
記住我
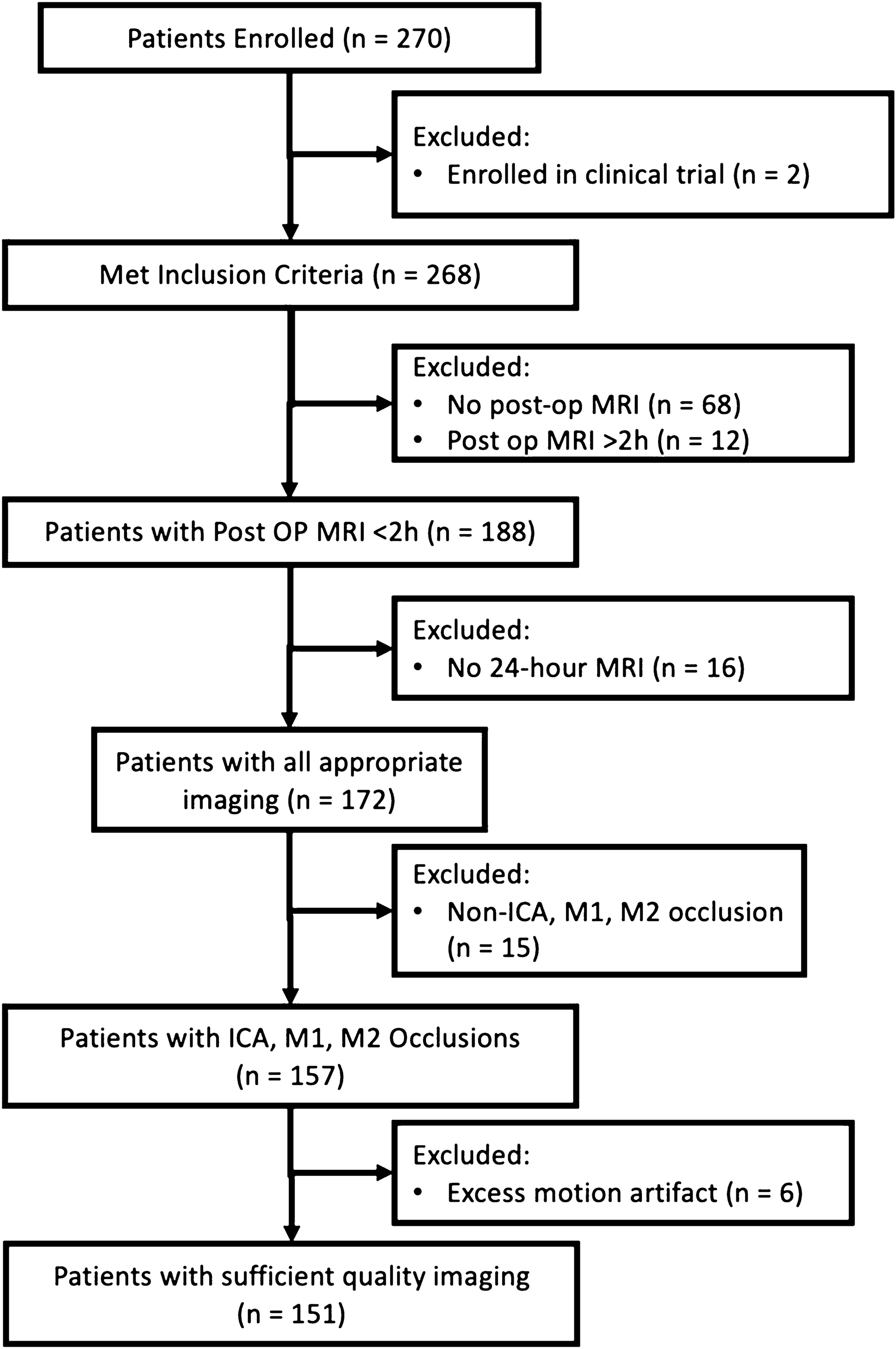
The electronic search yielded 268 hits from PubMed, 496 from EMBASE, and 252 from Web of Science, amounting to a total of 1016 hits (Fig. 1). After removing duplicates, 605 unique articles were identified. After title and abstract review, 576 articles were excluded, and 29 were sought for retrieval of which one could not be retrieved. Of the 28 articles that underwent full-text review, 12 were excluded from further quality assessment because of (1) assessing the quality of already processed (rather than raw) scans (N = 5), (2) relying on visual QC only (N = 3), (3) evaluating previously published algorithms (N = 2), (4) assessing quality of the file structure (N = 1), and (5) assessing quality of other MR sequences (N = 1). Cross-reference searching of the included articles resulted in the identification of eight more articles, of which six underwent full-text review of which four were excluded from further quality assessment due to (1) assessing quality of other MR sequences (N = 2), (2) assessing quality of a file structure (N = 1), and (3) assessing quality of phantom images (N = 1). Ultimately, a total of 18 articles were included [8, 11, 12, 19,20,21,22,23,24,25,26,27,28,29,30,31,32,33]. Relevant information regarding dataset, benchmark, and performance measures is summarized in Table 1. A variety of T1w sequences have been used in the included studies, mostly 3D acquisitions with an inversion recovery spoiled gradient-like protocols (see Supplementary Table 4).
Fig. 1
PRISMA 2020 flow diagram (adapted from: Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ 2021;372:n71. https://doi.org/10.1136/bmj.n71
Risk of bias assessmentAll included articles showed a low concern regarding applicability of the algorithms (Table 2). For 16 articles, the outcome measures of the articles showed a high risk of bias, since the benchmarks are mostly based on a visual QC (Table 1), which can lead to distorted or flawed assessment in the benchmarks. During visual QC, different raters may interpret a protocol in varying ways. Additionally, they may have reacted uniquely to specific scans, causing the resulting score to, to some extent, reflect the raters’ characteristics in addition to solely assessing the quality of the target scan. Examples of factors introducing risk of bias for a visual QC approach are an unclear protocol [11, 22, 26], undisclosed number of raters [11, 20, 26], or QC based solely on the assessment of one rater [8, 24, 30]. Bias in algorithms can rise from unrepresentative or incomplete training data or the reliance on flawed information. Consequently, the analysis of multiple algorithms is susceptible to bias, particularly when a low number of participants [8, 21, 22, 25] was used, potentially resulting in unrepresentative or incomplete training data. Furthermore, the absence of validation [20,21,22, 26,27,28,29, 33] further heightens the risk of bias, as it lacks a safeguard to detect and rectify potential reliance on flawed information within the training data.
Table 2 Risk of bias assessment Rule-based QCA total of ten articles were found that utilized a rule-based approach of one or more quality features to evaluate the quality of structural MRI scans [20,21,22, 24, 26,27,28,29, 32, 33]. Eight articles categorize MRI scans into pass and fail groups [21, 22, 24, 26,27,28, 32, 33], one assessed whether blurring is present [29], and one assessed SNR and ghosting without an overarching score [20]. Five articles [20, 24, 26, 32, 33] evaluated quality features based on the background of the image, arguing that most of the artifactual signal intensities propagate over the image and into the background, which typically corresponds to 40% of the total volume of a structural MRI scan. The other articles [21, 22, 27,28,29] use foreground-based quality features, arguing that relying solely on the background may not provide a reliable measure of the overall image quality.
Rule-based QC using backgroundOne article used quality features stemming from previous studies trying to assess distortion in scans caused by image compression [33]. In order to assess which of these quality features are most applicable for QC of MRI scans, they applied a large set of quality features, classified into seven feature families, to artificially distorted MRI scans (N = 143). They found that quality features based on Natural Scene Statistics were the most effective in distinguishing between artificially distorted and undistorted MRI scans.
Subsequent studies investigated features specific for MR artifacts extracted from the background, such as noise and ghosting artifacts in scans (N = 250) [20]. When these features were compared with white matter SNR and visually assessed ringing artifacts (undisclosed number of raters), very high sensitivity and specificity are found. They determined a QC threshold based on the highest agreement between the features and manual assessment. For the feature assessing ghosting, a validation test was performed, which resulted in similar specificity and sensitivity to the training set.
Subsequent work [26] put forth the argument that SNR measures may not necessarily be sensitive to subject-related artifacts. Instead, they suggest that these artifacts lead to a corrupted noise distribution that can be evaluated using two specific quality features. The first feature assesses the effects of clustered artifacts in the background, and the second feature evaluates both clustered and subtle effects of artifacts in the background (N = 749; undisclosed number of raters). White et al. [32] continued on this work, by calculating the integral of the voxel intensities as vectors radiating away from the head (N = 6662; 1 or 2 raters). This feature was compared with two other new features, which capture the frequency characteristics of the noise rippling away from the edge of the head and utilize properties of the line spread function along the edge of the head. In both these studies, visual quality assessment led to a binary pass or fail score, which was either used to determine the cut of values for the quality features [26] or to assess the performance by determining the area under the curve (AUC) [32]. The feature utilizing the line spread function along the edge of the head was reported to perform best [32].
Finally, the LONI QC System [24] is a publicly available QC algorithm for structural T1w scans based on seven features, namely, SNR, signal variance-to-noise variance ratio (SVNR), contrast-to-noise ratio (CNR), contrast of variance-to-noise ratio (CVNR), brain tissue contrast-to-tissue intensity variation (TCTV), full-width-at-half-maximum (FWHM), and center of mass (CoM). In this algorithm, the image background is used to represent noise. To assess the manual binary classification (one rater) accuracy of each QC feature, the values per feature were changed to a z-score, and a threshold was determined based on agreement with visual QC.
Rule-based QC using foregroundJang et al. [22] argue that not all MRI scans allow for capturing background noise, e.g., when the background area is insufficient to allow a robust analysis. They introduced the Quality Evaluation using MultiDirectional filters for MRI (QEMDIM) algorithm, which uses multidirectional filters to capture quality features. Each image is divided into 16 patches with 20 quality features, which were averaged over the patches. Image quality is determined by calculating the absolute difference between the averaged quality features of the test image and those of a benchmark of undistorted images, using the agreement with visual scores as the threshold. Others [21] later modified QEMDIM such that it does not only provide the absolute quality difference but also if the assessed scan has a higher or lower quality than the benchmark. Additionally, calculation efficiency was improved by omitting patch division and feature averaging. Then, they revalidated the modified QEMDIM score with a visual quality score.
Osadebey et al. [27,28,29] developed three algorithms to assess MRI scan quality, using foreground features. One algorithm [27] calculates a total quality score as a weighted sum of noise, lightness, contrast, sharpness, and texture details. In a second algorithm [28], three geospatial local entropy features are being extracted from all the slices of MRI scans. In both these algorithms, it was shown that undistorted images have higher quality scores than artificially degraded images. In a more recent study [29], the authors used an average of a sharpness and a contrast quality feature; which also performed good in comparison to a visual rating scale.
Classical machine learningThree studies applied classical machine learning approaches [11, 12, 30], which all classify MRI scans into either pass or fail by training them against visual QC results. Quality features based on the background and the foreground of the image have been used.
Pizarro et al. [30] investigated multi-dimensional, non-linear classification to overcome limitations of univariate approaches, including the need for multiple quality features to characterize artifacts from different sources, since a single quality feature has a limited ability to capture details of artifacts in small local regions and cannot capture sufficient information on artifact type and location. Six different features were extracted: three volumetric features (related to contrast, intensity, and tissue class) and three artifact-specific features (related to eye movement, ringing, and aliasing). The MRI scans (N = 1457) are also visually assessed and classified in either pass or fail by five to nine raters. The features and the visual assessment were fed to a supervised classification algorithm based on a support vector machine (SVM), which was trained with a tenfold cross-validation.
The UK Biobank developed a QC algorithm to assess the quality of their own dataset only [11]. A classical machine learning approach was proposed to automatically identify problematic scans based on 190 image-derived features. These features are derived from both raw images as well as from derivatives after preprocessing. A Weka machine learning toolbox was used, with three separate classifier’s outputs fused together, and a voting system combining the a posteriori probabilities of the three classifiers was used for the fusion. To train this QC algorithm, the quality of the first release of the Biobank MRI scans (N = 5816) was assessed manually (number of raters unknown). For training, a stratified tenfold cross-validation was used. To test the algorithm, the second release of the Biobank was used, which was not manually labeled, and therefore, no performance measures could be derived.
Esteban et al. [12] developed MRIQC, a publicly available algorithm which extracts 64 image quality features and fits a binary classifier. The features are based on background evaluation of the raw MRI scan only. A supervised classification framework was used, composed of a random forest classifier (RFC), with a Leave-one-Site-out splitting for cross-validation, where a whole site is left out as a test set at each cross-validation fold. The quality of all MR volumes (N = 1102) was first manually assessed by two raters, and they were given a label of “exclude,” “doubtful,” or “accept.” For the binary classifier, pass consisted of the scans with an “accept” and “doubtful” label, whereas fail was composed of all manually “excluded” MRI scans.
Deep learningFive studies utilized a deep learning approach [8, 19, 23, 25, 31], of three of which classify the MRI scans as either pass or fail [19, 23, 31] and the remaining two [8, 25] assess whether or not motion is present in the assessed scans.
The first article investigating the feasibility of automated detection and assessment of motion artifacts in MRI scans with a convolutional neural network (CNN) was published by Küstner and colleagues [25]. The input of the CNN was a patched image; it was also investigated which patch size was the best. For training and validation, MRI scans from 16 healthy volunteers were used. Each volunteer was scanned twice, and during the first acquisitions, the volunteers were instructed to hold their head still. During the second acquisition, volunteers were instructed to deliberately tilt their head side-to-side. For training and evaluation, a leave-one-out cross-validation approach was used. This CNN was able to localize and detect motion artifacts. Furthermore, it was shown that patch-based accuracy of detecting motion artifacts declined with decreasing patch size.
Fantini et al. [8] continued on the work of Küstner et al. [25], by including scans with more complex motion distortions (N = 203). Furthermore, they also investigated the performance of four different networks, namely, Xception, InceptionV3, ResNet50, and Inception-Resnet, and applied transfer learning by pretraining the networks on the Imagenet dataset. One model was trained for each standard MR orientation (axial, coronal, and sagittal axes) on patches, and an artificial neural network was used to combine the outputs of the different networks to one output value. Also, a depth search was performed, attaching the binary classifier on distinct block output, and the best architecture depth was selected from the block layer that reported the best accuracy. A threefold cross-validation approach was used for the training of all architectures.
Sujit et al. [31] aimed to develop an algorithm that would evaluate the image quality of 3D T1w MRI scans using data from a large multicenter database (N = 1064) which were classified by two raters. Their deep learning network was inspired by the VGG16 network, and one model was trained for each standard MR orientation (axial, coronal, and sagittal axes), and the output layer provided a slice-wise quality score. A second network consisting of a fully connected layer and an output layer was used to combine all the slice scores into one “volumetric” quality score. It was shown that this model provided good accuracy for classifying brain MRI scan quality.
Bottani and colleagues [19] developed an algorithm for automatic QC of MRI scans in a large clinical data warehouse (N = 3770) which were rated by two raters. They aimed to discard scans which are not proper T1w brain MRI, identify scans with gadolinium, and recognize scans of bad, medium, and good quality. For the purpose of this paper, we will focus on the last two aims. MRI scans were classified into three tiers, i.e., good quality, medium quality, and bad quality. For the classification between bad vs medium/good and medium vs good, two separate networks were trained. It was trained using the cross entropy loss, which was weighted according to the proportion of scans per class for each task.
Another approach was used by Keshavan et al. [23] in which citizen scientists were used to visually QC MRI scans in order to acquire a large labeled dataset (N = 200) which in turn can be used to train deep learning networks for automatic QC
留言 (0)