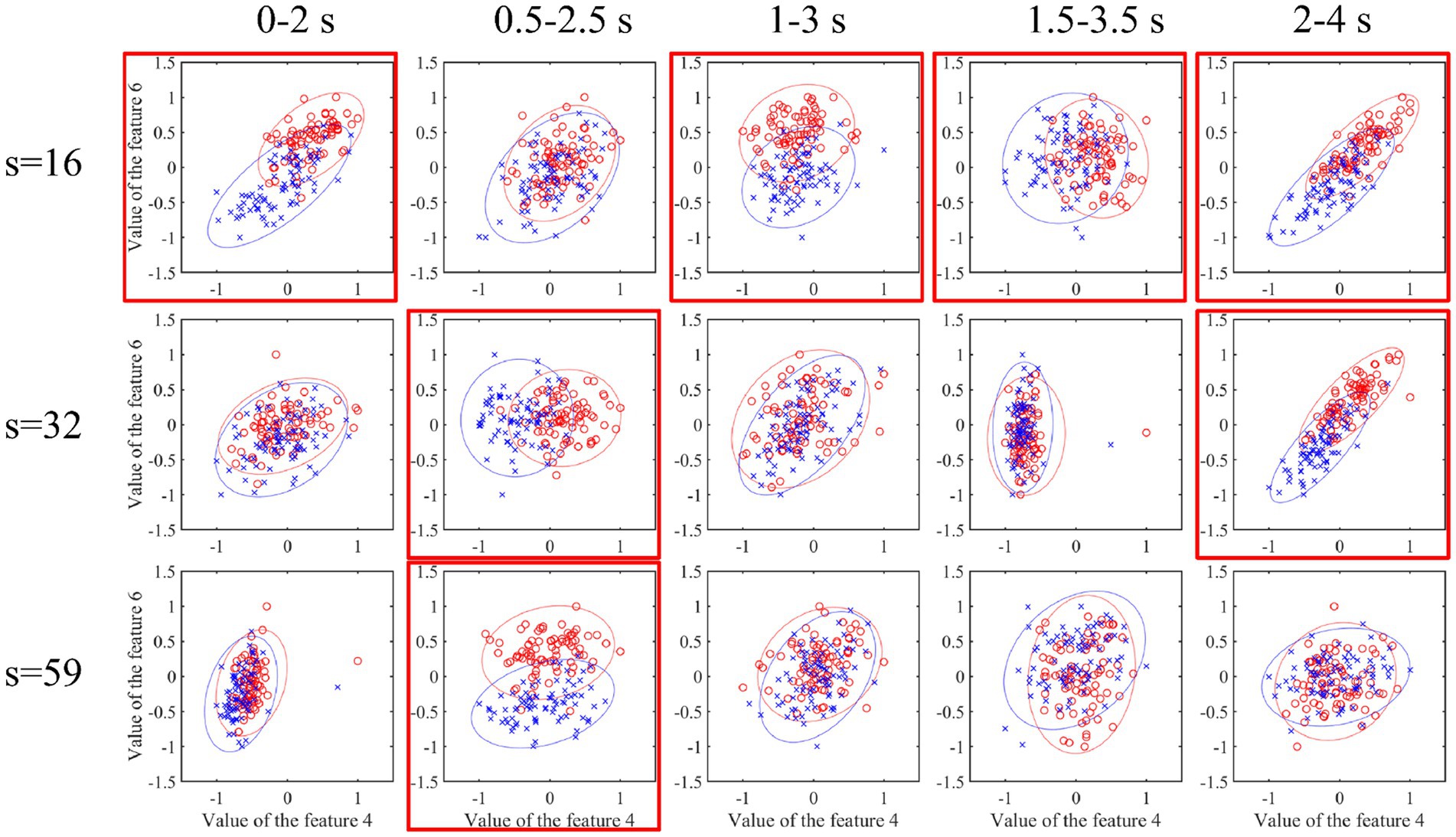
At the same time, this work investigated the differences of the two classes of features corresponding to sub-band indexes 4 and 6 in each spatial pattern in each time interval, as shown in Figure 12. The red-labeled subgraph indicates that the feature difference is greater than other time intervals. The red circle and blue cross indicate two types of features. In addition, it can be seen that the high weight coefficient in the left subgraph of Figure 11 corresponds to the relatively large feature difference in Figure 12. This also shows the effectiveness of optimizing time interval features.
Figure 12. Characteristic difference of each channel mode at each time interval. The red-labeled subgraph indicates that the feature difference is greater than the other time intervals. The red circle and blue cross indicate two types of features.
4.3 Limitations and future workThe proposed MDFJO is mainly suitable for EEG classification based on MI-based BCI. In future studies, we will extend this method to other event-related cortical potential decoding. In addition, only two datasets were used to verify the effectiveness of our method and more datasets will be used to test the effectiveness of this method in the future.
In our experimental study, we use an internal loop cross-validation step to determine the optimal hyperparameters of the proposed method. However, this optimal hyperparameter selection method is generally time-consuming, which would limit the application of the proposed method in BCI practice. The sparse Bayesian learning-based algorithm (Jin Z. et al., 2020) has been developed for automatic optimization of model hyperparameters. Therefore, in future studies, the sparse Bayes algorithm could be embedded into the proposed method to further improve the efficiency of hyperparameter selection.
5 ConclusionIn this study, the feature extraction method of the common spatial pattern is easy to be affected by time interval, bandpass filter, and channel selection. This results in weak feature differences and intention recognition accuracy. Therefore, the multi-domain feature joint optimization (MDFJO) based on the multi-view learning method was proposed. Compared with the CSP, SFBCSP, and FBCSP methods with 16-32-all channel mode as well as MSO, the MDFJO significantly improves the test accuracy. The feature sparsification strategy proposed in this article can effectively enhance classification accuracy. Future studies will investigate the performance of our proposed method on other types of BCI systems.
Data availability statementThe original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Author contributionsBS: Writing – original draft. ZY: Writing – review & editing. SY: Software, Writing – review & editing. JZ: Validation, Writing – review & editing. JW: Writing – review & editing.
FundingThe author(s) declare financial support was received for the research, authorship, and/or publication of this article. This study was supported by the youth fund of the Xi’an Research Institute of High Technology (2022QN-B006). Natural Science Basic Research Program of Shaanxi(Program No.2019JQ-713/S2019-JC-QN-2408).
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
ReferencesAng, K. K., Chin, Z. Y., Wang, C., Guan, C., and Zhang, H. (2012). Filter bank common spatial pattern algorithm on bci competition iv datasets 2a and 2b. Front. Neurosci. 6:39. doi: 10.3389/fnins.2012.00039
CrossRef Full Text | Google Scholar
Ang, K. K., Chin, Z. Y., Zhang, H., and Guan, C. (2008). “Filter bank common spatial pattern (FBCSP) in brain-computer interface” in 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence) (Hong Kong: IEEE), 2390–2397.
Baig, M. Z., Aslam, N., Shum, H. P., and Zhang, L. (2017). Differential evolution algorithm as a tool for optimal feature subset selection in motor imagery EEG. Expert Syst. Appl. 90, 184–195. doi: 10.1016/j.eswa.2017.07.033
CrossRef Full Text | Google Scholar
Bekker, A. J., Shalhon, M., Greenspan, H., and Goldberger, J. (2016). Multi-view probabilistic classification of breast microcalcifications. IEEE Trans. Med. Imaging 35, 645–653. doi: 10.1109/TMI.2015.2488019
PubMed Abstract | CrossRef Full Text | Google Scholar
Benjamin Blankertz, F. L., Krauledat, M., Dornhege, G., Curio, G., and Müller, K.-R. (2008). The Berlin brain-computer interface: accurate performance from first-session in BCI-naïve subjects. IEEE Trans. Biomed. Eng. 55, 2452–2462. doi: 10.1109/TBME.2008.923152
留言 (0)